




前排提示:本文属于新手入坑系列,不做深入的研究。
1. 背景介绍
大模型基于大量文本训练而成,内部存储了大量知识。
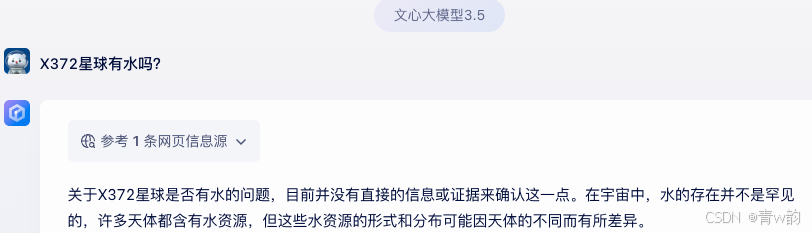
实际应用过程中,【银行、公司内部】等私人知识,大模型当然不知道,所以在回答的时候,大模型可能会 “胡乱回答”(它可能会凭借以往的知识来编造一个答案。)或者“回答不知道答案”。【如图】
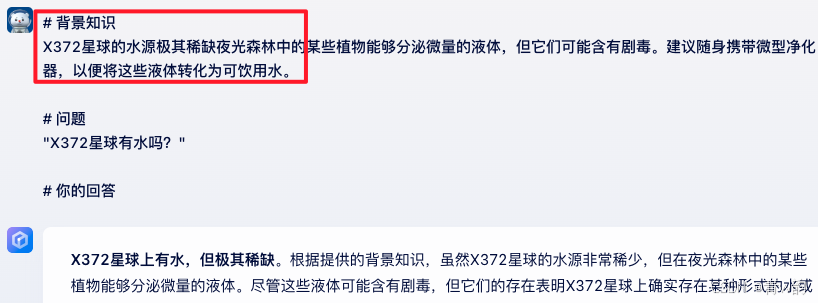
因此,基于人类学习的情况,我们在大模型回答知识之前,把内部私密知识给他,他就可以基于我们给的知识回答内容了。【如图】
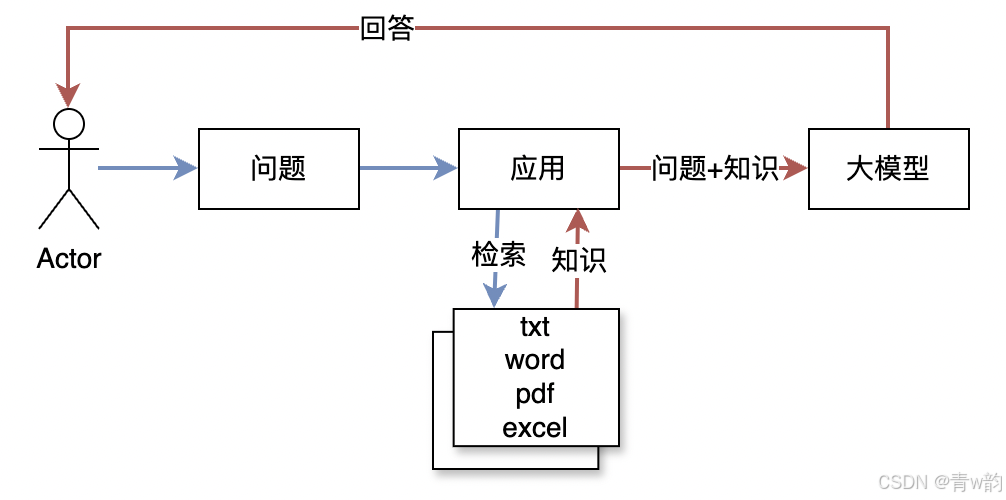
2. 原理介绍
3. 实现逻辑
3.1 不同形式的知识处理
在实际应用过程中,知识可能是各种形式,比如:word文档、txt文本文档、PDF文档、Excel表格,等等等等。
不同形式的知识,我们需要统一处理成文本块,方便检索。
那么就需要根据业务要求,解析每一种业务需要的类型的文档。
3.2 模型上下文限制
因为
- 目前大模型单次问答所能塞入的知识比较有限,超长会无法运作。
百度千帆:

阿里千问:

- 假设我们知识库有10本书,每一本书有500页,50万字,用户的问题在其中的第1章节、第三行,此时如果我们把整本书的内容扔给大模型,其实给了他很多无用的知识。
因此,目前我们的处理都是先将知识分成小块,然后再根据用户的问题检索。
切为小块的方式有很多(固定切分,浮动切分,按照业务要求切分等),可以参考如下文章,暂不深入。
https://baoyu.io/translations/rag/5-chunking-strategies-for-rag
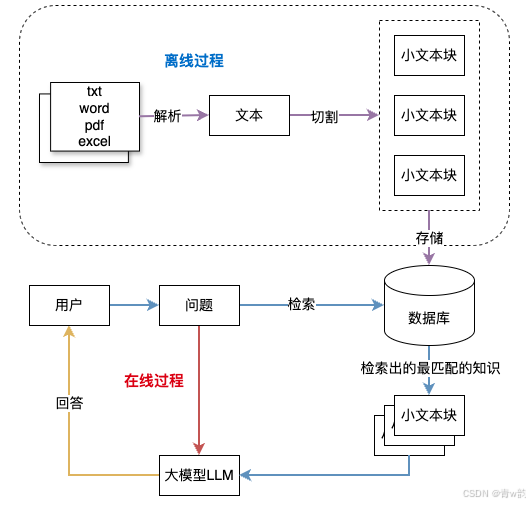
3.3 总结
4. 参考实现
4.1 Java
准备一个文件,当作知识库的内容。内容如下
《X372星球》生存法则
前言
欢迎来到X372星球,一个陌生而又充满未知的世界。在这里,生存并非一件简单的事。你将面对严苛的自然环境、未知的生物威胁以及资源的稀缺。这本《X372星球生存法则》旨在帮助你在这片神秘的土地上找到生存之道。谨记:灵活适应、冷静应对是你活下去的唯一资本。
第一章:了解环境
1.1 地形与气候
X372星球的地形多样,包括广阔的赤红沙漠、毒雾弥漫的沼泽、诡秘的夜光森林以及寒冷刺骨的极地冰原。气候变化迅速且无规律,白天可能酷热难耐,夜晚却寒风刺骨。在行动前,务必随时监测天气变化,选择合适的庇护所。
1.2 辐射与毒性
星球的大气层较薄,宇宙辐射强烈,部分区域还存在未知的毒性物质。在外出活动时,请佩戴全覆盖防护服,并携带便携式空气过滤器。同时定期检测身体状况,防止潜在的辐射病。
第二章:资源获取
2.1 水资源
水是生存的基础,但X372星球的水源极其稀缺。夜光森林中的某些植物能够分泌微量的液体,但它们可能含有剧毒。建议随身携带微型净化器,以便将这些液体转化为可饮用水。
2.2 食物来源
本星球的生态系统复杂,部分生物和植物可能是可食用的,但不要轻易尝试。建议携带一个便携式分子分析仪,对任何可能入口的物质进行分析。此外,小型昆虫和部分菌类可能是高能量食物,但也要注意辨别有毒标志(如异色荧光或刺鼻气味)。
2.3 能源获取
能源在X372星球尤为重要。寻找蓝晶矿(本星球特有的能源矿物),它不仅可以为设备充能,还可转化为热能。在蓝晶矿区工作时需佩戴防护装备,因为矿物开采过程中会释放有害气体。
第三章:建立庇护所
3.1 选址技巧
庇护所应选择在地势较高且周围视野开阔的地方,远离危险生物的活动区域。夜光森林边缘和极地裂缝附近是较佳的选址区域,但需注意环境特殊性。
3.2 建造材料
使用当地材料,如红沙混凝土、树脂状植物分泌物,以及蓝晶矿粉末作为加固材料。合理利用资源可以建造出耐用、保暖且防御性强的庇护所。
3.3 自我防御
庇护所应配备警报系统和防御装置,如声波驱逐器或自动激光塔。夜间是危险生物最活跃的时间段,请尽量避免外出,并确保庇护所的密闭性。
主逻辑如下:
// 主程序
public static void main(String[] args) throws IOException {
// 数据加载
String text = DataLoader.loadTextFromFile("text_data.txt");
// 切分文本
int chunkSize = 50; // 每块 50 字
List<String> chunks = TextSplitter.splitText(text, chunkSize);
// 存储文本块
String chunkFilePath = "text_chunks.txt";
ChunkStorage.saveChunks(chunks, chunkFilePath);
// 用户提问
String query = "X372星球有水吗?";
// 知识匹配,从数据库中取最匹配的前X个。
List<KnowledgeMatcher.ScoredChunk> relevantChunk = KnowledgeMatcher.matchTopKnowledge(ChunkStorage.loadChunks(chunkFilePath), query, 5);
// 输出答案
System.out.println(QAHandler.generateAnswer(query, relevantChunk));
}
我们可以自行实现上述方法中缺失的内容【DataLoader、TextSplitter等】,也可以参考我 “用GPT帮你完成50%代码开发!”的文章,让AI生成代码。
其中涉及一个问题,那就是使用大模型,我在项目中采用的是 “百度的千帆大模型speed(简单一点)”。你也可以选用其他,例如:腾讯的模型。【注意:使用前请参考官方文档,可以看看哪些免费】
注⚠️:一般来说,使用大模型都需要先导入Maven依赖,然后去对应的模型服务提供商注册,获取一些凭证(AK,SK)等,然后再调用。
下面是使用千帆大模型的一种实现参考:
效果先展示一下:
| 问题\是否使用知识库 | 否 | 是 |
|---|---|---|
| X372星球有水吗? | 关于X372星球是否有水的问题,目前没有足够的资料或证据来直接回答这个问题。 | 在《X372星球》的生存法则中,提到X372星球的水源极其稀缺,所以X372星球上有水,但是水资源非常有限。 |
| X372星球的能源情况 | 关于X372星球的能源情况,由于缺乏具体的信息和背景资料,我无法给出准确的答案。 | 在《X372星球》的生存法则中,能源获取是极为重要的一部分。X372星球的能源情况较为特殊,能源在该星球上相对稀缺 |
新建一个Java项目,将文本放在resources/test_data.txt文件。
新建一个主类KnowledgeSystem,架构如下。
我这里要求最简单实现,因此不采用数据库,直接使用文件来存储数据。直接使用最简单的文本字符串匹配。
当用户的问题和知识库里的字相同,则分数加一,取最高分数的即可。(这个策略效果很一般,但是实现很简单,为了不引入多余的内容,我这里采用最简单的实现)
最好的方法是使用算法向量服务匹配文本语义(文本的含义),这个如果我后续有空,会出一个2.0版本,来解释一下。
pom导入包
<dependency>
<groupId>com.baidubce</groupId>
<artifactId>qianfan</artifactId>
<version>0.1.1</version>
</dependency>
注意修改下面代码里的ak和sk,使用你自己的ak和sk。
import com.baidubce.qianfan.Qianfan;
import com.baidubce.qianfan.core.auth.Auth;
import com.baidubce.qianfan.model.chat.ChatResponse;
import java.io.BufferedReader;
import java.io.BufferedWriter;
import java.io.FileNotFoundException;
import java.io.FileReader;
import java.io.FileWriter;
import java.io.IOException;
import java.io.InputStream;
import java.util.ArrayList;
import java.util.Comparator;
import java.util.List;
public class KnowledgeSystem {
// 数据加载器模块
static class DataLoader {
public static String loadTextFromFile(String filePath) throws IOException {
// 使用 ClassLoader 获取文件路径
ClassLoader classLoader = Thread.currentThread().getContextClassLoader();
if (classLoader == null) {
throw new IllegalStateException("ClassLoader is null");
}
// 获取文件的输入流
try (InputStream inputStream = classLoader.getResourceAsStream(filePath)) {
if (inputStream == null) {
throw new FileNotFoundException("File not found in classpath: " + filePath);
}
// 转换为字符串
return new String(inputStream.readAllBytes());
}
}
}
// 切分器模块
static class TextSplitter {
public static List<String> splitText(String text, int chunkSize) {
List<String> chunks = new ArrayList<>();
int length = text.length();
for (int i = 0; i < length; i += chunkSize) {
chunks.add(text.substring(i, Math.min(length, i + chunkSize)));
}
return chunks;
}
}
// 存储器模块
static class ChunkStorage {
public static void saveChunks(List<String> chunks, String filePath) throws IOException {
try (BufferedWriter writer = new BufferedWriter(new FileWriter(filePath))) {
for (int i = 0; i < chunks.size(); i++) {
writer.write("## Block " + (i + 1) + " ##\n");
writer.write(chunks.get(i));
writer.write("\n\n");
}
}
}
public static List<String> loadChunks(String filePath) throws IOException {
List<String> chunks = new ArrayList<>();
try (BufferedReader reader = new BufferedReader(new FileReader(filePath))) {
StringBuilder chunk = new StringBuilder();
String line;
while ((line = reader.readLine()) != null) {
if (line.startsWith("## Block ")) {
if (chunk.length() > 0) {
chunks.add(chunk.toString().trim());
chunk.setLength(0);
}
} else {
chunk.append(line).append("\n");
}
}
if (chunk.length() > 0) {
chunks.add(chunk.toString().trim());
}
}
return chunks;
}
}
// 知识匹配器模块
static class KnowledgeMatcher {
/**
* 找出与用户问题最匹配的前 topN 个文本块。
*
* @param chunks 文本块列表
* @param query 用户问题
* @param topN 返回前 N 个匹配块
* @return 匹配的块及其分数
*/
public static List<ScoredChunk> matchTopKnowledge(List<String> chunks, String query, int topN) {
List<ScoredChunk> scoredChunks = new ArrayList<>();
// 计算每个块的匹配分数
for (String chunk : chunks) {
int score = 0;
for (char c : query.toCharArray()) {
score += countOccurrences(chunk, c);
}
scoredChunks.add(new ScoredChunk(chunk, score));
}
// 按分数降序排序
scoredChunks.sort(Comparator.comparingInt(ScoredChunk::getScore).reversed());
// 返回前 topN 个块
return scoredChunks.subList(0, Math.min(topN, scoredChunks.size()));
}
/**
* 统计字符在字符串中出现的次数。
*/
private static int countOccurrences(String text, char c) {
int count = 0;
for (char ch : text.toCharArray()) {
if (ch == c) {
count++;
}
}
return count;
}
/**
* 匹配结果的数据结构:包含块内容和分数。
*/
public static class ScoredChunk {
private final String chunk;
private final int score;
public ScoredChunk(String chunk, int score) {
this.chunk = chunk;
this.score = score;
}
public String getChunk() {
return chunk;
}
public int getScore() {
return score;
}
@Override
public String toString() {
return "匹配分数: " + score + "\n文本块: " + chunk;
}
}
}
// 问答器模块
static class QAHandler {
public static String generateAnswer(String query, List<KnowledgeMatcher.ScoredChunk> knowledge) {
String prompt = "# 背景知识\n"
+ knowledge.toString()
+ "# 用户的问题\n"
+ query
+ "# 你的回答";
ChatResponse response = new Qianfan(Auth.TYPE_OAUTH, "your_ak", "your_sk")
.chatCompletion()
.model("ERNIE-Speed-8K") // 使用model指定预置模型
.addMessage("user", prompt) // 添加用户消息 (此方法可以调用多次,以实现多轮对话的消息传递)
.temperature(0.01) // 自定义超参数
.topP(0.01)
.execute(); // 发起请求
// 这里可以调用大模型生成答案
return "用户问题: " + query +
"\n生成回答: [" + response.getResult() + "]" +
"\n相关知识: " + knowledge;
}
}
// 主程序
public static void main(String[] args) throws IOException {
// 数据加载
String text = DataLoader.loadTextFromFile("text_data.txt");
// 切分文本
int chunkSize = 50; // 每块 50 字
List<String> chunks = TextSplitter.splitText(text, chunkSize);
// 存储文本块
String chunkFilePath = "text_chunks.txt";
ChunkStorage.saveChunks(chunks, chunkFilePath);
// 用户提问
String query = "X372星球有水吗?";
// 知识匹配
List<KnowledgeMatcher.ScoredChunk> relevantChunk = KnowledgeMatcher.matchTopKnowledge(ChunkStorage.loadChunks(chunkFilePath), query, 5);
// 输出答案
System.out.println(QAHandler.generateAnswer(query, relevantChunk));
}
}

















 752
752

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









