







torch.unsqueeze()将一维数据变为二维数据,torch只能处理二维数据
tensor不能反向,variable可以反向。variable.data.numpy()转换为numpy
第3章 神经网络
- 实现softmax函数时的注意事项:为防止e的指数运算造成溢出



矩阵的第 0 维是列方向,第 1 维是行方向
第4章 神经网络的学习
损失函数:
均方误差,用于回归问题

交叉熵误差,用于分类问题

求所有训练数据的损失函数的总和,以交叉熵误差为例,可以写成

数值微分:利用微小的差分求导数的过程称为数值微分。所谓数值微分就是用数值方法近似求解函数的导数的过程。
梯度法:在梯度法中,函数的取值从当前位置沿着梯度方向前进一定距离,然后在新的地方重新求梯度,再沿着新梯度方向前进, 如此反复,不断地沿梯度方向前进。像这样,通过不断地沿梯度方向前进, 逐渐减小函数值的过程就是梯度法。
学习率决定在一次学习中,应该学习多少,以及在多大程度上更新参数


第5章 误差反向传播法
计算图用图形表示计算过程,从左向右计算
实际上,使用计算图最大的原因是,可以通过反向传播高效计算导数。即计算输入变量对最终输出的影响。
Affine层:Affine 层的核心功能是进行仿射变换。从数学角度看,仿射变换是指对输入向量 x 执行线性变换(与权重矩阵 W 相乘),然后加上偏置向量 b,其数学表达式如下:y=Wx+b,其中,x 是输入向量,W 是权重矩阵,b 是偏置向量,y 是输出向量。
ReLU(Rectified Linear Unit)层:是深度学习中常用的激活函数层,它在神经网络里发挥着关键作用,能够为网络引入非线性特性,提升网络的表达能力。ReLU 函数的数学表达式为:(f(x) = max(0, x)
反向传播算法:Backpropagation Algorithm,建成BP算法,通过梯度下降等优化算法来更新参数,以最小化损失函数
第6章 与学习相关的技巧
神经网络的学习的目的是找到使损失函数的值尽可能小的参数。这是寻 找最优参数的问题,解决这个问题的过程称为最优化(optimization)
SGD:
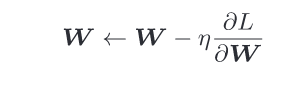
SGD 的缺点是,如果函数的形状非均向(anisotropic),比如呈延伸状,搜索的路径就会非常低效
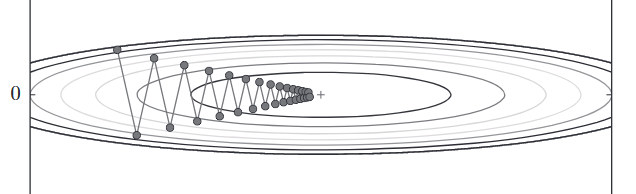
SGD低效的根本原因是,梯度的方向并没有指向最小值的方向
Momentum方法:
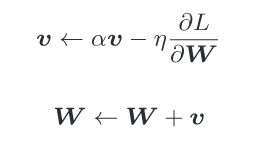
第 8 章 深度学习
GPU相比CPU更擅长矩阵计算,CPU擅长连续的计算。
为了加速计算,使用分布式学习方法加快速度


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









