




文章目录
数值稳定性
当神经网络的深度比较深时,非常容易数值不稳定。
不稳定梯度是指神经网络反向传播过程中,梯度出现极端数值的现象。
假设有一个d层的神经网络,每一层的变化定义为 f t f_t ft,该变换的权重参数为 W ( t ) W^{(t)} W(t),将第t-1层的输出 h t − 1 h^{t-1} ht−1作为输入传到第t层 f t f_t ft得到第t层的输出 h t = f t ( h t − 1 ) h^t = f_t(h^{t-1}) ht=ft(ht−1)。
计算损失关于参数 W t W_t Wt的梯度,从第d层反向传播到第t层会进行d-t次的矩阵乘法,会带来两个常见的问题①梯度爆炸 ②梯度消失

梯度消失
梯度消失:参数更新过小,在每次更新时几乎不会移动,导致模型无法学习。
若每层的局部梯度 ∣ ∂ h d ∂ h d − 1 ∣ < 1 ∣\frac{∂h^d}{∂h^{d-1}}∣<1 ∣∂hd−1∂hd∣<1,梯度会指数级衰减。
梯度消失的问题
- 底层参数几乎不更新: Δ w ≈ 0 Δw≈0 Δw≈0
- 训练停滞:损失函数长期不下降,不管如何选择学习了率
- 底层无法学习有效特征,仅顶部层训练较好,无法让神经网络更深。
梯度反向传播从顶部开始往底部传,传到后面梯度越来越小,学习效果越来越差。
Sigmoid作为激活函数
σ ( x ) = 1 1 + e − x , σ ′ ( x ) = σ ( x ) ( 1 − σ ( x ) ) \sigma(x)=\frac{1}{1+e^{-x}},\sigma'(x)=\sigma(x)(1-\sigma(x)) σ(x)=1+e−x1,σ′(x)=σ(x)(1−σ(x))
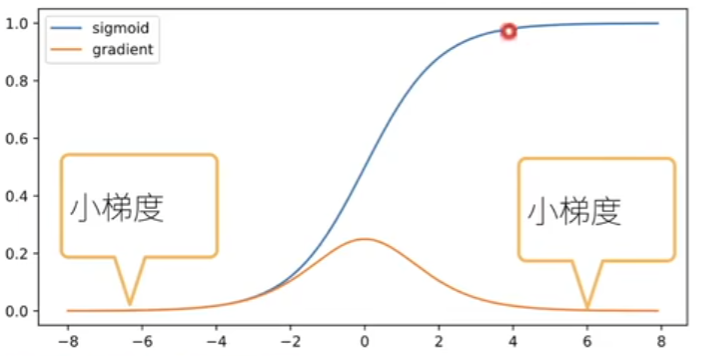
案例说明
对于第 l l l 层的前向传播流程
- 接收输入: z [ l − 1 ] z^{[l−1]} z[l−1]
- 线性变换: a [ l ] = W [ l ] z [ l − 1 ] + b [ l ] a^{[l]}=W^{[l]}z^{[l−1]}+b^{[l]}
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1326
1326

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









