








1bit全加器
module Add1
(
input a,
input b,
input C_in,
output s,
output c, //进位
);
assign s=a^b^C_in;
assign c=(a&b) |(a&C_in) |(b&C_in);
//或者
//assign c=(a&b)|(a^b)&C_in;
endmodule为什么使用超前进位加法器,以四位为例子,全加器输出结果至少要等
第三个加法器的进位输出,才能得到结果,若级数越高,则组合逻辑的延迟高
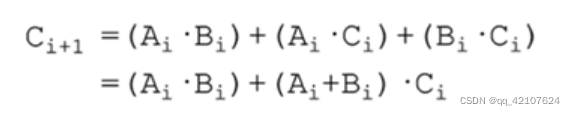

或者:传播信号为Ai^Bi
`timescale 1ns/1ns
//为甚使用超前进位加法器,以四位为例子,全加器输出结果至少要等
//第三个加法器的进位输出,才能得到结果,若级数越高,则组合逻辑的延迟高
module huawei8//四位超前进位加法器
(
input wire [3:0]A,
input wire [3:0]B,
output wire [4:0]OUT
);
wire [3:0] G;
wire [3:0] P;
assign G = A&B;
assign P = A|B;
wire [4:0] c;
assign c[0] = 0;
assign c[1] = G[0]|(P[0]&c[0]);
assign c[2] = G[1]|(P[1]&G[0])|(P[1]&P[0]&c[0]);
assign c[3] = G[2]|(P[2]&G[1])|(P[2]&P[1]&G[0])|(P[2]&P[1]&P[0]&c[0]);
assign c[4] = G[3]|(P[3]&G[2])|(P[3]&P[2]&G[1])|(P[3]&P[2]&P[1]&G[0])|(P[3]&P[2]&P[1]&P[0]&c[0]);
wire [3:0]sum;
assign sum = A^B^c[3:0];
assign OUT={c[4],sum};
endmodule`timescale 1ns/1ns
module huawei8//四位超前进位加法器
(
input wire [3:0]A,
input wire [3:0]B,
output wire [4:0]OUT
);
wire [3:0]g,p,f;
wire [4:1]c;
//*************code***********//
Add1 u1(A[0],B[0],0,f[0],g[0],p[0]);
genvar i;
generate
for(i=1;i<=3;i=i+1)begin:bitt
Add1 uuu(A[i],B[i],c[i],f[i],g[i],p[i]);
end
endgenerate
CLA_4 uut(p,g,0,c,,);
assign OUT={c[4],f};
//*************code***********//
endmodule
//下面是两个子模块
//Ci+1=ab+acin+bcin=ab+(a+b)cin 生成信号Gi=ab 传播信号Pi=a+b;
//f为输出,
//1bit全加器
module Add1
(
input a,
input b,
input C_in,
output f,
output g,
output p
);
assign g=a&b;
assign p=a|b;
assign f=a^b^C_in;
endmodule
//进位计算模块
module CLA_4(
input [3:0]P,
input [3:0]G,
input C_in,
output [4:1]Ci,
output Gm,
output Pm
);
assign Ci[1]=G[0]|P[0]&C_in;
assign Ci[2]=G[1]|P[1]&G[0]|P[1]&P[0]&C_in;
assign Ci[3]=G[2]|P[2]&G[1]|P[2]&P[1]&G[0]|P[2]&P[1]&P[0]&C_in;
assign Ci[4]=G[3]|P[3]&G[2]|P[3]&P[2]&G[1]|P[3]&P[2]&P[1]&G[0]|P[3]&P[2]&P[1]&P[0]&C_in;
assign Gm=G[3]|P[3]&G[2]|P[3]&P[2]&G[1]|P[3]&P[2]&P[1]&G[0];
assign Pm=P[3]&P[2]&P[1]&P[0];
endmoduleverilog语言采用门级描述方式,实现此4bit超前进位加法器
(输出,输入,输入)
`timescale 1ns/1ns
module lca_4(
input [3:0] A_in ,
input [3:0] B_in ,
input C_1 ,
output wire CO ,
output wire [3:0] S
);
wire [3:0]g,p,aaa;
wire [4:1]c;
and(g[0],A_in[0],B_in[0]);
and(g[1],A_in[1],B_in[1]);
and(g[2],A_in[2],B_in[2]);
and(g[3],A_in[3],B_in[3]);
xor(p[0],A_in[0],B_in[0]);
xor(p[1],A_in[1],B_in[1]);
xor(p[2],A_in[2],B_in[2]);
xor(p[3],A_in[3],B_in[3]);
and(aaa[0],p[0],C_1);
or(c[1],g[0],aaa[0]);
and(aaa[1],p[1],c[1]);
or(c[2],g[1],aaa[1]);
and(aaa[2],p[2],c[2]);
or(c[3],g[2],aaa[2]);
and(aaa[3],p[3],c[3]);
or(c[4],g[3],aaa[3]);
xor(S[0],p[0],C_1);
xor(S[1],p[1],c[1]);
xor(S[2],p[2],c[2]);
xor(S[3],p[3],c[3]);
assign CO=c[4];
//assign S=p^{c[3:1],C_1};
endmodule使用generate化简
`timescale 1ns/1ns
module lca_4(input [3:0] A_in,
input [3:0] B_in,
input C_1,
output wire CO,
output wire [3:0] S);
wire [3:0]g,p,aaa;
wire [4:1]c;
genvar i,j;
generate
for(i=0;i<=3;i=i+1)begin:and_bit
and(g[i],A_in[i],B_in[i]);
xor(p[i],A_in[i],B_in[i]);
end
endgenerate
generate
for(j=0;j<=3;j=j+1)begin:jieguo
if(j==0)begin
and(aaa[0],p[0],C_1);
or(c[1],g[0],aaa[0]);
xor(S[0],p[0],C_1);
end
else begin
and(aaa[j],p[j],c[j]);
or(c[j+1],g[j],aaa[j]);
xor(S[j],p[j],c[j]);
end
end
endgenerate
assign CO = c[4];
//assign S = p^{c[3:1],C_1};
endmodule

















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









