







 本文介绍了在CVPR 2018发表的研究,提出了利用3D几何约束进行无监督深度和 ego-motion 估计的新方法。与仅关注局部像素的现有方法不同,该方法通过确保相邻帧间点云和相机运动的一致性来全局约束深度估计。主要贡献包括深度不一致性惩罚损失、基于原则的遮挡掩模和3D点云对齐损失。此外,该方法能在未标记的视频上学习,且未开源代码。
本文介绍了在CVPR 2018发表的研究,提出了利用3D几何约束进行无监督深度和 ego-motion 估计的新方法。与仅关注局部像素的现有方法不同,该方法通过确保相邻帧间点云和相机运动的一致性来全局约束深度估计。主要贡献包括深度不一致性惩罚损失、基于原则的遮挡掩模和3D点云对齐损失。此外,该方法能在未标记的视频上学习,且未开源代码。
基于3d几何约束的无监督深度估计
文章发表在CVPR 2018 ,代码貌似未开源
摘要
此前的无监督的深度估计的方法大多是采用基于图像重建和基于梯度的损失,只考虑了局部像素点之间的关系,并未从整体上对深度进行约束。我们的主要贡献是明确考虑了场景的三维几何,提出一种三维几何约束,使得相邻帧之间估计出的点云和相机自运动保持一致。另外作者的方法也可以在自己用手机收集的数据集上进行训练。
Introduction
结构上都是类似的,包含一个单视图深度估计网络,和一个基于相邻图像对的相机位姿估计网络。
主要的贡献包括以下三点:
1、提出一个直接对估计的深度不一致性进行惩罚的loss
2、一个Principled mask。通过计算产生一个mask,而不是采用学习的方法,解决运动以及前后帧之间存在的遮挡问题。
3、提出的方法可以在未标定的视频上进行学习。
Method
总体流程如下图
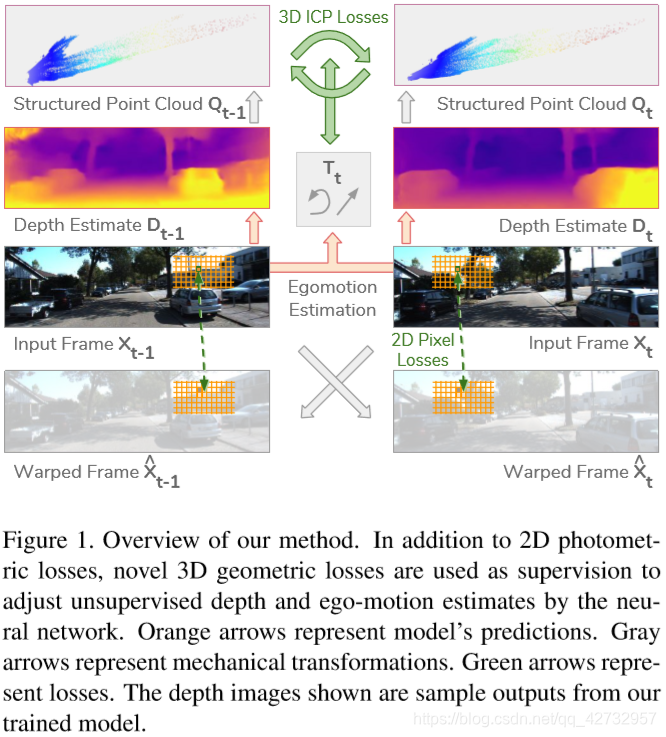
1、Problem Geometry
给定连续帧 Xt-1 和 Xt,以及对应的估计出的深度Dt-1、Dt和自运动(也就是相机位姿)Tt,就可以把二维的图像点投影到三维空间的点云。具体就是,例如图像上的一个像素点在其深度值D和相机内参K的情况下,就可以计算其对应的三维点。
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 2659
2659

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









