







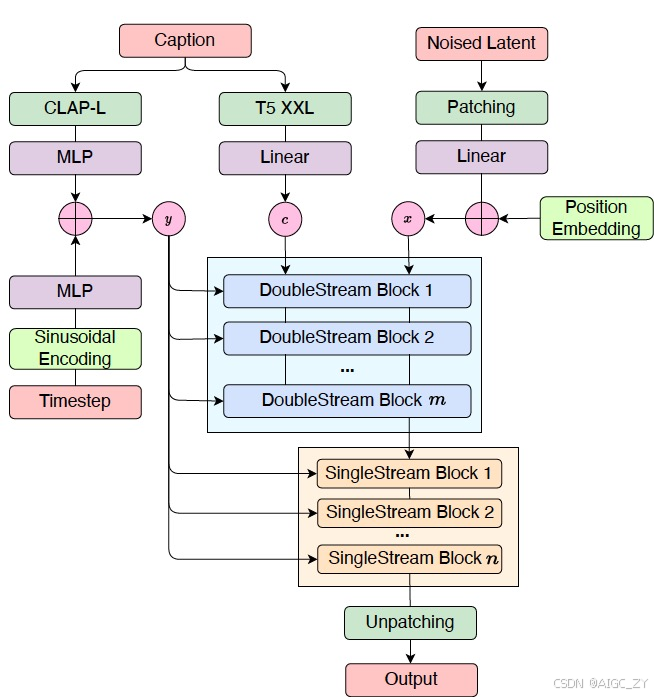
文本和图片模态的结合:Flux 利用预训练的文本编码器(如T5-XXL 和CLIP-L)提取文本的粗粒度和细粒度特征,将这些文本特征与 图片特征结合。粗粒度的文本信息用于调制生成过程,细粒度的文本特征与图片补丁序列一起作为输入,用于图片生成。
双流和单流结构:
MM-DiT采用独立的权重分支分别处理图像块(Patch)和文本标记(Token),并在注意力层中实现双向交互。
接着,模型进入单流阶段,文本流被移除,仅保留图片流用于生成过程中的噪声预测。
潜在空间的噪声预测:模型在潜在的VAE空间中进行噪声预测,通过训练模型在从噪声到数据的转换路径中进行预测。校正流(Rectified Flow)方法使得数据和噪声之间沿着线性路径连接,从而提高生成效率和模型性能。

















 1180
1180

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









