




基于深度学习的文本分类
一、学习目标:
- 学习FastText的使用和基础原理
- 学会使用验证集进行调参
二、文本表示方法 Part2:
1. 现有文本表示方法的缺陷:
除了上一篇介绍的方法知网,还有几种文本表示方法:
- One-hot
- Bag of Words
- N-gram
- TF-IDF
也通过sklean进行了相应的实践,相信你也有了初步的认知。但上述方法都或多或少存在一定的问题:转换得到的向量维度很高,需要较长的训练实践;没有考虑单词与单词之间的关系,只是进行了统计。
与这些表示方法不同,深度学习也可以用于文本表示,还可以将其映射到一个低纬空间。其中比较典型的例子有:FastText、Word2Vec和Bert。在本章我们将介绍FastText,将在后面的内容介绍Word2Vec和Bert。
2. FastText
FastText是一种典型的深度学习词向量的表示方法,它非常简单通过Embedding层将单词映射到稠密空间,然后将句子中所有的单词在Embedding空间中进行平均,进而完成分类操作。
所以FastText是一个三层的神经网络,输入层、隐含层和输出层。
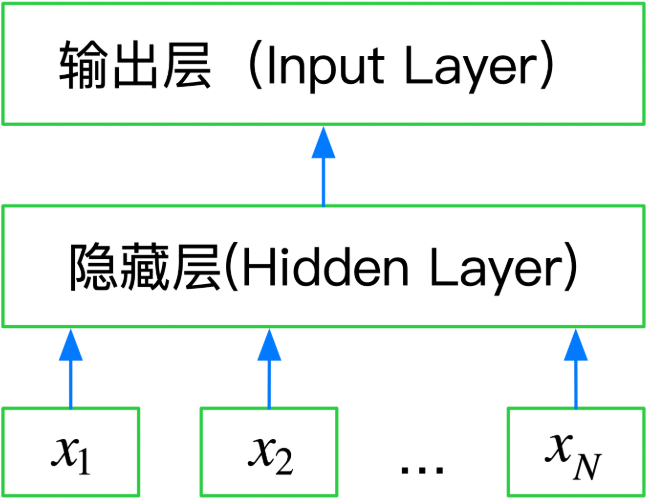
3. 基于FastText的文本分类:
#分类模型
import pandas as pd
from sklearn.metrics import f1_score
#转换为FastText需要的格式
train_df = pd.read_csv('./data/训练集数据/train_set.csv',sep='\t',nrows=50000)
train_df['label_ft'] = '__label__' + train_df['label'].astype(str)
train_df[['text','label_ft']].iloc[:-5000].to_csv('./data/train_fasttext.csv',index=None,header=None,sep='\t')
import fasttext
model = fasttext.train_supervised('./data/train_fasttext.csv',lr=1.0,wordNgrams=2,verbose=2,minCount=1,epoch=25,loss='hs')
val_pred = [model.predict(x)[0][0].split('__')[-1] for x in train_df.iloc[-5000:]['text']]
print(f1_score(train_df['label'].values[-5000:].astype(str),val_pred,average='macro'))结果:
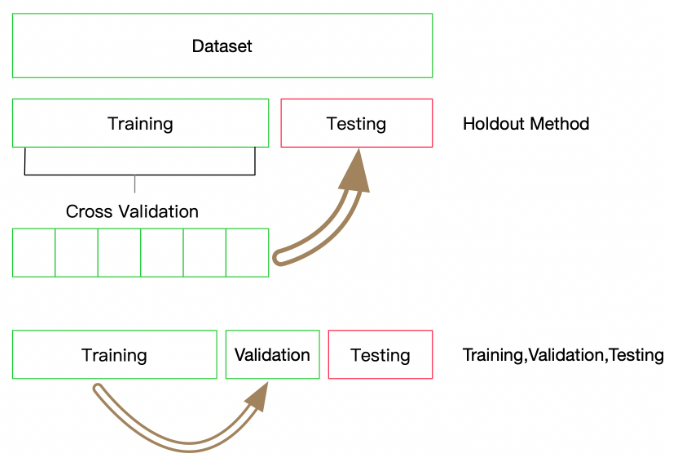
0.88956590284257154. 采用分层交叉验证:
这里我们使用10折交叉验证,每折使用9/10的数据进行训练,剩余1/10作为验证集检验模型的效果。这里需要注意每折的划分必须保证标签的分布与整个数据集的分布一致。
for lr in [0.5, 1, 1.5, 2.0]:
f1score_list = []
for train_index, test_index in skf.split(X, y):
# print("TRAIN:", train_index, "TEST:", test_index)
X_train, X_test = X[train_index], X[test_index]
y_train, y_test = y[train_index], y[test_index]
train_df = pd.DataFrame(pd.concat([X_train, y_train], axis=1), columns=['text', 'label'])
train_df['label_ft'] = '__label__' + train_df['label'].astype(str)
train_df[['text','label_ft']].to_csv('train.csv', index=None, header=None, sep='\t')
model = fasttext.train_supervised('train.csv', lr=lr, wordNgrams=3, verbose=2, minCount=1, epoch=25, loss="softmax")
val_pred = [model.predict(x)[0][0].split('__')[-1] for x in X_test]
f1score_list.append(f1_score(y_test.astype(str), val_pred, average='macro'))
print(lr, sum(f1score_list)/len(f1score_list))

















&spm=1001.2101.3001.5002&articleId=107623767&d=1&t=3&u=9ffc11c439e346dcbb74611243b3b835)
 3882
3882

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









