




 本文介绍了强化学习中的模型基础(Model-Based)与模型自由(Model-Free)实现方式,探讨了off-line(离线)与on-line(在线)方法的区别,强调了在有限阶段DP问题中的模型依赖性和蒙特卡洛模拟的应用。
本文介绍了强化学习中的模型基础(Model-Based)与模型自由(Model-Free)实现方式,探讨了off-line(离线)与on-line(在线)方法的区别,强调了在有限阶段DP问题中的模型依赖性和蒙特卡洛模拟的应用。
写在前面的
前一章链接:
《强化学习与最优控制》学习笔记(三):强化学习中值空间近似和策略空间近似概述
这章主要是介绍一些概念,即 Model-Based 与 Model-Free Implementation以及Off-line 与 On-line Method,方便后面内容的学习。
Model-Based 与 Model-Free Implementation
我们在前面的学习就已经知道,一个有限阶段(finite horizon)的DP问题的数学模型如下:
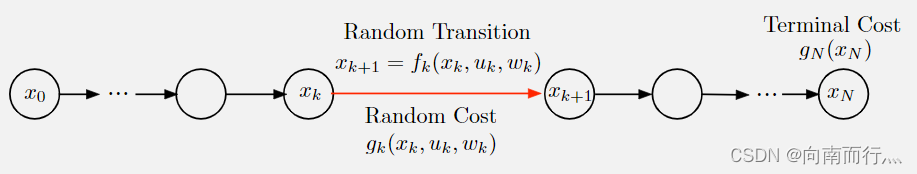

在model-based中,求解DP问题通常要假设,
甚至
的分布我们能够得到,也就说给定任意的(
),我们就能得到
。对于
中的期望部分,主要是通过代数的方法来计算,也就是既然我们都知道
了,就把每一个
乘上
然后总体加起来就是期望,很清楚地就能感觉到,其实在很多情况下,我们都不一定能够都得到这些信息,所以说现在在学术界基于model-based的方法还是比较少,但是假如我们能得到这些信息的话,其实对于系统的帮助是很大的,所以model-based的方法还是有相当大的研究意义的。
而在model-free中,期望的部分就改用蒙特卡罗模拟(Monte Carlo simulation),其实这个也很好理解。举个最简单的抛硬币的例子,假设硬币是两面且材质均匀(不均匀的话正反面概率会不一样,得到的期望也会不一样),抛到正面为1,反面为0。那么很容易就能知道,当抛的次数达到很多很多次时,其平均值就会非常接近实际期望0.5。得益于现在计算机的发展,我们可以在求解问题的时候用仿真器(或使用大量数据)来做大量的实验,从而逼近期望值。
注意到在确定性问题(deterministic problems)中是没有期望,所以说只能用model-based的办法来求解。
Off-line 与 On-line Method
在值空间近似中,我们需要计算和对应的策略
:

那么就有两种方法可以考虑使用来计算,这两种方法分别是Off-line methods(在控制过程开始之前)与 On-line methods(在控制过程开始之后):
Off-line methods:在控制过程开始之前,完成需要求解策略的大部分计算,这种方法就是Off-line methods。比如算好
(算这个通常比较花时间)然后存储起来,当控制过程开始之后,就能够很快地算出相应的策略。
On-line methods:这类方法就是说在观测到当前状态之后,再计算与之相关的
,然后再得到策略
,执行后观测下一个状态
,如此循环。
写在后面的
下一章链接:



















 1160
1160

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











