







 本文详细介绍了Pandas的三种数据结构——Series、DataFrame和MultiIndex,包括它们的创建、属性和常用操作。重点讲解了Series的索引和数据获取,DataFrame的行列操作、属性以及排序和统计计算。此外,还展示了如何在实际股票数据中应用这些操作,如索引、赋值、排序和统计分析。
本文详细介绍了Pandas的三种数据结构——Series、DataFrame和MultiIndex,包括它们的创建、属性和常用操作。重点讲解了Series的索引和数据获取,DataFrame的行列操作、属性以及排序和统计计算。此外,还展示了如何在实际股票数据中应用这些操作,如索引、赋值、排序和统计分析。
1,pandas数据结构
Pandas中一共有三种数据结构,分别为:Series、DataFrame和MultiIndex(老版本中叫Panel )。
其中Series是一维数据结构,DataFrame是二维的表格型数据结构,MultiIndex是三维的数据结构。
1.1 series
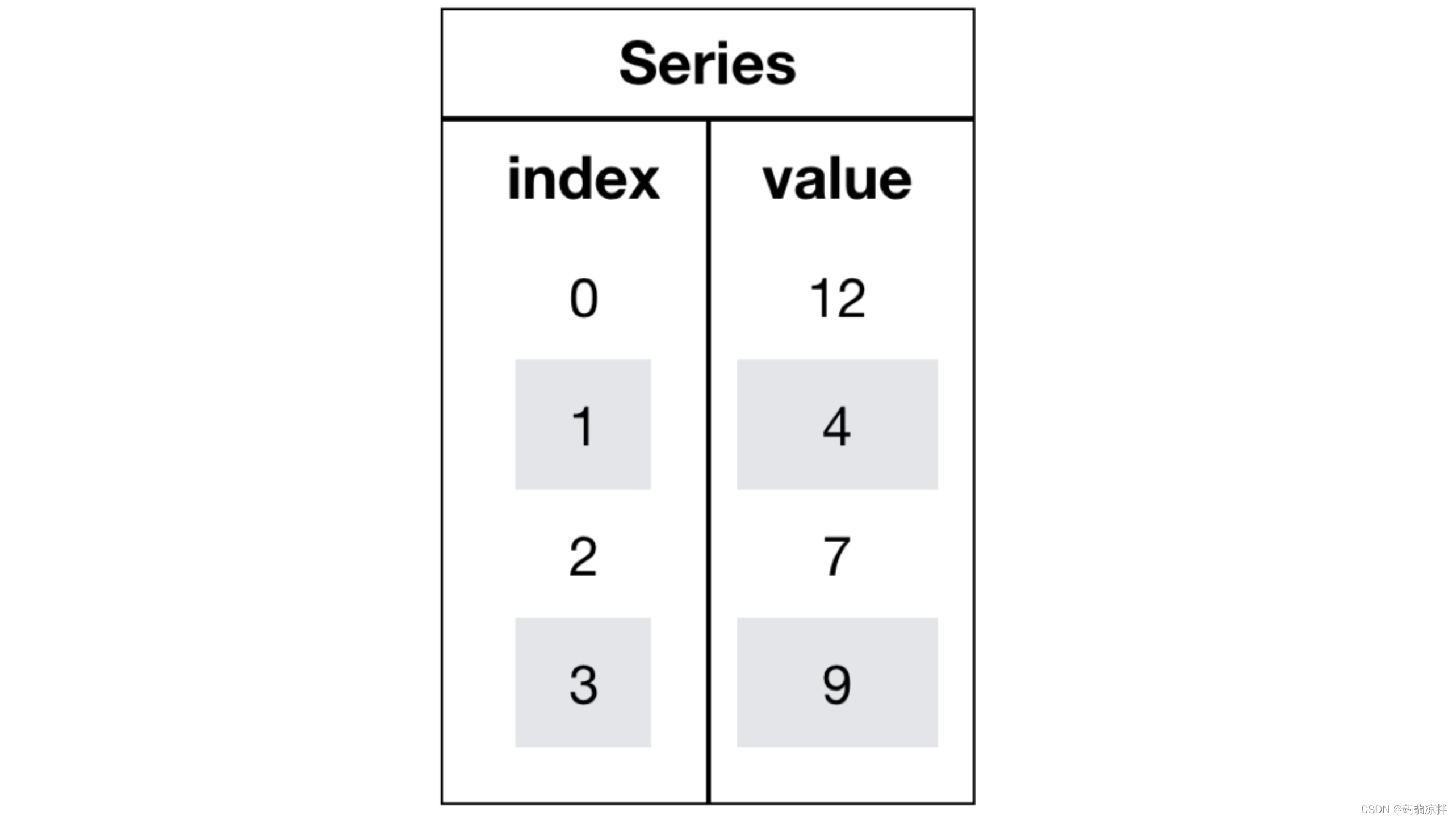
Series是一个类似于一维数组的数据结构,它能够保存任何类型的数据,比如整数、字符串、浮点数等,主要由一组数据和与之相关的索引两部分构成。
 # 导入pandas
# 导入pandas
import pandas as pd
pd.Series(data=None, index=None, dtype=None)
参数:
data:传入的数据,可以是ndarray、list等
index:索引,必须是唯一的,且与数据的长度相等。如果没有传入索引参数,则默认会自动创建一个从0-N的整数索引。
dtype:数据的类型
通过已有数据创建
指定内容,默认索引
pd.Series(np.arange(10))
运行结果
0 0
1 1
2 2
3 3
4 4
5 5
6 6
7 7
8 8
9 9
dtype: int64
指定索引
pd.Series([6.7,5.6,3,10,2], index=[1,2,3,4,5])
运行结果
1 6.7
2 5.6
3 3.0
4 10.0
5 2.0
dtype: float64
通过字典数据创建
color_count = pd.Series({‘red’:100, ‘blue’:200, ‘green’: 500, ‘yellow’:1000})
color_count
运行结果
blue 200
green 500
red 100
yellow 1000
dtype: int64
1.2 series的属性
Series中提供了两个属性index和values
index
color_count.index
结果
Index([‘blue’, ‘green’, ‘red’, ‘yellow’], dtype=‘object’)
values
color_count.values
结果
array([ 200, 500, 100, 1000])
也可以使用索引来获取数据:
color_count[2]
结果
100
1.2 DataFrame
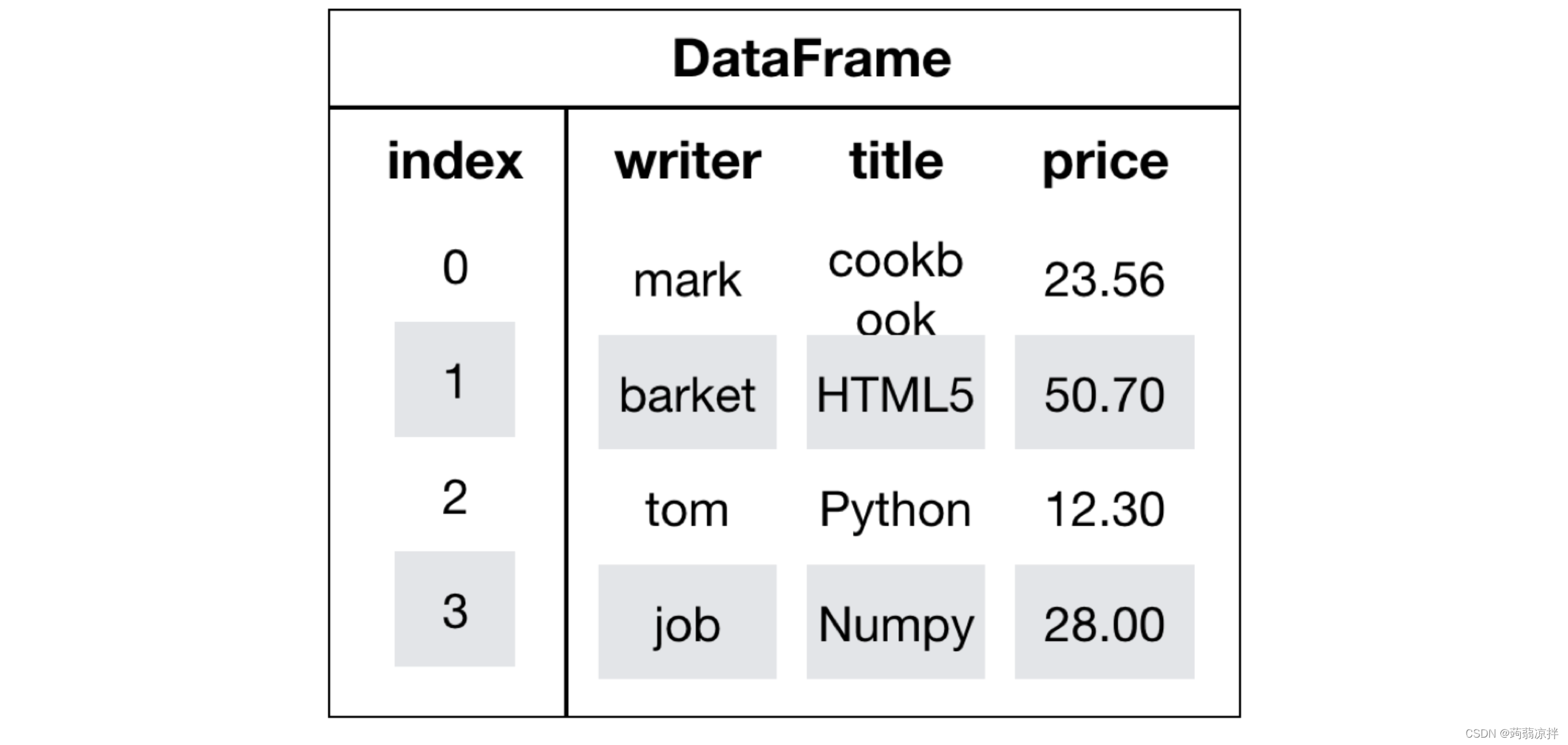
DataFrame是一个类似于二维数组或表格(如excel)的对象,既有行索引,又有列索引
行索引,表明不同行,横向索引,叫index,0轴,axis=0
列索引,表名不同列,纵向索引,叫columns,1轴,axis=1
# 导入pandas
import pandas as pd
pd.DataFrame(data=None, index=None, columns=None)
参数:
index:行标签。如果没有传入索引参数,则默认会自动创建一个从0-N的整数索引。
columns:列标签。如果没有传入索引参数,则默认会自动创建一个从0-N的整数索引。
通过已有数据创建
# 构造行索引序列
subjects = ["语文", "数学", "英语", "政治", "体育"]
# 构造列索引序列
stu = ['同学' + str(i) for i in range(score_df.shape[0])]
# 添加行索引
data = pd.DataFrame(score, columns=subjects, index=stu)
# dataframe属性
data.shape
# 结果
(10, 5)
data.index
# 结果
Index(['同学0', '同学1', '同学2', '同学3', '同学4', '同学5', '同学6', '同学7', '同学8', '同学9'], dtype='object')
data.columns
# 结果
Index(['语文', '数学', '英语', '政治', '体育'], dtype='object')
data.values
array([[92, 55, 78, 50, 50],
[71, 76, 50, 48, 96],
[45, 84, 78, 51, 68],
[81, 91, 56, 54, 76],
[86, 66, 77, 67, 95],
[46, 86, 56, 61, 99],
[46, 95, 44, 46, 56],
[80, 50, 45, 65, 57],
[41, 93, 90, 41, 97],
[65, 83, 57, 57, 40]])
# 转置
data.T
data.head(5) # 显示前5行内容
data.tail(5) # 显示后5行内容
# 修改行列索引值
stu = ["学生_" + str(i) for i in range(score_df.shape[0])]
# 必须整体全部修改
data.index = stu
# 重置索引,drop=False
data.reset_index() # drop:默认为False,不删除原来索引,如果为True,删除原来的索引值
以某列值设置为新的索引
set_index(keys, drop=True)
keys : 列索引名成或者列索引名称的列表
drop : boolean, default True.当做新的索引,删除原来的列
设置新索引案例
1、创建
df = pd.DataFrame({‘month’: [1, 4, 7, 10],
‘year’: [2012, 2014, 2013, 2014],
‘sale’:[55, 40, 84, 31]})
month sale year
0 1 55 2012
1 4 40 2014
2 7 84 2013
3 10 31 2014
2、以月份设置新的索引
df.set_index(‘month’)
sale year
month
1 55 2012
4 40 2014
7 84 2013
10 31 2014
3、设置多个索引,以年和月份
df = df.set_index([‘year’, ‘month’])
df
sale
year month
2012 1 55
2014 4 40
2013 7 84
2014 10 31
注:通过刚才的设置,这样DataFrame就变成了一个具有MultiIndex的DataFrame。
1.3 MultiIndex与Panel
MultiIndex是三维的数据结构;
多级索引(也称层次化索引)是pandas的重要功能,可以在Series、DataFrame对象上拥有2个以及2个以上的索引。
arrays = [[1, 1, 2, 2], ['red', 'blue', 'red', 'blue']]
pd.MultiIndex.from_arrays(arrays, names=('number', 'color'))
# 结果
MultiIndex(levels=[[1, 2], ['blue', 'red']],
codes=[[0, 0, 1, 1], [1, 0, 1, 0]],
names=['number', 'color'])
panel的创建
class pandas.Panel(data=None, items=None, major_axis=None, minor_axis=None)
作用:存储3维数组的Panel结构
参数:
data : ndarray或者dataframe
items : 索引或类似数组的对象,axis=0
major_axis : 索引或类似数组的对象,axis=1
minor_axis : 索引或类似数组的对象,axis=2
p = pd.Panel(data=np.arange(24).reshape(4,3,2),
items=list('ABCD'),
major_axis=pd.date_range('20130101', periods=3),
minor_axis=['first', 'second'])
# 结果
<class 'pandas.core.panel.Panel'>
Dimensions: 4 (items) x 3 (major_axis) x 2 (minor_axis)
Items axis: A to D
Major_axis axis: 2013-01-01 00:00:00 to 2013-01-03 00:00:00
Minor_axis axis: first to second
p[:,:,"first"]
p["B",:,:]
注:Pandas从版本0.20.0开始弃用:推荐的用于表示3D数据的方法是通过DataFrame上的MultiIndex方法
2,基本数据结构
通过一个真实的股票数据理解基本操作。
# 读取文件
data = pd.read_csv("./data/stock_day.csv")
# 删除一些列,让数据更简单些,再去做后面的操作
data = data.drop(["ma5","ma10","ma20","v_ma5","v_ma10","v_ma20"], axis=1)
1)索引操作
1.1 直接使用行列索引(先列后行)
获取’2018-02-27’这天的’close’的结果
# 直接使用行列索引名字的方式(先列后行)
data['open']['2018-02-27']
23.53
# 不支持的操作
# 错误
data['2018-02-27']['open']
# 错误
data[:1, :2]
1.2 结合loc或者iloc使用索引
获取从’2018-02-27’:‘2018-02-22’,'open’的结果
# 使用loc:只能指定行列索引的名字
data.loc['2018-02-27':'2018-02-22', 'open']
2018-02-27 23.53
2018-02-26 22.80
2018-02-23 22.88
Name: open, dtype: float64
# 使用iloc可以通过索引的下标去获取
# 获取前3天数据,前5列的结果
data.iloc[:3, :5]
open high close low
2018-02-27 23.53 25.88 24.16 23.53
2018-02-26 22.80 23.78 23.53 22.80
2018-02-23 22.88 23.37 22.82 22.71
1.3 使用ix组合索引
获取行第1天到第4天,[‘open’, ‘close’, ‘high’, ‘low’]这个四个指标的结果
# 使用ix进行下表和名称组合做引
data.ix[0:4, ['open', 'close', 'high', 'low']]
# 推荐使用loc和iloc来获取的方式
data.loc[data.index[0:4], ['open', 'close', 'high', 'low']]
data.iloc[0:4, data.columns.get_indexer(['open', 'close', 'high', 'low'])]
open close high low
2018-02-27 23.53 24.16 25.88 23.53
2018-02-26 22.80 23.53 23.78 22.80
2018-02-23 22.88 22.82 23.37 22.71
2018-02-22 22.25 22.28 22.76 22.02
2)赋值操作
对DataFrame当中的close列进行重新赋值为1
# 直接修改原来的值
data['close'] = 1
# 或者
data.close = 1
3)排序
排序有两种形式,一种对于索引进行排序,一种对于内容进行排序
3.1 DataFrame排序
使用df.sort_values(by=, ascending=)
单个键或者多个键进行排序,
参数:
by:指定排序参考的键
ascending:默认升序
ascending=False:降序
ascending=True:升序
# 按照开盘价大小进行排序 , 使用ascending指定按照大小排序
data.sort_values(by="open", ascending=True).head()
# 按照多个键进行排序
data.sort_values(by=['open', 'high'])
使用df.sort_index给索引进行排序
这个股票的日期索引原来是从大到小,现在重新排序,从小到大
# 对索引进行排序
data.sort_index()
3.2 Series排序
使用series.sort_values(ascending=True)进行排序
series排序时,只有一列,不需要参数
data['p_change'].sort_values(ascending=True).head()
2015-09-01 -10.03
2015-09-14 -10.02
2016-01-11 -10.02
2015-07-15 -10.02
2015-08-26 -10.01
Name: p_change, dtype: float64
使用series.sort_index()进行排序
与df一致
# 对索引进行排序
data['p_change'].sort_index().head()
2015-03-02 2.62
2015-03-03 1.44
2015-03-04 1.57
2015-03-05 2.02
2015-03-06 8.51
Name: p_change, dtype: float64
4,DataFrame运算
1)算术运算
add(other)
比如进行数学运算加上具体的一个数字
data[‘open’].add(1)
2018-02-27 24.53
2018-02-26 23.80
2018-02-23 23.88
2018-02-22 23.25
2018-02-14 22.49
sub(other)'
2)逻辑运算
2.1 逻辑运算符号
例如筛选data["open"] > 23的日期数据
data["open"] > 23返回逻辑结果
data["open"] > 23
2018-02-27 True
2018-02-26 False
2018-02-23 False
2018-02-22 False
2018-02-14 False
# 逻辑判断的结果可以作为筛选的依据
data[data["open"] > 23].head()
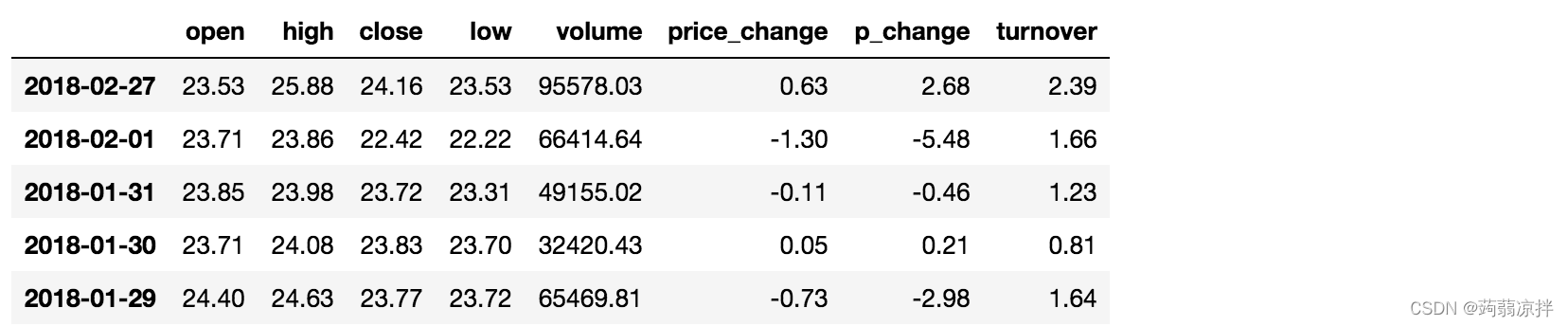
完成多个逻辑判断,
data[(data["open"] > 23) & (data["open"] < 24)].head()
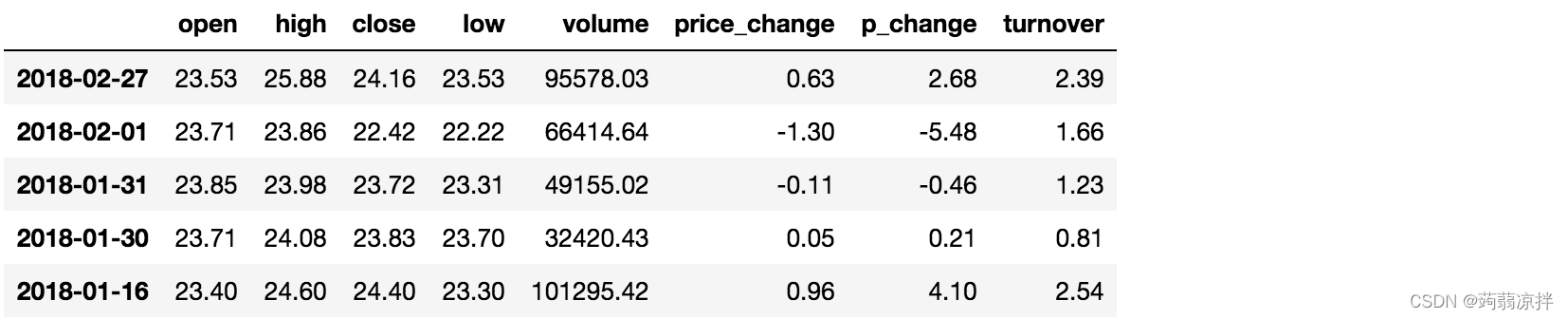 2.2 逻辑运算函数
2.2 逻辑运算函数
query(expr)
expr:查询字符串
通过query使得刚才的过程更加方便简单data.query("open<24 & open>23").head()
isin(values)
例如判断’open’是否为23.53和23.85
# 可以指定值进行一个判断,从而进行筛选操作
data[data["open"].isin([23.53, 23.85])]
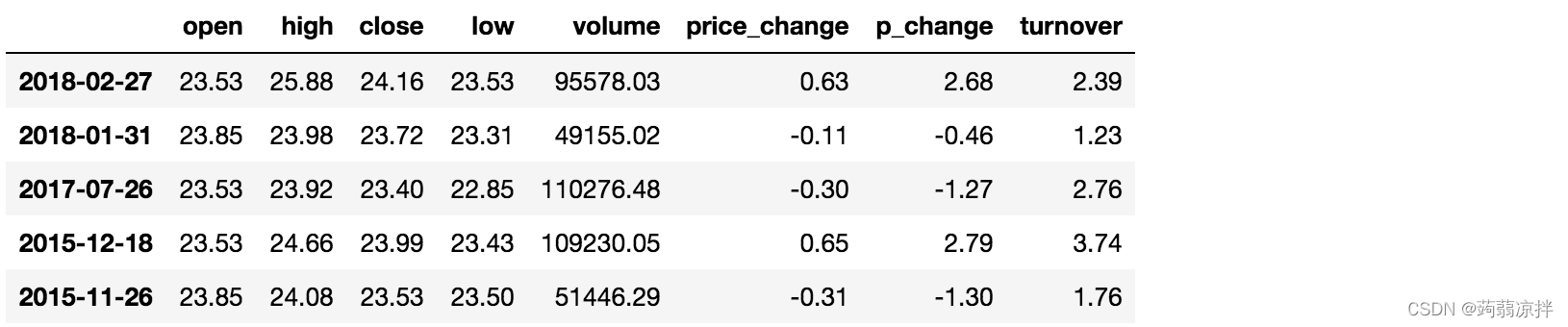
3)统计运算
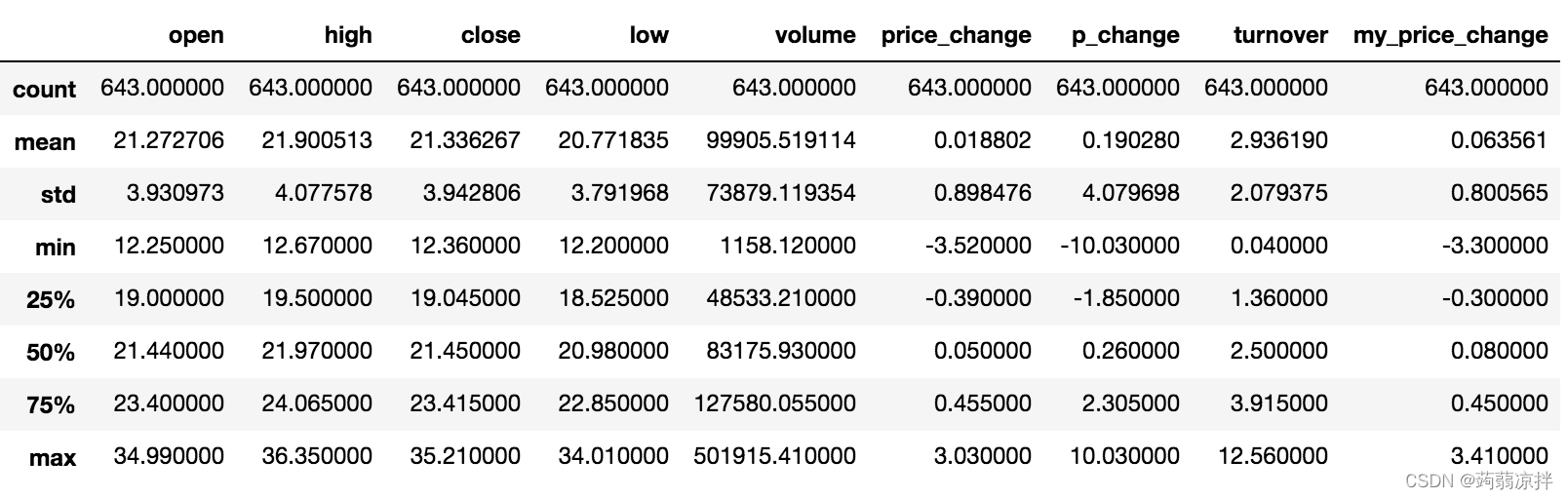
3.1 describe
综合分析: 能够直接得出很多统计结果,count, mean, std, min, max 等
# 计算平均值、标准差、最大值、最小值
data.describe()
3.2 统计函数
Numpy当中已经详细介绍,在这里我们演示min(最小值), max(最大值), mean(平均值), median(中位数), var(方差), std(标准差),mode(众数)结果:
对于单个函数去进行统计的时候,坐标轴还是按照默认列“columns” (axis=0, default),如果要对行“index” 需要指定(axis=1)
max()、min()
# 使用统计函数:0 代表列求结果, 1 代表行求统计结果
data.max(0)
open 34.99
high 36.35
close 35.21
low 34.01
volume 501915.41
price_change 3.03
p_change 10.03
turnover 12.56
my_price_change 3.41
dtype: float64
std()、var()
# 方差
data.var(0)
open 1.545255e+01
high 1.662665e+01
close 1.554572e+01
low 1.437902e+01
volume 5.458124e+09
price_change 8.072595e-01
p_change 1.664394e+01
turnover 4.323800e+00
my_price_change 6.409037e-01
dtype: float64
# 标准差
data.std(0)
open 3.930973
high 4.077578
close 3.942806
low 3.791968
volume 73879.119354
price_change 0.898476
p_change 4.079698
turnover 2.079375
my_price_change 0.800565
dtype: float64
median():中位数
中位数为将数据从小到大排列,在最中间的那个数为中位数。如果没有中间数,取中间两个数的平均值。
df = pd.DataFrame({'COL1' : [2,3,4,5,4,2],
'COL2' : [0,1,2,3,4,2]})
df.median()
COL1 3.5
COL2 2.0
dtype: float64
idxmax()、idxmin()
# 求出最大值的位置
data.idxmax(axis=0)
open 2015-06-15
high 2015-06-10
close 2015-06-12
low 2015-06-12
volume 2017-10-26
price_change 2015-06-09
p_change 2015-08-28
turnover 2017-10-26
my_price_change 2015-07-10
dtype: object
# 求出最小值的位置
data.idxmin(axis=0)
open 2015-03-02
high 2015-03-02
close 2015-09-02
low 2015-03-02
volume 2016-07-06
price_change 2015-06-15
p_change 2015-09-01
turnover 2016-07-06
my_price_change 2015-06-15
dtype: object
3.3 累计统计函数
| 函数 | 作用 |
|---|---|
| cumsum | 计算前1/2/3/…/n个数的和 |
| cummax | 计算前1/2/3/…/n个数的最大值 |
| cummin | 计算前1/2/3/…/n个数的最小值 |
| cumprod | 计算前1/2/3/…/n个数的积 |
以上这些函数可以对series和dataframe操作
这里我们按照时间的从前往后来进行累计
排序
# 排序之后,进行累计求和
data = data.sort_index()
对p_change进行求和
stock_rise = data['p_change']
# plot方法集成了前面直方图、条形图、饼图、折线图
stock_rise.cumsum()
2015-03-02 2.62
2015-03-03 4.06
2015-03-04 5.63
2015-03-05 7.65
2015-03-06 16.16
2015-03-09 16.37
2015-03-10 18.75
2015-03-11 16.36
2015-03-12 15.03
2015-03-13 17.58
2015-03-16 20.34
2015-03-17 22.42
2015-03-18 23.28
2015-03-19 23.74
2015-03-20 23.48
2015-03-23 23.74
import matplotlib.pyplot as plt
# plot显示图形
stock_rise.cumsum().plot()
# 需要调用show,才能显示出结果
plt.show()
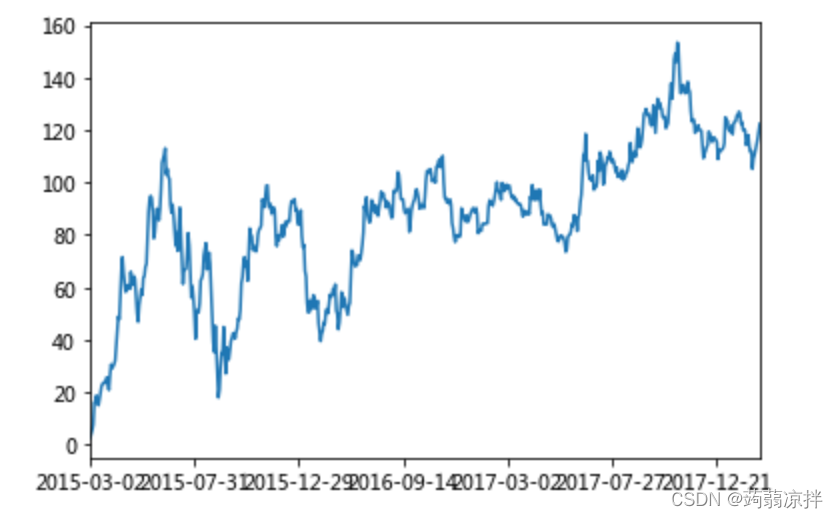
4)自定义运算
apply(func, axis=0)
func:自定义函数
axis=0:默认是列,axis=1为行进行运算
定义一个对列,最大值-最小值的函数
data[['open', 'close']].apply(lambda x: x.max() - x.min(), axis=0)
open 22.74
close 22.85
dtype: float64

















 3803
3803

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









