







最近因为搜狗微信进行了升级,导致公司的爬虫失去作用,然后其他同事又都有工作,于是乎这个任务就交给了我这个“菜鸟程序员”,因为之前没有写过爬虫相关的代码,Python也是工作后才现学的,导致为此纠结了好长时间。今天特意做个总结。
爬虫出现问题,首先确定问题来源,是数据爬取过程中出现问题还是就没爬取到数据(爬取的网站改版,网站反扒,ip被封等等),确定了问题才能针对的行进行解决。
此次搜狗微信文章爬虫失败,是由于搜狗微信端进行了反扒升级
1. 对微信文章的请求进行了再次构造
2. 由之前的广度变为深度爬虫(本人简单理解,有误请指出)
微信文章请求再次构造
列表页显示的链接

fiddler抓包过程中得到的链接
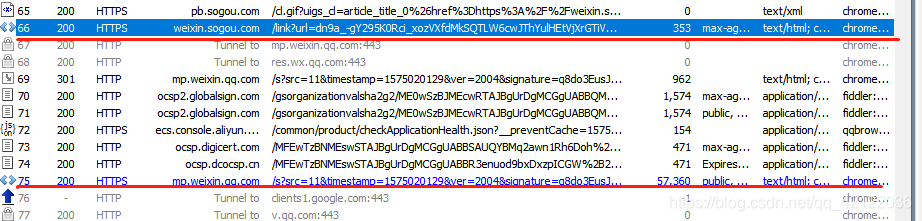
第一条红线是我们进入列表页后,在页面上得到的链接转换后的链接,点击其对应的标题我们进入微信文章页面,这是我们的链接就编程第二条红线所表示的。我们将列表页得到的链接,与第一条红线的链接进行对比。
/link?url=dn9a_-gY295K0Rci_xozVXfdMkSQTLW6cwJThYulHEtVjXrGTiVgS4XR14LbUFy5kOb5wudY7Vchbjx5-aT6Y1qXa8Fplpd9Ygh6C8KK-nFR8l4k8ClGtYqMlHhRDaqO9V9cidpqa221fr7WKVz9DOD9C3cHjUBts9TXllwG5_TveqOr92UZo6HkPfvlSdBaxVHXlJSc9uKqJ3To8vN1HzNbRUfLwWDdhHN9zYnmZLC0bP2W9N0lK-43EWecxUrMK99QhRlIdlRe0WC6Sbi7DA..&type=2&query=%E6%9D%8E%E7%8E%B0
/link?url=dn9a_-gY295K0Rci_xozVXfdMkSQTLW6cwJThYulHEtVjXrGTiVgS4XR14LbUFy5kOb5wudY7Vchbjx5-aT6Y1qXa8Fplpd94YPe0SHAQfV2xXTrnG-w63P4UB2rziqRgEoiSBWVhmYRYvK-1rmyJ8wMuHv7KnE6qvX5gX52s5ZokFSFrG0HIIReWBGWoM3dmLsZ-Lno0TDUTlV9ZAPriUBshZO34mLYC34-z6rcm0O5Kj3zN07cGpbRfbko4ypR4ZyKPGexM8D1AfaFW2DefQ..&type=2&query=%E6%9D%8E%E7%8E%B0&k=1&h=f
能清楚的看到后者比前者多了&k=1&h=f,这部分是在列表页中的<script></script>中实现的。

当鼠标点击 a 标签对应的标题时,对其对应的链接进行此处理,得到一个相当于加密后的链接,然后在fiddler中我们可以发现正是这个链接的请求返回了一个对应微信文章的链接。
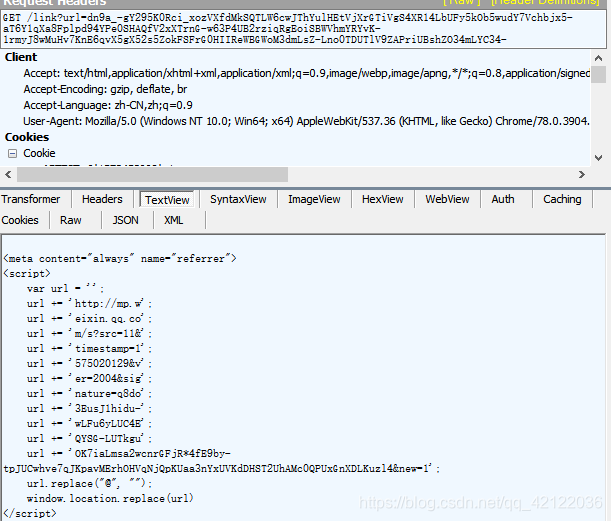
但我们直接发送这个链接的时候,会出现 这种情况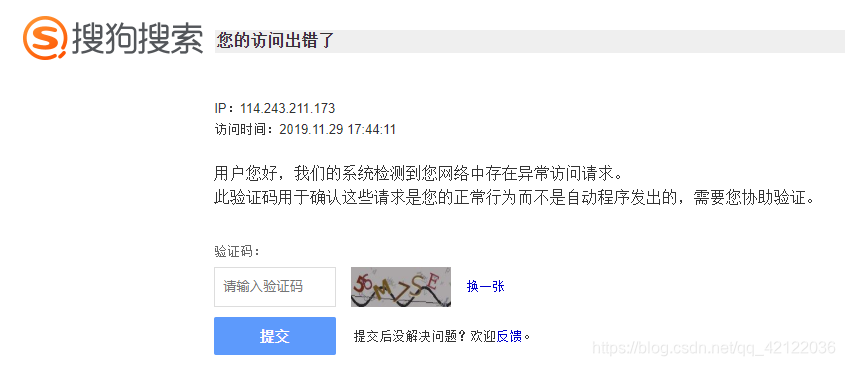
这时候我们就要考虑是否是微信端进行了反扒,或者是其他,然后我们通过正常方式进入微信文章页面,发现正常进入的情况下,该请求的请求头 ,cookie等信息一应俱全。OK,那我们就把这些信息都加上。
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1264
1264

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









