






(小白0基础) 微调deepseek-8b模型参数详解以及全流程——训练篇-优快云博客
1. 下载Xshell,XFTP免费版本
xftp用来进行文件传输的,下载好之后,填写用户名邮箱就可以正常用了
进入xshell,新建
复制登录指令
注意:
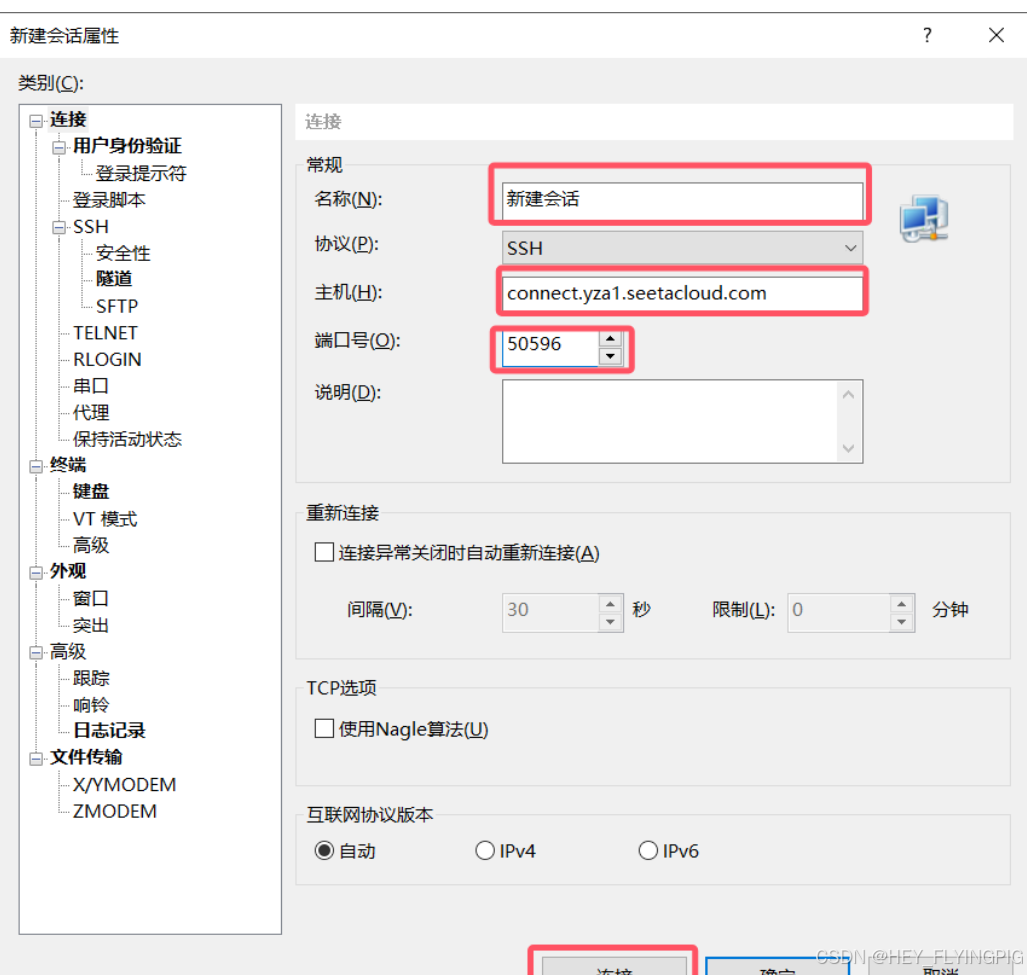
1. 这里名称随便填
2. 协议SSH
3. 填root后的东西(即加黑的那一部分) ssh -p xxxx root@connect.nmb.seetacloud.com
即:connect.nmb.seetacloud.com
4. 端口填指令中的端口,即ssh -p xxxx root的xxxx
5. 登录用户填root,密码复制
2. 租用服务器
本文详细讲述了我从AutoDL上租用服务器并在服务器上微调deepseek全流程
AutoDL算力云 | 弹性、好用、省钱。租GPU就上AutoDL
购买3090 24G服务器,哪一个都行
选择基础镜像,这里选择3.10避免不必要的版本问题。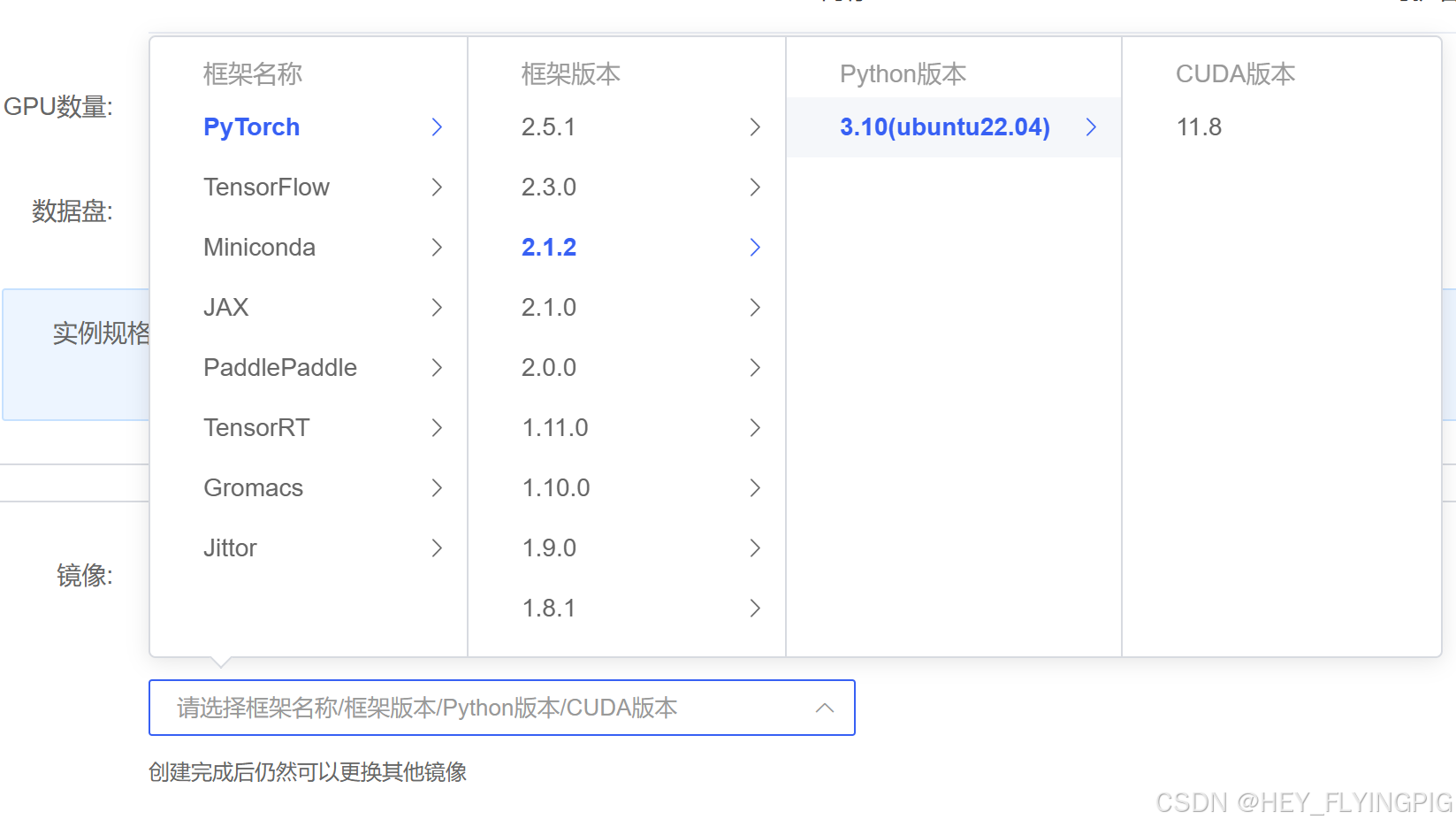
创建完开机即可,不过建议把所有准备工作做完再开机
连接服务器后进入界面

这里说明了需要把大文件写入数据盘
我们进入系统盘
![]()
在这里下载deepseek8b文件
查阅官方文档
使用学术文档加速
source /etc/network_turbo不过我的就是没有加速成功,该地区不支持
取消学术加速
unset http_proxy && unset https_proxy下载模型文件
下面提供两种方法进行下载
1. 方法一(土豪版)
直接在服务器上下载
首先确认是否安装LFS(下载大文件)
然后再进行clone
# 安装 Git LFS
sudo apt-get update
sudo apt-get install git-lfs -y
git lfs install
进行git clone
git clone https://hf-mirror.com/deepseek-ai/DeepSeek-R1-Distill-Llama-8B等待下载,如果发现很快就下完了,那就是只下载了索引,没有下载文件
重新拉取
git lfs pull
等待下载
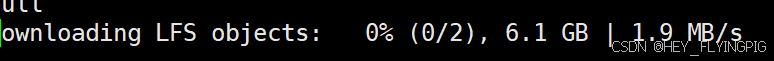
2. 方法二(平民版)
现在本地下载,再进行网盘下载(不过现在阿里云盘需要充钱了10/月)
首先在本地下载模型
选择一个本地文件夹,打开右键终端
首先确认是否安装LFS(下载大文件)
然后再进行clone
# 安装 Git LFS
sudo apt-get update
sudo apt-get install git-lfs -y
git lfs install
进行git clone
git clone https://hf-mirror.com/deepseek-ai/DeepSeek-R1-Distill-Llama-8B等待下载,如果发现很快就下完了,那就是只下载了索引,没有下载文件
重新拉取
git lfs pull
等待下载即可,下载完之后,进行压缩
打开阿里云盘注册下之后,把压缩包上传到阿里云文件夹
具体操作看这个教程
3. 下载的问题重现
由于遇到了网络问题,导致下载中断,所以我不得不重新下载文件。但是重新下载的时候发现下载的文件大小远远超过仓库的文件大小,所以怀疑是不是git没有成功识别断点
首先打开XFTP
进入/root/autodl-tmp/文件夹
右上角查看隐藏的文件
找到git文件,进入\git\lfs\incomplete 看到是否有多余的文件,直接删除
回到xshell,输入下列文件,看看大文件有没有下载成功
git lfs ls-files
有-号代表没有下载成功,重新运行git lfs install,如果发现xshell没有进度条显示,我们打开xftp,进入\git\lfs\tmp,观察文件大小是否增加即可
4. 注册wandb,用于训练可视化
Weights & Biases: AI開発者のためのプラットフォーム
注册之后进入我的-复制密匙即可
5. 下载训练数据集
FreedomIntelligence/医疗-o1-推理-SFT 在主分支 --- FreedomIntelligence/medical-o1-reasoning-SFT at main
将所有文件下载到本地保存
打开xftp,将本地文件拖进/root/autodl-tmp/DeepSeek-dataset

6. 测试是否加载成功
打开jupyter
以下参考如何在本地微调DeepSeek-R1-8b模型_哔哩哔哩_bilibili
!pip install unsloth
# Also get the latest nightly Unsloth!
!pip install --force-reinstall --no-cache-dir --no-deps git+https://github.com/unslothai/unsloth.git
from unsloth import FastLanguageModel
import torch
max_seq_length = 2048 #这里指的是处理上下文最大的长度
dtype = None #这里指的是处理数据类型的精度
load_in_4bit = True # 这里是进行4bit的量化减少内存损耗
!pip install wandb
import wandb
wandb.login(key="填写密匙")
run = wandb.init(
project='my fint-tune on deepseek r1 8b',
job_type="training",
anonymous="allow"
)
model, tokenizer = FastLanguageModel.from_pretrained(
model_name = "/root/autodl-tmp/DeepSeek-R1-Distill-Llama-8B", # 这里填写服务器上的地址
max_seq_length = max_seq_length,
dtype = dtype,
load_in_4bit = load_in_4bit,
)填写提示词
prompt_style = """Below is an instruction that describes a task, paired with an input that provides further context.
Write a response that appropriately completes the request.
Before answering, think carefully about the question and create a step-by-step chain of thoughts to ensure a logical and accurate response.
### Instruction:
You are a medical expert with advanced knowledge in clinical reasoning, diagnostics, and treatment planning.
Please answer the following medical question.
### Question:
{}
### Response:
<think>{}"""这里是进行模型输出
question = "A 61-year-old woman with a long history of involuntary urine loss during activities like coughing or sneezing but no leakage at night undergoes a gynecological exam and Q-tip test. Based on these findings, what would cystometry most likely reveal about her residual volume and detrusor contractions?"
FastLanguageModel.for_inference(model) # Unsloth has 2x faster inference!
inputs = tokenizer([prompt_style.format(question, "")], return_tensors="pt").to("cuda") # return_tensors="pt"返回 PyTorch 张量格式。
outputs = model.generate(
input_ids=inputs.input_ids,
attention_mask=inputs.attention_mask,
max_new_tokens=1200,
use_cache=True,
)
response = tokenizer.batch_decode(outputs) #将生成的 token IDs 解码为文本。
print(response[0].split("### Response:")[1]) # 按照### Response: 分隔看到有输出即代表成功
<未完待续>

















 6475
6475

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









