







进程与线程的关系: 操作系统可以同时执行多个任务,每一个任务就是一个进程,进程可以同时执行多个任务,每一个任务就是一个线程。
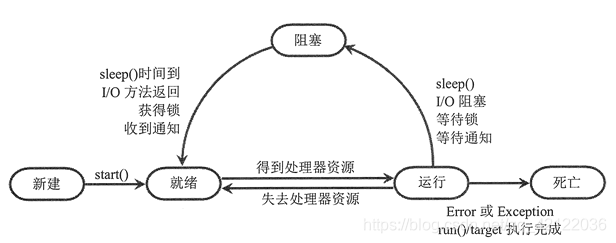
线程被创建并启动后,并不会直接进入执行状态,也不会一直处于执行状态,线程的生命周期中,它会经历新建(new)、就绪(Ready)、运行(Running)、阻塞(Blocked)和死亡(Dead)5 种状态。
当一个进程里只有一个线程时,叫作单线程。超过一个线程就叫作多线程。
每个线程必须有自己的父进程,且它可以拥有自己的堆栈、程序计数器和局部变量,但不拥有系统资源,因为它和父进程的其他线程共享该进程所拥有的全部资源。线程可以完成一定的任务,可以与其他线程共享父进程中的共享变量及部分环境,相互之间协同完成进程所要完成的任务。
线程的运行是抢占式的,也就是说,当前运行的线程在任何时候都可能被挂起,以便另外一个线程可以运行。
同一时刻,Python 主程序只允许有一个线程执行
线程并发执行,CPU 以快速轮换的方式在多个线程之间切换,从而给用户一种错觉,即多个线程似乎同时在执行
线程常用函数:
- threading.current_thread():它是 threading 模块的函数,该函数总是返回当前正在执行的线程对象。
- getName():它是 Thread 类的实例方法,该方法返回调用它的线程名字。
-
threading.enumerate():返回一个正运行线程的 list 集合。“正运行”是指线程处于“启动后,且在结束前”状态,不包括“启动前”和“终止后”状态。
- threading.activeCount():返回正在运行的线程数量。与 len(threading.enumerate()) 有相同的结果。
1.调用 Thread 类的构造器创建线程
# -*- coding: utf-8 -*-
import threading
# 调用thread类的构造器创建线程
# 定义一个普通的action函数,该函数准备作为线程执行体
def action(max):
for i in range(max):
# 调用threading模块 current_thread()函数获取当前线程
# 线程对象的getName()方法获取当前线程的名字
print(threading.current_thread().getName() + ' ' + str(i))
# 主程序
for i in range(50):
print(threading.current_thread().getName() + ' ' + str(i))
if i == 20:
# 创建并启动第一个线程
t1 = threading.Thread(target=action, args=(50,))
t1.start()
t2 = threading.Thread(target=action, args=(50,))
t2.start()
print('主线程执行完毕')target:指定该线程要调度的目标方法。
args:指定一个元组,以位置参数的形式为 target 指定的函数传入参数。元组的第一个元素传给 target 函数的第一个参数,元组的第二个元素传给 target 函数的第二个参数……依此类推。
2.继承 Thread 类创建线程类
# -*- coding: utf-8 -*-
# 继承Thread类创建线程类
# 继承threading.Thread类来创建线程
class FkThread(threading.Thread):
def __init__(self):
threading.Thread.__init__(self)
self.i = 0
# 重写run方法作为线程执行体
# run() 方法的方法体就代表了线程需要完成的任务,因此把 run() 方法称为线程执行体。
def run(self):
while self.i < 50:
# 调用threading模块current_thread()函数获取当前线程
# 线程对象的getName()方法获取当前线程的名字
print(threading.current_thread().getName() + ' ' + str(self.i))
self.i += 1
# 主程序
for i in range(50):
print(threading.current_thread().getName() + ' ' + str(i))
if i == 20:
ft1 = FkThread()
ft1.start()
ft2 = FkThread()
ft2.start()
print('主线程完成')
当线程对象调用 start() 方法之后,该线程处于就绪状态,此时线程并未运行,只是表明自己已经可以运行了,至于该线程何时开始运行,取决于 Python 解释器中线程调度器的调度(何时得到CPU资源)。
注意,启动线程使用 start() 方法,而不是 run() 方法。调用 start() 方法来启动线程,系统会把该 run() 方法当成线程执行体来处理;但如果直接调用线程对象的 run() 方法,则 run() 方法立即就会被执行,而且在该方法返回之前其他线程无法并发执行。也就是说,如果直接调用线程对象的 run() 方法,则系统会把线程对象当成一个普通对象,此时 run() 方法是一个普通方法,不是线程执行体。
只能对处于新建状态的线程调用 start() 方法。也就是说,如果程序对同一个线程重复调用 start() 方法,将引发 RuntimeError 异常。
创建线程完毕后,直接调用线程对象的run方法,程序运行的结果是整个程序只有一个主线程,而且此时不能通过getName()方法获取当前执行线程的名字,直接调用线程对象的name属性获取线程名
# -*- coding: utf-8 -*-
import threading
# 定义准备作为线程执行体的action函数
def action(max):
for i in range(max):
# 直接调用run()方法时,Thread的name属性返回的是该对象的名字
# 而不是当前线程的名字
# 使用threading.current_thread().name总是获取当前线程的名字
print(threading.current_thread().name + " " + str(i)) # ①
# 直接调用线程对象的run方法,程序运行的结果是整个程序只有一个主线程,而且此时不能通过getName()方法获取当前执行线程的名字,直接调用线程对象的name属性获取线程名
for i in range(10):
# 调用Thread的currentThread()方法获取当前线程
print(threading.current_thread().name + " " + str(i))
if i == 5:
# 直接调用线程对象的run()方法
# 系统会把线程对象当成普通对象,把run()方法当成普通方法
# 所以下面两行代码并不会启动两个线程,而是依次执行两个run()方法
threading.Thread(target=action, args=(10,)).run()
threading.Thread(target=action, args=(10,)).run()
运行结果:
线程运行与阻塞状态
系统中处于就绪状态的线程获取到CPU资源后,开始执行 run() 方法的线程执行体,此时线程处于运行状态,但一个线程不可能一直处于运行状态(除非它的线程执行体足够短,瞬间就执行结束),线程在执行过程中需要被中断(CPU-时间片到期),以便让出资源给其他线程执行。
线程的调度有抢占式和非抢占式(协作式)两种:
抢占式:抢占式调度的多线程系统,那么每个线程将由系统来分配执行时间,线程的切换不由线程本身决定,在这种实现线程调度的方式下,线程执行时间系统可控的。
抢占式线程调度策略下多个线程共同竞争CPU时,存在多种分配策略(优先级高的线程优先获取时间片或者其他分配策略,Java中线程会按优先级分配CPU时间片运行),但是每种策略下每个线程只是在很短的时间内占有cpu,这段时间就是时间片,到了该线程的时间片,就开始执行任务,一旦时间片结束,资源立马被释放,任务也停止,别的线程获得资源,等下一次时间片到来时,再去执行任务。
协作式:使用协同式调度的多线程系统,线程执行时间由线程本身控制,线程把自己工作执行完后,要主动通知系统切换到另外一个线程上。(线程调用了它的 sleep() 或 yield() 方法,放弃其所占用的资源(也就是必须由该线程主动放弃其所占用的资源))
当前执行的线程被阻塞进入阻塞状态后,其他线程就会获取到执行的机会。被阻塞的线程会重新进入就绪状态,等待线程调度器再次调度它。
线程从阻塞状态只能进入就绪状态,无法直接进入运行状态。就绪和运行状态之间的转换通常不受程序控制,而是由系统线程调度所决定的,当处于就绪状态的线程获得处理器资源时,该线程进入运行状态;当处于运行状态的线程失去处理器资源时,该线程进入就绪状态。
# -*- coding: utf-8 -*-
import threading
import time
# 定义action函数作为线程执行体使用
def action(max):
for i in range(max):
print(threading.current_thread().name + ' ' + str(i))
# 创建线程对象
sd = threading.Thread(target=action, args=(5,))
for i in range(15):
print(threading.current_thread().name + ' ' + str(i))
if i == 5:
sd.start()
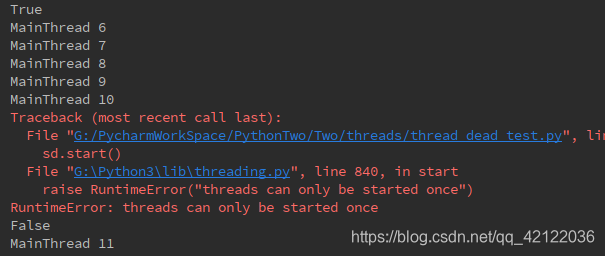
# 调用线程的 is_alive()方法 判断线程是否已经死亡
# 线程处于 就绪 运行 阻塞状态时 is_alive()返回True ,处于新建 死亡状态时返回False
print(sd.is_alive())
if i == 10:
time.sleep(5) # 线程睡眠 改变线程状态为阻塞态 is_alive()返回false
print(sd.is_alive())
if i > 10 and not (sd.is_alive()):
# 在线程死亡的情况下再次启动该线程
sd.start()
线程调用 sleep() 函数进入阻塞状态后,在其睡眠时间段内,该线程不会获得执行的机会,即使系统中没有其他可执行的线程,处于 sleep() 中的线程也不会执行,因此 sleep() 函数常用来暂停程序的运行。
在线程已死亡的情况下再次调用 start() 方法来启动该线程。运行程序,将引发 RuntimeError 异常 ,程序对于新建状态的线程也只能调用一次 start() 方法,否则也会出现 RuntimeError 错误
设置后台线程(守护线程)
将线程设置为后台线程,必须在线程启动之前进行设置。 即将 daemon 属性设为 True,必须在 start() 方法调用之前进行,否则会引发 RuntimeError 异常。
# -*- coding: utf-8 -*-
import threading
def action_daemon(max):
for i in range(max):
print(threading.current_thread().name + ' ' + str(i))
t = threading.Thread(target=action_daemon, args=(100,), name='后台线程')
# 将此线程设置为后台线程
# 也可在创建Thread对象时通过daemon参数将其设为后台线程
t.daemon = True
# 启动后台线程
t.start()
for i in range(10):
print(threading.current_thread().name + ' ' + str(i))
# (前台线程)主线程到此结束 ,后台线程也随之结束

















 1375
1375

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









