




 本文深入解析YOLO系列目标检测算法,从YOLOv1的预测和训练阶段,探讨批量标准化、高分辨率分类器等改进。接着介绍YOLOv2的Batch Normalization、高分辨率分类器、先验框等创新,以及YOLOv3的网络结构和多尺度预测。通过对损失函数的讨论,展示了YOLO系列算法的发展和优化。
本文深入解析YOLO系列目标检测算法,从YOLOv1的预测和训练阶段,探讨批量标准化、高分辨率分类器等改进。接着介绍YOLOv2的Batch Normalization、高分辨率分类器、先验框等创新,以及YOLOv3的网络结构和多尺度预测。通过对损失函数的讨论,展示了YOLO系列算法的发展和优化。
本文的资料来自于多方面网络内容,包含个人见解和资料整理。
Yolov1:
一.预测阶段
(1)前阶段
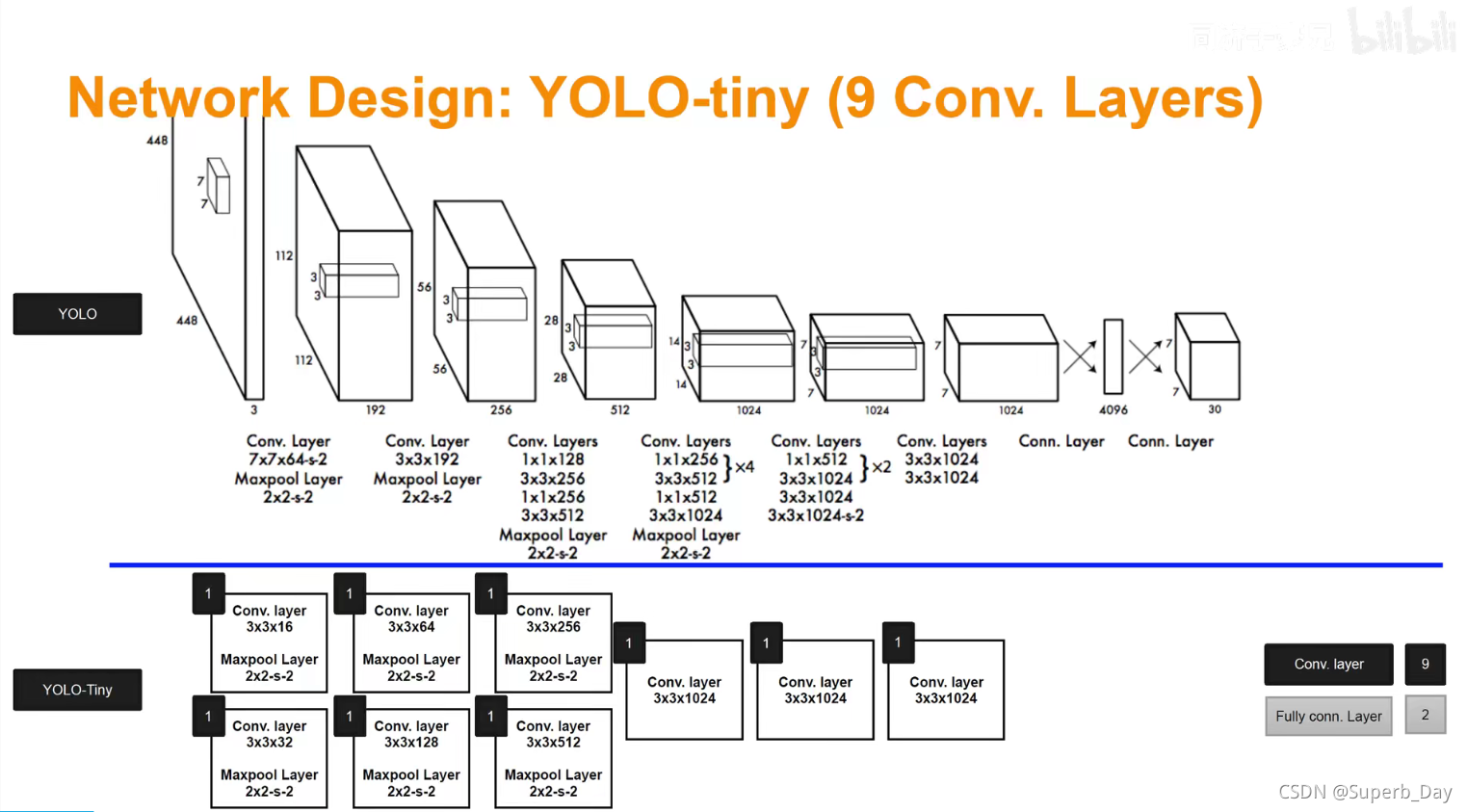
上面为yolov1 标准,下面为yolov1快速版本。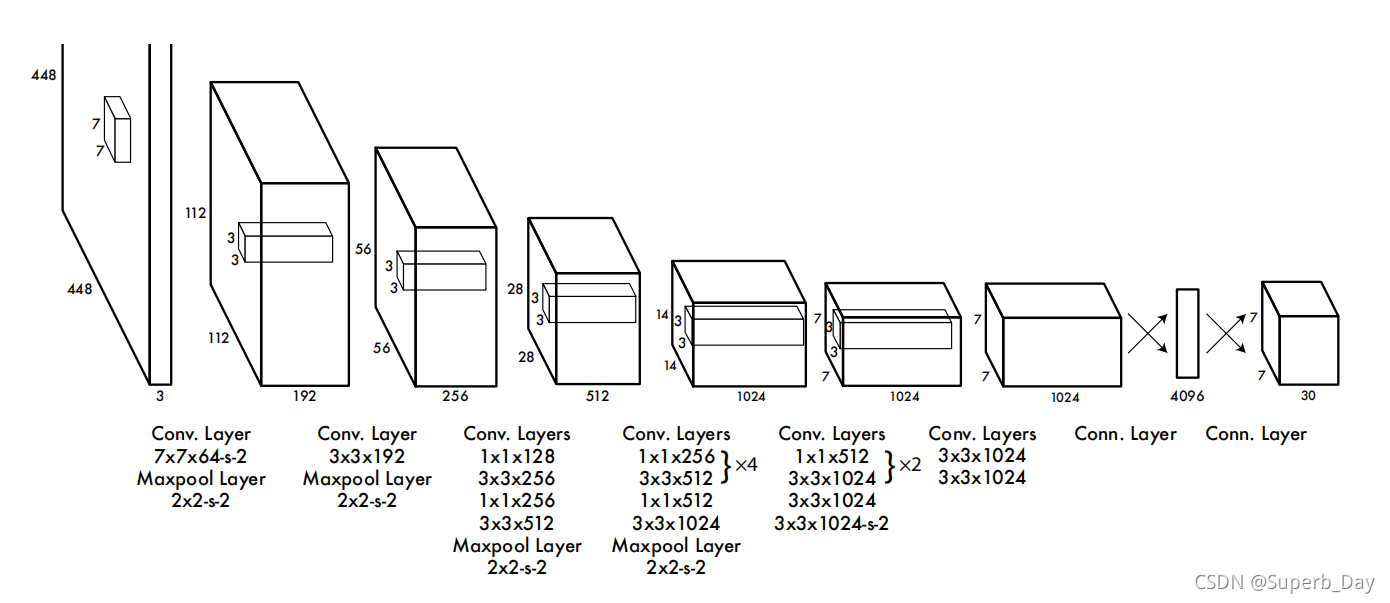
1.输入必须缩放调整为正方形,像素为448*448,3代表3通道RGB。
2.Conv.Layer7*7*64-s-2的意思是卷积框为7*7,卷积核filter为64,s代表stride参数。Maxpool.Layer的意思是池化层。
原图式:n x n
卷积核: f x f
padding(边框补充): p
stride :s 此处s=2
输出图像像素表达式:[(n+2p-f)/s +1] x [(n+2p-f)/s +1]
如果计算出不是整数,则向下取整
3.数学中的卷积是需要翻转的,但是深度学习中的卷积不需要翻转。
4.图片的长宽比例越缩越小的原因是卷积层和池化层步长为2的原因,比如448/2/2=112。越来越厚的原因是卷积核形成层数很多,比如64*3=192。
5.经过一系列操作之后,得到了一个7*7*1024的数据,然后拉平放入一个有4096个神经元的全连接层中,输出4096维的向量,然后又导入有1470个神经元的全连接层中,输出1470维的向量,然后改变一下形式,变成最后的7*7*30。
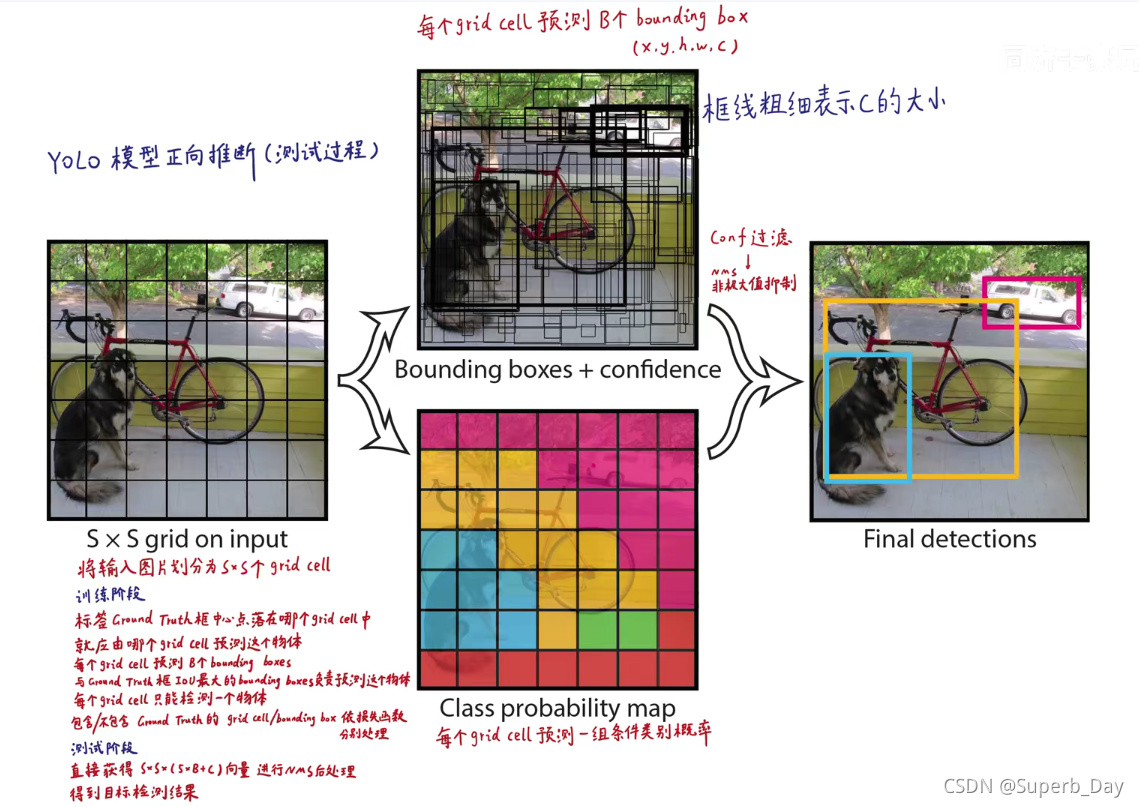
1.在yolov1中,boundingbox一般为两个。
2.boundingbox的五维参数代表(中心点x坐标,中心点y坐标,预测框高度h,预测框宽度w,置信度c)
3.

我们需要选择出每一个网格中置信度最高的那个预测框来作为候选的框。
4.真实框落在哪个grid cell里面,由这个grid cell里的B(多数情况B=2)个bounding box里的最优框来预测这个物体,不是bounding box自己找自己最大匹配的真实框,而是真实框指派一个grid cell给他一个最好的bounding box

1.每个图生成20个条件概率,也就是属于20个类别的可能性
2.条件概率是yolo经过卷积池化提取的高级语义特征经过全连接层得到的,一个图像经过多次卷积和池化会得到图像的高级语义信息(有的就包括它是什么类别啥的)

1.每个grid cell通过运算只保留最可能的类别,也就是说
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









