







ZeRO分布式训练策略详解
一、核心设计原理
ZeRO(Zero Redundancy Optimizer)是微软提出的分布式训练优化框架,与传统数据并行方法不同,ZeRO通过将模型的参数、梯度和优化器状态分散到多个设备上,从而实现内存和计算资源的高效利用。
ZeRO通过三级分片策略消除内存冗余,实现超大规模模型训练。其核心演进路线分为三个阶段:
1.1 ZeRO-1:优化器状态分片
- 分片对象:优化器参数(如Adam的动量、方差)
- 显存优化:显存占用降低4倍(N=4 GPU时)
- 通信机制:反向传播后执行All-Reduce同步梯度
- 适用场景:混合精度训练场景下的Adam优化器
1.2 ZeRO-2:优化器状态+梯度分片
- 分片对象:梯度张量(Gradients)
- 显存优化:显存占用再降2倍(总降低8倍)
- 通信优化:梯度聚合后立即释放内存
- 技术优势:保留数据并行的通信效率
1.3 ZeRO-3:优化器状态、梯度和模型权重参数分片
- 分片对象:模型权重(Parameters)
- 显存优化:显存消耗与GPU数量成反比
- 通信开销:引入参数广播(All-Gather)操作
- 工程实践:DeepSeek采用动态分片策略,结合专家并行与流水线并行降低26%跨节点通信
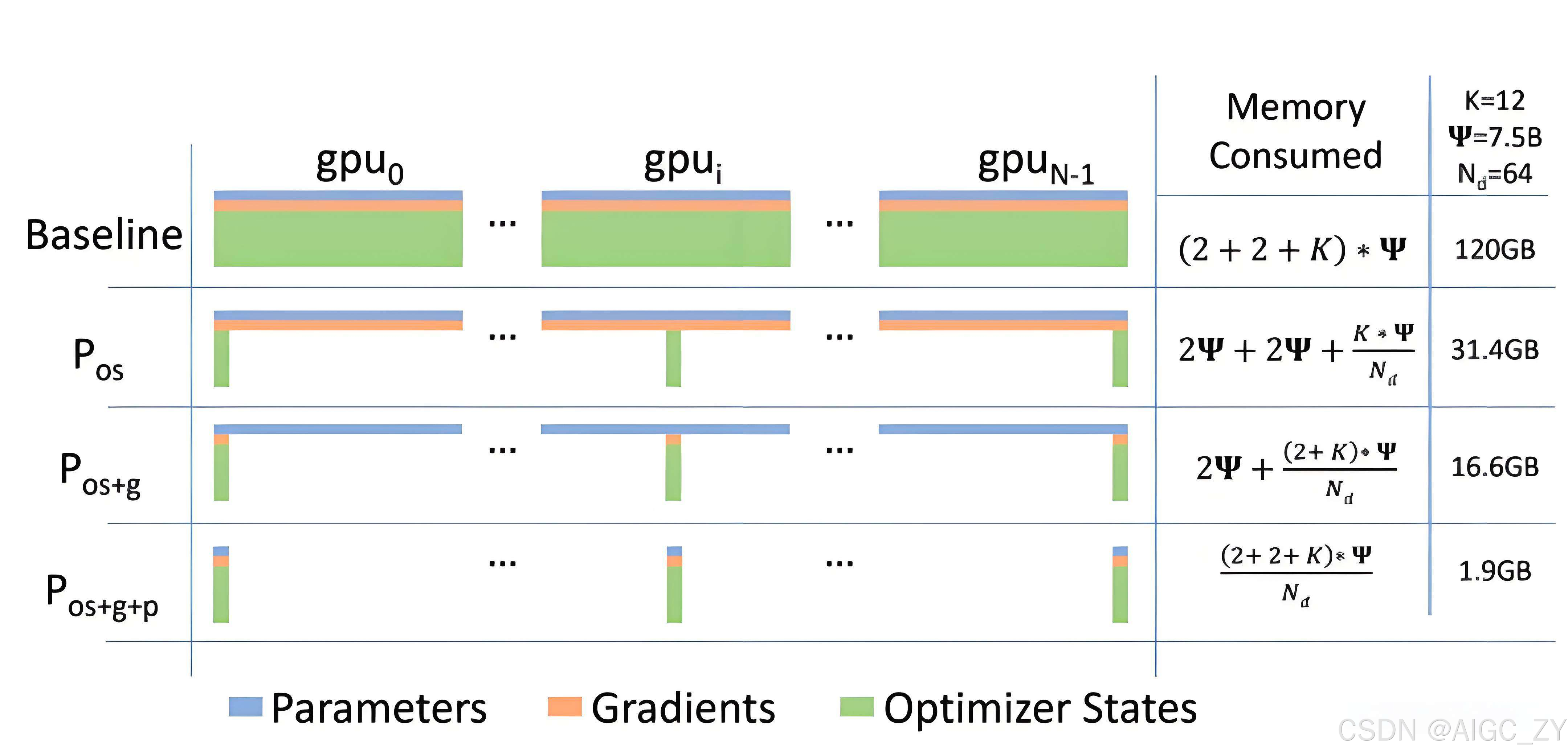
- 传统数据并行在每个设备上复制模型的完整副本,然后同步梯度更新,但对于大模型的训练,内存和通信效率较低。
- ZeRO通过分散存储模型参数、梯度和优化器状态,减少冗余并提升内存和通信效率,适用于训练更大的模型,尤其在大
规模分布式训练中表现优越。
二、关键技术演进
| 技术分支 | 核心创新 | 显存突破 | 典型应用 |
|---|---|---|---|
| ZeRO-Offload | CPU内存卸载技术 | 突破单机显存限制 | 千亿参数级模型训练 |
| ZeRO-Infinity | NVMe存储扩展 | 支持万亿参数模型 | 超大规模LLM训练 |
| 混合分片策略 | EP+PP协同切分 | 节点内通信延迟3.2ms | DeepSeek人脸识别模型 |
三、性能优势对比
# 显存占用计算公式(N为GPU数量)
def memory_saving(stage):
if stage == 1: return "4x"
elif stage == 2: return "8x"
elif stage == 3: return "O(1/N)"
核心优势矩阵
| 优势维度 | 技术实现 | 性能指标与突破 | 典型应用场景 | 相关技术支撑[^来源] |
|---|---|---|---|---|
| ✅ 显存效率 | 三级分片策略(参数/梯度/优化器状态分区) | 显存消耗与GPU数量成反比(64卡时显存降低64倍) | 千亿参数级LLM全量微调 | ZeRO-3 + NVMe卸载 |
| ⚡ 计算效率 | 保留数据并行计算粒度,动态调度通信 | H800集群计算利用率达91% | 多模态大模型混合精度训练 | 混合精度+梯度累积 |
| 🌐 扩展能力 | 参数动态预取与异步通信 | 支持2048卡集群训练(万亿参数模型) | 跨数据中心分布式训练 | ZeRO-Infinity |
| 🔄 通信优化 | 分层拓扑通信(节点内SHARP协议+跨节点量化传输) | InfiniBand网络带宽利用率达1.2TB/s | 类ChatGPT模型参数同步 | ZeRO++量化算法 |
| 🛡️ 容错机制 | 冗余检查点保存策略(每1000步全量保存) | 断点恢复时间缩短72% | 长周期训练任务容灾 | 动态分片恢复 |
关键技术支撑说明
-
三级分片策略
- ZeRO-1:优化器状态分片(4倍显存降低)
- ZeRO-2:梯度分片(总显存降低8倍)
- ZeRO-3:参数分片(线性显存扩展)
-
通信优化技术
# ZeRO++量化通信示例(网页10核心算法) def quantized_sync(gradients): quantized = int8_quantize(gradients) # 梯度8bit量化 error = gradients - dequantize(quantized) # 误差计算 return quantized, error # 仅传输量化结果
3.对比传统方法
▸ 数据并行:显存冗余高但通信量小
▸ 模型并行:显存占用低但计算效率差
▸ ZeRO:在两者间取得平衡,成为当前大模型训练的主流方案
相关资料
图解大模型分布式训练:ZeRO系列方法
图解大模型分布式训练:张量并行Megatron-LM方法
DeepSeek技术解密(3/6):分布式训练方案的工程艺术
DeepSpeed介绍

















 1117
1117

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









