







 这段代码展示了如何使用Scikit-Learn库训练线性回归模型来预测国家的生活满意度,基于GDP数据。首先进行了数据预处理,然后使用线性回归模型进行训练,并预测塞浦路斯的生活满意度。接着,用K近邻回归模型替代线性模型再次预测,比较结果。代码还包含了数据可视化和模型评估的部分。
这段代码展示了如何使用Scikit-Learn库训练线性回归模型来预测国家的生活满意度,基于GDP数据。首先进行了数据预处理,然后使用线性回归模型进行训练,并预测塞浦路斯的生活满意度。接着,用K近邻回归模型替代线性模型再次预测,比较结果。代码还包含了数据可视化和模型评估的部分。
示例1-1 使用Scikit-Learn训练一个线性模型
# Python ≥3.5 is required
import sys
assert sys.version_info >= (3, 5) # Python ≥3.5 is required,否则抛出错误
# Scikit-Learn ≥0.20 is required
import sklearn
assert sklearn.__version__ >= "0.20" # Scikit-Learn ≥0.20 is required,否则抛错。
# 备注:Scikit-learn是一个支持有监督和无监督学习的开源机器学习库。它还为模型拟合、数据预处理、模型选择和评估以及许多其他实用程序提供了各种工具。
# 经合组织统计生活满意度,国家平均GDP,处理后得到所需的数据(两表融合为一表)
# 涉及数据分析和处理的知识...
def prepare_country_stats(oecd_bli, gdp_per_capita):
oecd_bli = oecd_bli[oecd_bli["INEQUALITY"]=="TOT"]
oecd_bli = oecd_bli.pivot(index="Country", columns="Indicator", values="Value")
gdp_per_capita.rename(columns={
"2015": "GDP per capita"}, inplace=True)
gdp_per_capita.set_index("Country", inplace=True)
full_country_stats = pd.merge(left=oecd_bli, right=gdp_per_capita,
left_index=True, right_index=True)
full_country_stats.sort_values(by="GDP per capita", inplace=True)
remove_indices = [0, 1, 6, 8, 33, 34, 35]
keep_indices = list(set(range(36)) - set(remove_indices))
return full_country_stats[["GDP per capita", 'Life satisfaction']].iloc[keep_indices]
# 设置数据表格的存放路径,存于本地
import os
datapath = os.path.join("datasets", "lifesat", "")
# To plot pretty figures directly within Jupyter 直接在jupyter绘制漂亮的图形
%matplotlib inline # 将matplotlib的图表直接嵌入到Notebook之中
import matplotlib as mpl # matplotlib 数据可视化工具
mpl.rc('axes', labelsize=14) # 一次性设置多个参数,axes画布,xytick为XY轴,并指定大小。如mpl.rc('lines', linewidth=2, color='r')
mpl.rc('xtick', labelsize=12)
mpl.rc('ytick', labelsize=12)
# Download the data 下载数据,爬取数据
import urllib.request
DOWNLOAD_ROOT = "https://raw.githubusercontent.com/ageron/handson-ml2/master/"
os.makedirs(datapath, exist_ok=True) # 当前目录下创建文件夹datapath
for filename in ("oecd_bli_2015.csv", "gdp_per_capita.csv"):
print("Downloading", filename)
url = DOWNLOAD_ROOT + "datasets/lifesat/" + filename
urllib.request.urlretrieve(url, datapath + filename) # 将查到的url放在datapath路径下,并命名为filename
# Code example
import matplotlib.pyplot as plt # matplotlib画图工具,数据可视化
import numpy as np # 数据处理,处理矩阵、数组
import pandas as pd # 数据处理,处理表格
import sklearn.linear_model # 从sklearn机器学习库里调用线性模型
# Load the data # 加载原始数据。此时数据已在本地datapath
oecd_bli = pd.read_csv(datapath + "oecd_bli_2015.csv", thousands=',')
gdp_per_capita = pd.read_csv(datapath + "gdp_per_capita.csv",thousands=',',delimiter='\t',
encoding='latin1', na_values="n/a")
# Prepare the data # 调用prepare_country_stats准备所需的数据。np.c_是列合并,要求列数一致,np.r_是行合并,要求行数一致。
country_stats = prepare_country_stats(oecd_bli, gdp_per_capita)
X = np.c_[country_stats["GDP per capita"]]
y = np.c_[country_stats["Life satisfaction"]]
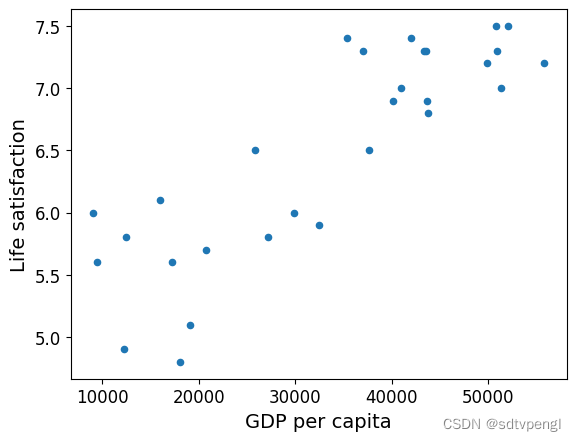
# Visualize the data # 数据可视化
country_stats.plot(kind='scatter', x="GDP per capita", y='Life satisfaction')
plt.show()
# Select a linear model # 选择sklearn库里的一个线性回归模型
model = sklearn.linear_model.LinearRegression()
# Train the model # 训练模型
model.fit(X, y)
# Make a prediction for Cyprus # 根据模型为塞浦路斯做预测,根据Xgdp预测幸福指数
X_new = [[22587]] # Cyprus' GDP per capita
print(model.predict(X_new)) # outputs [[ 5.96242338]]
# 用k近邻回归模型替换原来的线性模型再预测一次
# Select a 3-Nearest Neighbors regression model
import sklearn.neighbors
model1 = sklearn.neighbors.KNeighborsRegressor(n_neighbors=3)
# Train the model
model1.fit(X,y)
# Make a prediction for Cyprus
print(model1.predict(X_new)) # outputs [[5.76666667]]
# Where to save the figures # 写一个函数保存图片
PROJECT_ROOT_DIR = "."
CHAPTER_ID = "fundamentals" # 章节ID:基本原理
IMAGES_PATH = os.path.join(PROJECT_ROOT_DIR, "images", CHAPTER_ID) # 图片路径
os.makedirs(IMAGES_PATH, exist_ok=True)
# save_fig参数(图片id即图片名,tight_layout固定间距,扩展名,像素dpi),结合plt.savefig进行图片保存
def save_fig(fig_id, tight_layout=True, fig_extension="png", resolution& 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 5454
5454

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









