







 BodyNet是一种端到端的网络,能够从单张图像中预测3D人体形状,采用volumetric representation。该网络结合了3D体积损失、多视角重投影损失和多任务损失,包括2D姿势、2D人体部分分割和3D姿势的监督。在SURREAL和Unite the People数据集上进行了测试,同时能进行volumetric body-part segmentation。训练过程中,网络首先独立训练各个子网,然后联合微调。
BodyNet是一种端到端的网络,能够从单张图像中预测3D人体形状,采用volumetric representation。该网络结合了3D体积损失、多视角重投影损失和多任务损失,包括2D姿势、2D人体部分分割和3D姿势的监督。在SURREAL和Unite the People数据集上进行了测试,同时能进行volumetric body-part segmentation。训练过程中,网络首先独立训练各个子网,然后联合微调。
本文所做的是从单张自然图像预测3D人体。文章所用的是mesh representation 是 volumetric representation 并且提出了BodyNet。这个网络可以直接从单张图像得到体积测定的人体外形。这个网络是端到端的网络,其包含一个体积测定的3D loss,多视角再投射loss,中间级的2D姿势,2D人体部分分割,和3D姿势的监督。评估方法,拟合SMPL模型和本网络的输出。在SURREAL 和 Unite the People datasets上做的测试。此外此方法还能进行volumetric body-part segmentation。Body Net完全可微,可以在应用中作为一个子网。
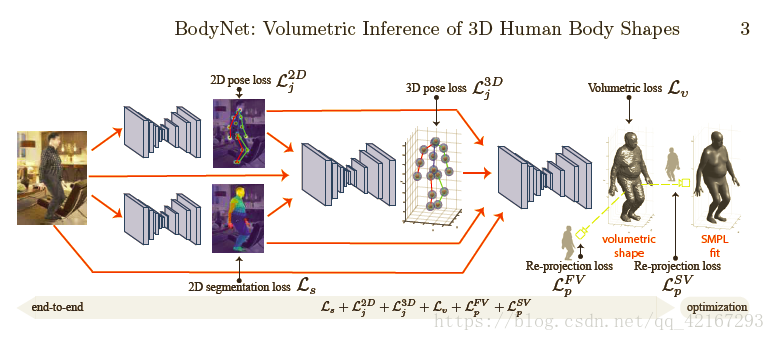
这种单视角的图像的3D人体估计缺少大尺度的训练数据集,输出的3D人体mesh维度太高,没有合适的3D人体的shape representation,这些原因使得这个问题变得极具挑战。关于神经网路的最佳的3D representation依旧是个不确定的问题,这篇文章提出volumetric representation。BodyNet生成在一个人的3D占有网格上的可能性。对于3D 人体外形,这篇文章用的是一个基于体素的方法,其外形估计的子网产生的3D shape 代表的是定义在固定分辨率的体素网格上的占有率映射。给一个3D body文章定义一个体素网格使其中心在3D body的root joint(如hip joint),每个在body内部的体素都被标记为占有(volumetric的含义)。本文用binvox体素化真值meshes(binvox,网站)。体素化使得体素化后的body略大于原本的mesh。
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章

















 1136
1136

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









