







 本文通过scikit-learn演示了回归和分类任务,包括LinearRegression、DecisionTree、LogisticRegression和SVM。深入探讨了模型选择过程,如交叉验证和GridSearchCV,以及解决欠拟合和过拟合的方法。
本文通过scikit-learn演示了回归和分类任务,包括LinearRegression、DecisionTree、LogisticRegression和SVM。深入探讨了模型选择过程,如交叉验证和GridSearchCV,以及解决欠拟合和过拟合的方法。
Scikit-Learn -- 实战
一、大致流程
1.Estimator框架(预测器)
- model.fit()
2.Supervised Learning
- model.predict()
- model.predict_proba()
- model.score()
3.Unsupervised learning
* 没有标注型数据,不知道最终预测的结果,需要对数据进行转换
- model.transform()
- model.fit_transform() #效率更高
1.Practice regression
以Boston房价为例
a.LinearRegression
%matplotlib inline
import matplotlib.pyplot as plt
from sklearn.datasets import load_boston
from sklearn.linear_model import LinearRegression
from sklearn.metrics import mean_absolute_error
# 载入数据
data = load_boston()
# 样本数,样本特征数
n_samples, n_feature = data.data.shape
# new 一个lr模型
lr = LinearRegression()
# 用模型拟合数据
lr.fit(data.data, data.target)
# 预测数据
pred = lr.predict(data.data)
# 评估模型
score = mean_absolute_error(data.target, pred)
print(score,n_samples,n_feature)
print(data.target.shape, data.keys())
3.272944637996926 506 13
(506,) dict_keys([‘data’, ‘target’, ‘feature_names’, ‘DESCR’])
plt.scatter(data.target, pred)
plt.xlabel('true price')
plt.ylabel('predicted price')
plt.plot(data.target, data.target, c='r')
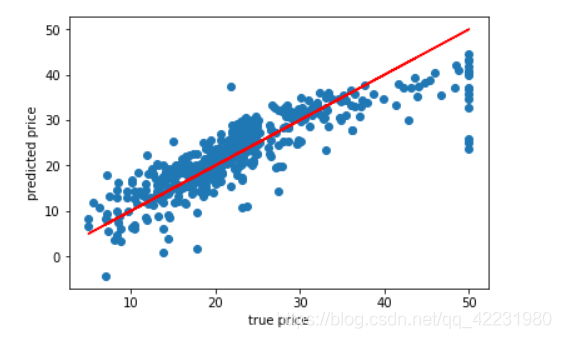
# play with the feature (feature_i -- target)
column_i = 5
plt.scatter(data.data[:,column_i], data.target)
print(data.feature_names[column_i])
b.DecisionTree
from sklearn.tree import DecisionTreeRegressor
dtr = DecisionTreeRegressor()
dtr.fit(data.data, data.target)
pred_dtr = dtr.predict(data.data 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章

















 838
838

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









