







 本文介绍了SLAM中的运动方程和观测方程,以及如何利用最大似然估计来求解位姿。通过非线性优化方法,如高斯-牛顿法和列文伯格-马夸尔特方法,解决状态估计问题。主要内容包括理解贝叶斯法则,最小二乘法的引出,以及一阶和二阶梯度法在求解SLAM问题中的应用。
本文介绍了SLAM中的运动方程和观测方程,以及如何利用最大似然估计来求解位姿。通过非线性优化方法,如高斯-牛顿法和列文伯格-马夸尔特方法,解决状态估计问题。主要内容包括理解贝叶斯法则,最小二乘法的引出,以及一阶和二阶梯度法在求解SLAM问题中的应用。
一、首先理解运动方程和观测方程
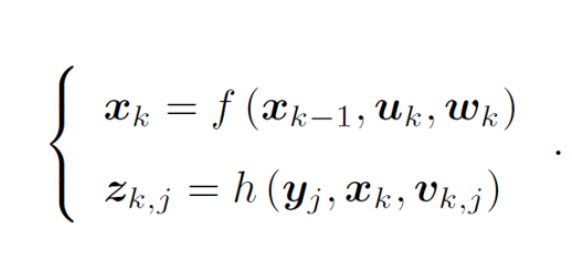
(1)运动方程: x表示相机的位姿,每个时刻位姿记为x1, x2...... xk,构成了运动的轨迹。uk 是传感器的输入;wk 是噪声,假设噪声服从高斯分布。
运动方程的意义是: k-1 到 k 时刻,机器人位姿x 是如何变化的。 SLAM中的定位问题就是估计 x的值。
区分位姿和位置:
位姿代表位置和姿态。任何一个刚体在空间坐标系(OXYZ)中,可以用位置和姿态来精确、唯一表示其位置状态。
位姿是六自由的量,包括旋转和平移;位置是三维的量,表示具体位置(X,Y,Z)
(2)观测方程:y是路标点,地图是由路标组成的,相机每个时刻都会观测部分路标点,从而得到观测数据; 是位于时
对路标
观测时得到噪声,也假设它服从高斯分布。
观测方程的意义时; k时刻,机器人位于 处观测到一个路标点
,得到的了观测数据 z。SLAM中的建图问题时估计 y 的值。
总结: x和y 是需要求的未知量,其余的都是已知量,求解x和y 构成了一个状态估计问题。
二、解决状态估计问题有两种方法
(1)增量/渐进/滤波器 (ch9内容)
(2)批量处理。
sfM(Structure From Motion)是从一系列包含视觉运动信息的多幅二维图像序列中估计三维结构的技术。
两种方法都用一定的不足,采用折衷的方法——滑动窗口估计法。
三、以非线性优化为主的批量方法
贝叶斯法则 : p( x | z) = ( p (z | x) p (x) ) / p (z)
p( x | z) 后验概率 观察到 z 的情况下,x 自身的概率
p (z | x) 似然 在 x 的情况下, 观察到z的概率
p (x) 先验 在没有观察 z 的情况下 ,x 自身的概率
x 是一种假设 , z 是一种观察结果
直接求后验概率是苦难的,有两种方法
(1)如果由先验信息,求解最大后验概率(MAP),
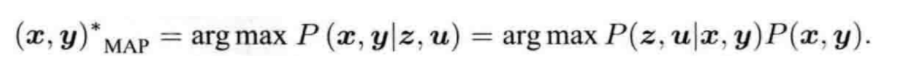
由公式得出,求最大后验概率等价于 最大似然 和 先验 的乘积。
这里关于 arg max 和 arg min 的笔记
arg min 就是使后面这个式子达到最小值时的变量的取值
arg max 就是使后面这个式子达到最大值时的变量的取值
例如 函数F(x,y):
arg min F(x,y)就是指当F(x,y)取得最小值时,变量x,y的取值
arg max F(x,y)就是指当F(x,y)取得最大值时,变量x,y的取值
(2)如果没有先验信息,求解最大似然估计(MLE),
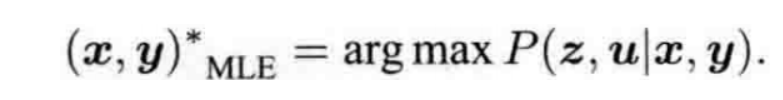
似然是指 在当前位姿下,可能产生什么样的观测数据。
观测数据是已知的,因此最大似然估计理解为: 在什么样的位姿下,最可能产生观测到的数据。
卡尔曼滤波的过程,用运动方程找到先验,用观测方程找到最大似然,最终找到后验。
到现在状态估计问题变成了求最大似然估计
看到这里需要了解一些高斯分布的性质: (尤其是下面第二张图片内容)


继续书看书中内容, ( 6.1.2 最小二乘的引出 )
因为从运动方程和观测方程可以看出u,z相互独立,这里先讨论 P ( |
,
)
P ( |
,
)
~ N (0,
)
所以观测数据的条件概率为:
![]()
参考上面高斯分布性质的第二张图片 , 自己推一下。
高维高斯分布的概率密度函数为;
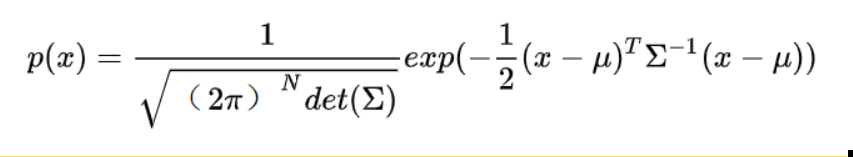
对它取负对数,
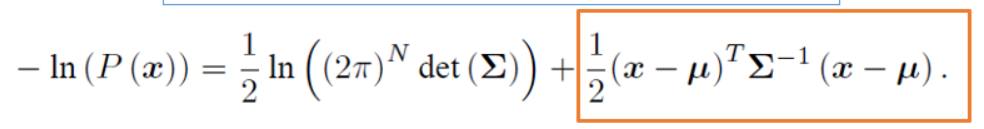
根据公式 :前一项的大小和 x 无关,不考虑, 我们只要最小化后一项,就使得 P(x) 最大。
带入SLAM的观测模型:
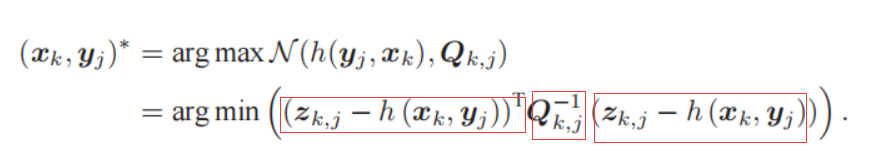
这里拆成三部分再和上一个公式比对着看就理解了。
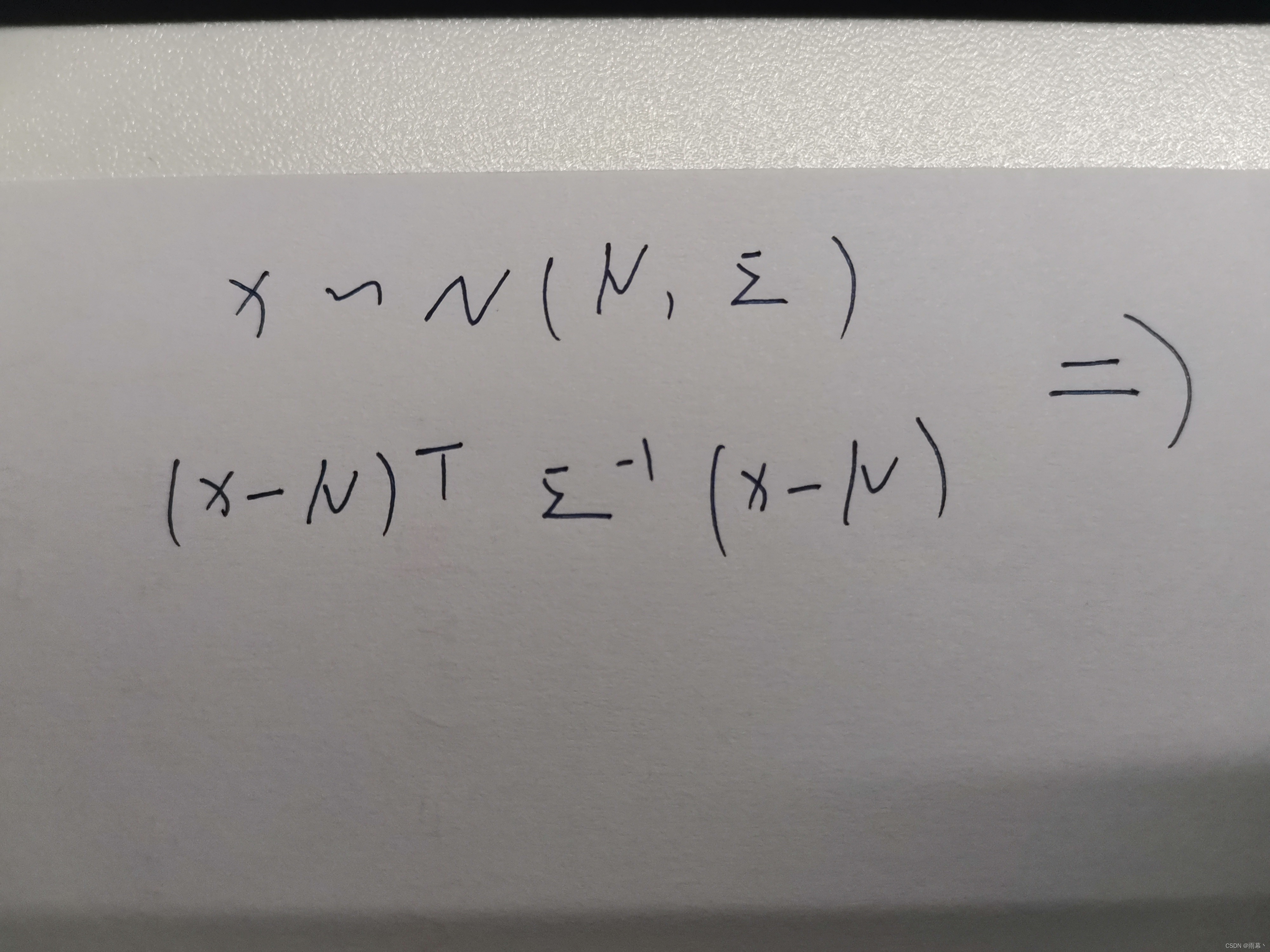
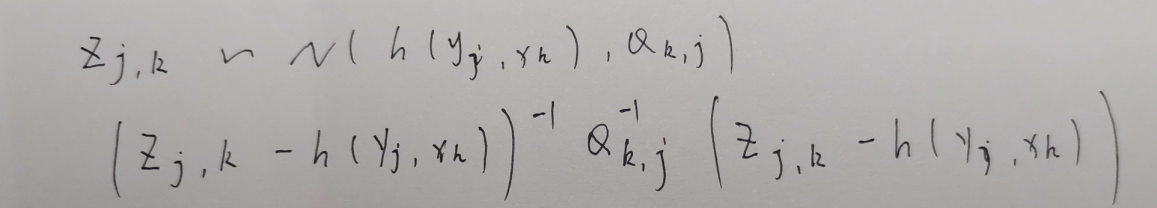
或者看我写的内容来理解
可以发现,该公式等价于最小化噪声项(重投影误差)的一个二次型。(二次型称为马氏距离, 称为信息矩阵)。

现在讨论完整的P(z, u | x, y) ,由于z,u相互独立,我们可以将联合概率分布因式分解:
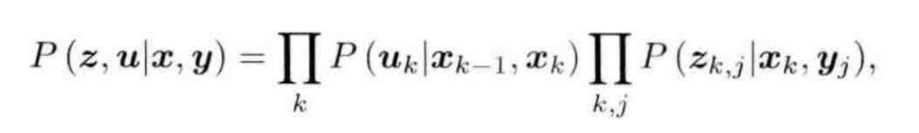
定义输入误差项和观测误差项后,我们发现最小化估计值与真实数据的马氏距离,等价于求最大似然估计。
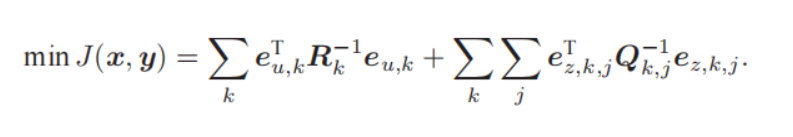
我们又将最大似然估计问题转化成了最小二乘问题。
物理意义:通过视觉里程计我们获得的一段时间内的相机位姿和一定范围的地图,但是将这些数据带入运动方程和观测方程,总会多多少少存在一些误差,于是我们对这些数据进行微调,使总体误差达到最小,这时我们就得到了整体数据的最大似然估计。
这个SLAM问题的最小二乘问题还存在一些特殊结构:
- 每个误差项仅与以两个状态变量有关,这形成了整个最小二乘问题的稀疏结构。
- 如果采用李代数表示增量,这就是无约束的最小二乘问题,使得优化更加容易,这也是我们引入李代数的目的所在。
- 我们使用二次型度量误差,观测准确的数据的误差项的信息矩阵会很大,在整个问题中反而占有较大的比重。因此观测准确的数据容易收到观测不准的数据的“拖累”,所以我们后面要引入鲁棒核函数。
关于6.1.3 例子:批量状态估计
125页内容还可以看懂,到126页就在看天书了,不过找到了大佬的笔记 。链接
看的时候直接往下找到这部分内容就行。
四、非线性最小二乘 (求它的最小值)
1.一阶和二阶梯度法
推导过程参考高博书,就不赘述了。这里总结下它们的优缺点。
一阶(最速下降法):过于贪心,反而容易增加迭代次数,使收敛变慢。
二阶(牛顿法):求解海塞矩阵H,但这十分困难。
2.高斯牛顿法
高斯牛顿法的思想:高斯牛顿法针对最小二乘问题,采用一定的方法对牛顿法中的海塞矩阵H () 进行近似,从而简化了计算量。
注意:只有最小二乘问题才能使用高斯牛顿法
高斯牛顿法中的J () 是 f(x) 关于 x 的一阶导数在
处取值
高斯法中的J () 是 目标函数F(x) 关于 x 的一阶导数在
处取值
缺点:
计算时需要对 H(x) 矩阵求逆,因此 H 必须可逆,但是实际计算中计算得到的 H 可能为奇异矩阵或病态矩阵。
奇异矩阵:不满秩的方阵
病态矩阵:求解方程组时如果对数据进行较小的扰动,则得出的结果具有很大波动,这样的矩阵称为病态矩阵。
3.列文伯格——马夸尔特方法
与高斯牛顿相比:
列文伯格-马夸尔特在一定程度上解决了线性方程组系数矩阵的非奇异和病态问题,但算法收敛速度相较于高斯牛顿更慢。
因此,当问题性质较好时,选择高斯牛顿方法,问题接近病态时,选择列文伯格-马夸尔特方法。
高斯牛顿法和列文伯格——马夸尔特法最优化计算时都需要提供变量的初值,不能随意设置。在SLAM中,用ICP和PnP之类的算法(ch7 会出现)提供优化初始值。
总结:
首先是想通过最大似然估计来求位姿,最大似然就等同于最小化负对数;把观测方程和状态方程代入进去,这个负对数函数就是要优化的函数,要最小的函数值,就是求它的极小点,求的方式就是线搜索方法(line search)或者信赖区域(trust region)方式,line search有梯度下降法(包括一阶的最速下降法和二阶的牛顿法,前者直观但是太贪心,后者直观但是得算H矩阵)和高斯牛顿法(用J和自身转置的乘积来代替H矩阵)。trust region主要是列文伯格——马夸尔特方法,避免非奇异性问题,但是收敛较慢。
在非线性优化的过程中,目标函数作为想要优化的结果,这个函数的自变量x,其实就是位姿R、t。
因此,上面式子中的x,就可以当做位姿,我们可以这么理解:在这个位姿下,对它进行△x的修正,使得目标函数也就是误差最小了,然后把位姿更新成x+△x。正常来说,y=f(x),我们想知道y的极小值,求的应该是直接去求关于x的导数,在导数为0处是f(x)极小值,目标函数也就是误差值最小,对吧?,那这求△x是干什么呢?
这恰恰就是这章独特、精髓之处。实际的数据是有误差的,是想要根据很多有误差和噪声的数据,最后求得一个最合适的位姿,让平均的误差最小。用f(x)直接对x求导,是非常不方便的!因此采用f(x+△x)的形式,不断沿着梯度下降的方向走,迭代更新x,从而计算使得目标函数最小的x值。
这章的缺陷在于,不知道这是在干什么,实际上这是后面大部分内容的基础,建议配合光度误差和重投影误差的内容去阅读。对于雅克比矩阵的理解,通过误差函数算雅克比矩阵,算出雅克比矩阵才能套在上面的非线性优化的地方求出△x,进一步实现x+△x的更新。看完这个,才能真正明白这节的非线性优化内容是干什么的,否则肯定是看了就忘,不理解含义。另外,在后端,这部分也会被反复提及和使用。
参考文章:

















 516
516

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









