




 本文探讨了一种从单张RGB图像重建人体网格的Human Mesh Recovery(HMR)方法,它无需2D关节检测,而是通过深度学习框架直接估计。该方法结合了编码器、迭代3D回归模型和对抗生成网络,使用弱监督和unpaired数据进行训练,以克服现实世界图像中的挑战。通过SMPL模型,网络能够学习关节角度限制和人体几何先验,实现更准确的3D人体重建。
本文探讨了一种从单张RGB图像重建人体网格的Human Mesh Recovery(HMR)方法,它无需2D关节检测,而是通过深度学习框架直接估计。该方法结合了编码器、迭代3D回归模型和对抗生成网络,使用弱监督和unpaired数据进行训练,以克服现实世界图像中的挑战。通过SMPL模型,网络能够学习关节角度限制和人体几何先验,实现更准确的3D人体重建。
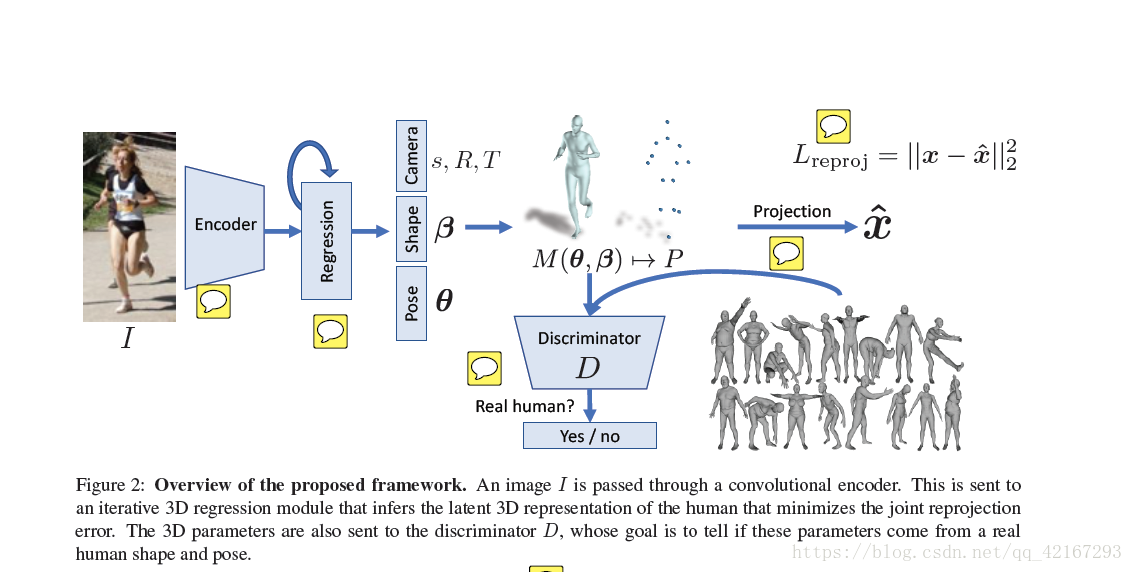
本文讲了如何从单张RGB图片重建人体的mesh,这个方法为Human Mesh Recovery(HMR)。
关于从图片或视频重建人体的meshes可以分为两类方法:两阶段法,直接估计法。
两阶段法:
1)用2Dpose检测,预测2D关节位置
2)通过回归分析和model fitting从2D关节去预测3D关节,其公共方法是利用一个学习的3D骨架库。
这些方法为了约束2D-to-3D的固有歧义,用了不同的先验:
1)假定四肢长度,或比例
2)学习一个姿势先验,获得了与姿势独立的关节角度限制。
特点:对于域的转变更鲁棒,过度依赖2D关节点侦测,丢掉了图片的信息。
本文的网络可以潜在的学习关节角度的限制。
直接估计:
可以捕捉真值动作的视频数据集HumanEva, Huam3.6M,提供训练数据,所以3D关节估计就可以变为一个标准的监督学习问题。
1)直接从图像估计,通过深度学习框架
2)优势的方法,全卷积网络
特点:拥有精确的真值3D标记的图片是在可控的环境下得到的,仅仅这些图片训练出的模型不能再真实世界里生成的很好。
本文是从图像像素去估计人体的meshes,并没有进行2D的关节检测。
这个框架的训练可以用paired 2D-to-3D supervision,也可不用。这样设计是因为:1)in-the-wild images缺少大尺度的真值;2)现存的有3D标记的数据是从受约的环境中获取的,在这些数据集上训练的模型对于丰富的图片来讲形成的模型不好。
文章用的训练数据是:1)2D真值标记的in-the-wild images,LSP, LSP-extended MPII and MS COCO ;2)拥有不同外形和姿势3Dmeshes,Human3.6M and MPIINF-3DHP 。
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章

















 1445
1445

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









