 HDFS存储优化:纠删码与异构存储实战教程
HDFS存储优化:纠删码与异构存储实战教程




文章目录
HDFS-存储优化
环境准备
演示纠删码和异构存储需要一共 5 台虚拟机
首先我们需要把之前的演示的hadoop105从黑名单中放出来,然后根据hadoop105克隆一台hadoop106。
这里使用我们之前使用的5台虚拟机,所以有些地方需要修改
1 修改IP和主机名
网卡地址: /etc/sysconfig/network-scripts/ifcfg-ens33
修改主机名地址: /etc/hostname
[ranan@hadoop105 ~]$ sudo vim /etc/sysconfig/network-scripts/ifcfg-ens33
IPADDR=192.168.10.106
[ranan@hadoop105 ~]$ sudo vim /etc/hostname
hadoop106
2 删除data/ logs/
这里我们依次删除之前的 data/ logs/ ,清空集群数据
[ranan@hadoop106 hadoop-3.1.3]$ rm -rf data/ logs/
[ranan@hadoop105 hadoop-3.1.3]$ rm -rf data/ logs/
[ranan@hadoop104 hadoop-3.1.3]$ rm -rf data/ logs/
[ranan@hadoop103 hadoop-3.1.3]$ rm -rf data/ logs/
[ranan@hadoop102 hadoop-3.1.3]$ rm -rf data/ logs/
3 修改脚本
在主节点hadoop102 修改脚本增加节点数 为了后续的处理更方便
- jpsall 查看进程 增加节点hadoop105 hadoop106
- myhadoop.sh 启动/关闭集群 不需要修改,hdfs/historyserver在hadoop102上,yarn在hadoop103上
- xsync 分发文件 增加节点hadoop105 hadoop106
4 修改hadoop相关配置
修改白名单 黑名单
[ranan@hadoop102 hadoop]$ vim blacklist
[ranan@hadoop102 hadoop]$ vim whitelist
hadoop102
hadoop103
hadoop104
hadoop105
hadoop106
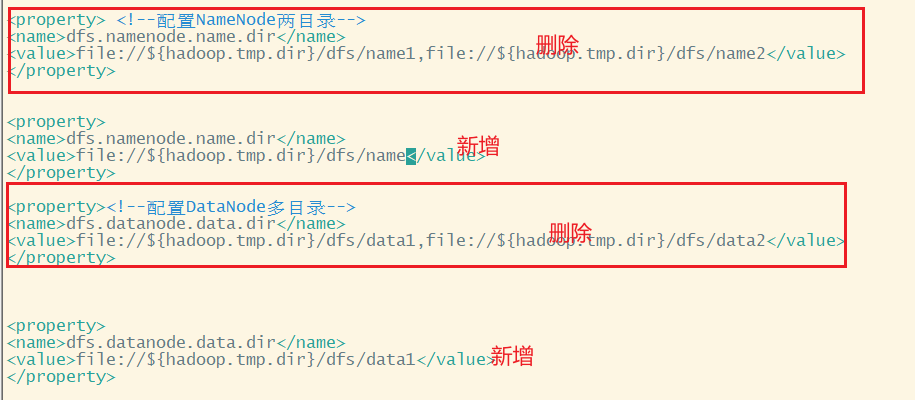
关闭多目录配置
[ranan@hadoop102 hadoop]$ vim hdfs-site.xml
配置workers
[ranan@hadoop102 bin]$ vim /opt/module/hadoop-3.1.3/etc/hadoop/workers
hadoop102
hadoop103
hadoop104
hadoop105
hadoop106
分发
[ranan@hadoop102 etc]$ xsync hadoop/
发现不能免密访问hadoop106,配置所有节点免密连接
[ranan@hadoop102 .ssh]$ ssh-copy-id hadoop106
[ranan@hadoop103 .ssh]$ ssh-copy-id hadoop106
5 格式化namenode
[ranan@hadoop106 hadoop-3.1.3]$ hdfs namenode -format
6 重启集群
[ranan@hadoop102 etc]$ myhadoop.sh start
[ranan@hadoop102 etc]$ jpsall
纠删码
纠删码原理
背景
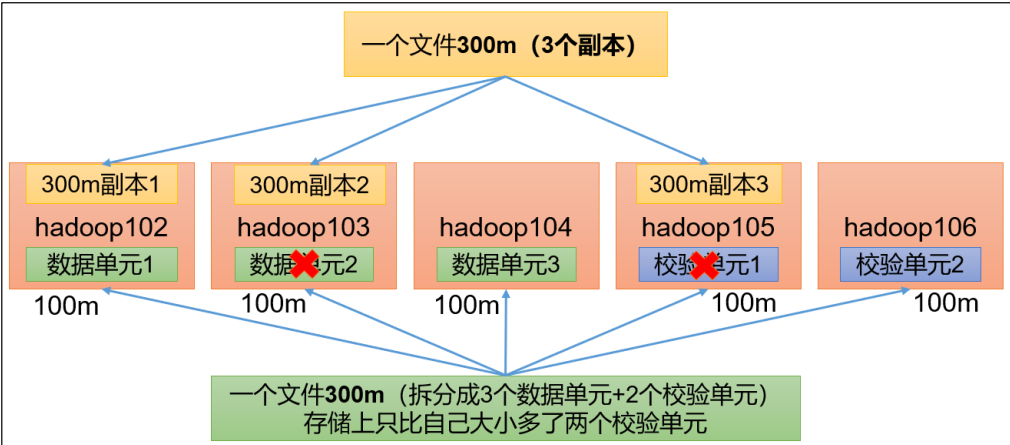
HDFS默认情况下,一个文件有三个副本,这样提高了数据的可靠性,但带来2倍的冗余开销。一个300M的文件需要900M的存储空间。
Hadoop3.x 引入了纠删码,采用计算的方式,可以节省越50%左右的存储空间。
案例
这里以其中一个算法为例
一个文件300M 拆分成3个数据单元(100m/个)、2个校验单位(100m/个),那么只需要500M的内存
任意两台服务器挂了,可以通过计算的方式,找回丢失的数据
节约了内存但是占用了计算资源
纠删码操作相关的命令
[ranan@hadoop102 ~]$ hdfs ec
Usage: bin/hdfs ec [COMMAND]
[-listPolicies] # 查看所有的策略(算法)
[-addPolicies -policyFile <file>] # 添加策略
[-getPolicy -path <path>] # 获取某一个路径的纠删码策略
[-removePolicy -policy <policy>] # 删除策略
[-setPolicy -path <path> [-policy <policy>] [-replicate]] # 对某个路径设置纠删码策略
[-unsetPolicy -path <path>]
[-listCodecs]
[-enablePolicy -policy <policy>] # 开启某个纠删码策略
[-disablePolicy -policy <policy>] # 关闭某个纠删码策略
[-help <command-name>]
在集群启动下,查看所有的策略(算法)
[ranan@hadoop102 ~]$ hdfs ec -listPolicies
Erasure Coding Policies:
ErasureCodingPolicy=[Name=RS-10-4-1024k, Schema=[ECSchema=[Codec=rs, numDataUnits=10, numParityUnits=4]], CellSize=1048576, Id=5], State=DISABLED
ErasureCodingPolicy=[Name=RS-3-2-1024k, Schema=[ECSchema=[Codec=rs, numDataUnits=3, numParityUnits=2]], CellSize=1048576, Id=2], State=DISABLED
ErasureCodingPolicy=[Name=RS-6-3-1024k, Schema=[ECSchema=[Codec=rs, numDataUnits=6, numParityUnits=3]], CellSize=1048576, Id=1], State=ENABLED
ErasureCodingPolicy=[Name=RS-LEGACY-6-3-1024k, Schema=[ECSchema=[Codec=rs-legacy, numDataUnits=6, numParityUnits=3]], CellSize=1048576, Id=3], State=DISABLED
ErasureCodingPolicy=[Name=XOR-2-1-1024k, Schema=[ECSchema=[Codec=xor, numDataUnits=2, numParityUnits=1]], CellSize=1048576, Id=4], State=DISABLED
纠删码策略解释
RS-3-2-1024k
1.使用RS编码
2.每3个数据单元,生产2个校验单元,共5个单元,这5个单元中,只要有任意3个单元存在,就可以得到原始数据。
3.每个单元的大小是1024k = 1024 * 1024Byte
假设2M的数据,1M为一个单元,那么就有2个数据单元,校验单元有2个
假设1KB的数据,小于1M,那么就有1个数据单元,校验单元还是有2个
RS-10-4-1024k
1.使用RS编码
2.每10个数据单元,生产4个校验单元,共14个单元,这14个单元中,只要有任意10个单元存在,就可以得到原始数据。
3.每个单元的大小是1024k = 1024 * 1024Byte
RS-6-3-1024k
1.使用RS编码
2.每6个数据单元,生产3个校验单元,共9个单元,这9个单元中,只要有任意6个单元存在,就可以得到原始数据。
3.每个单元的大小是1024k = 1024 * 1024Byte
RS-LEGACY-6-3-1024k
策略与上面一样,只是编码的算法用的是rs-legacy
XOR-2-1-1024k
1.使用XOR编码,速度比RS编码快
2.每2个数据单元,生产1个校验单元,共3个单元,这3个单元中,只要有任意2个单元存在,就可以得到原始数据。
3.每个单元的大小是1024k = 1024 * 1024Byte
纠删码案例
纠删码策略是给具体一个路径设置。所有此路径下存储的文件,都会执行此策略。
默认只开启对 RS-6-3-1024k 策略的支持,如要使用别的策略需要提前启用。

需求
将/input 目录设置为 RS-3-2-1024k 策略
实现
1.默认开启RS-6-3-1024K策略,所以需要手动开启对RS-3-2-1024k策略。策略需要先开启再使用。
[ranan@hadoop102 hadoop-3.1.3]$ hdfs ec -enablePolicy -policy RS-3-2-1024k
Erasure coding policy RS-3-2-1024k is enabled
2.在HDFS创建目录,并设置RS-3-2-1024k策略
[ranan@hadoop102 hadoop-3.1.3]$ hdfs dfs -mkdir /input
[ranan@hadoop102 hadoop-3.1.3]$ hdfs ec -setPolicy -path /input -policy RS-3-2-1024k
Set RS-3-2-1024k erasure coding policy on /input
3.上传数据,观察每个节点存储的内容
需要看到效果需要大于2M,因为1M为一个单位,只有大于2M才会存储成3块。
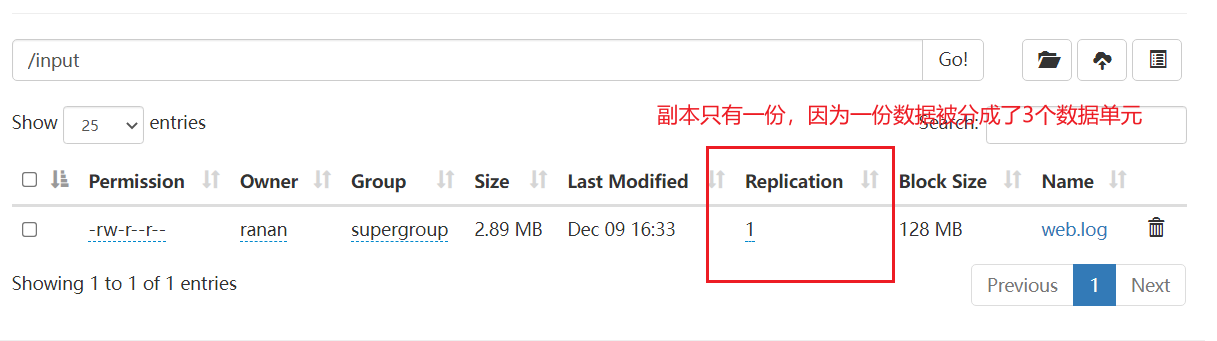
5个节点上都有,3个数据单元,2个校验单元
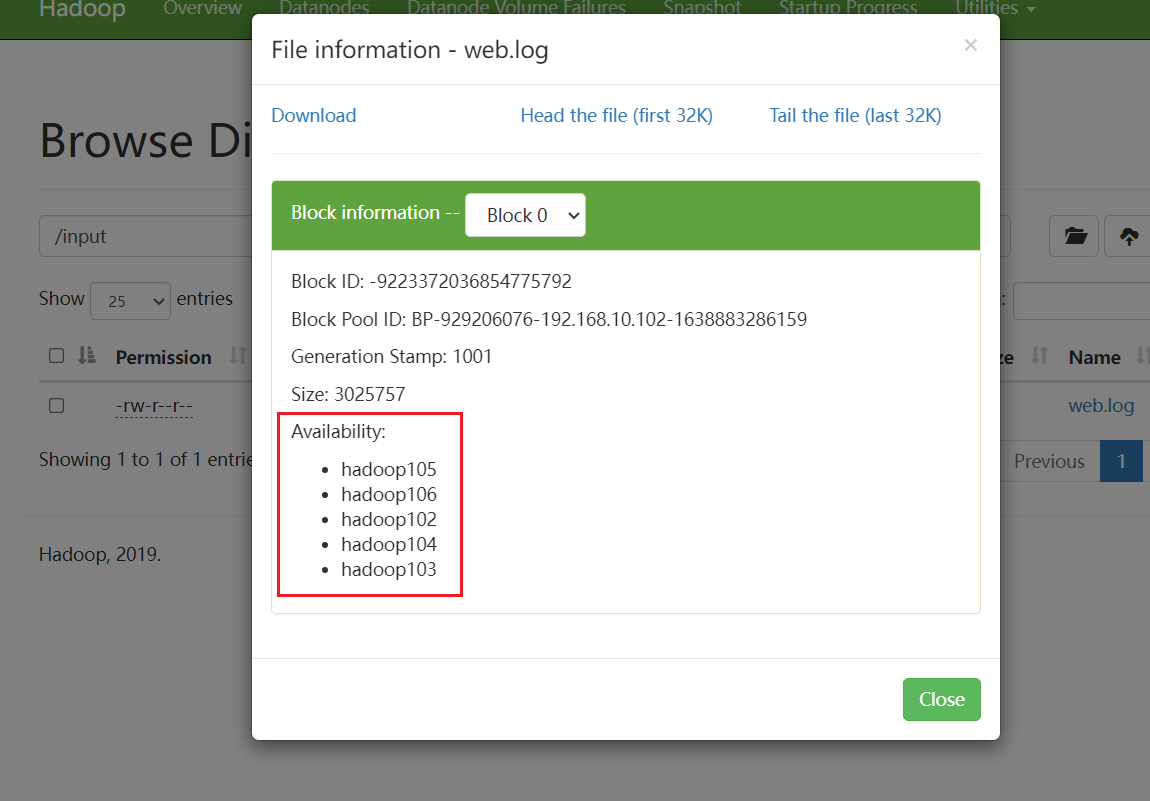
hadoop 102 的数据,我的路径如下,按照之前的操作这个的data1应该是data
/opt/module/hadoop-3.1.3/data/dfs/data1/current/BP-929206076-192.168.10.102-1638883286159/current/finalized/subdir0/subdir0
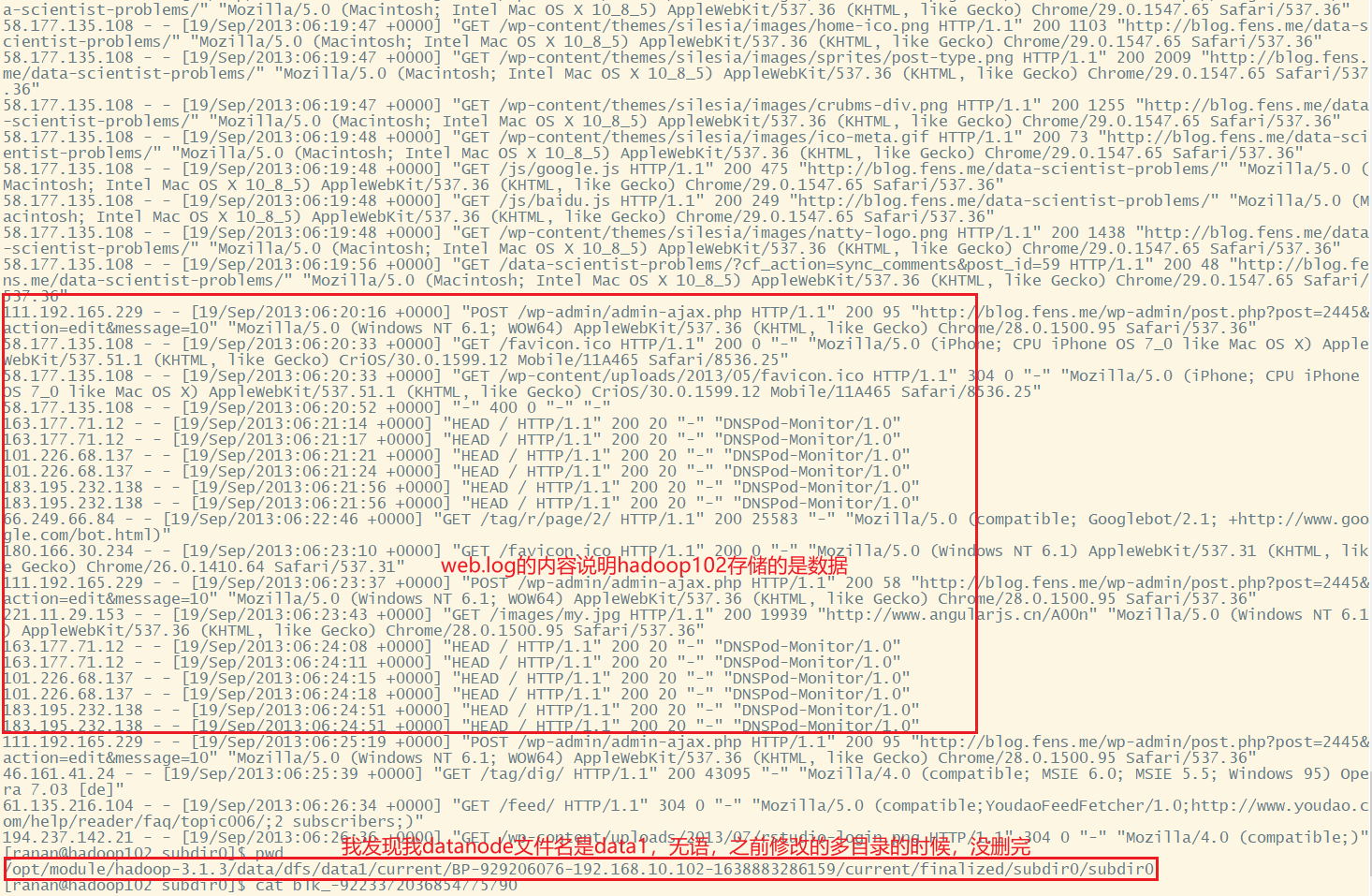
hadoop 103 的数据

其他节点同样操作
hadoop102 数据单元
hadoop103 校验单元
hadoop104 校验单元
hadoop105 数据单元
hadoop106 数据单元
4.破坏数据完整性,恢复数据
删除任意两个节点的数据,我删除hadoop105和hadoop106
[ranan@hadoop106 subdir0]$ rm -rf blk_-9223372036854775791 blk_-9223372036854775791_1001.meta
[ranan@hadoop105 subdir0]$ rm -rf blk_-9223372036854775791 blk_-9223372036854775791_1001.meta
下载的数据仍然是完整的数据,下载之后删除的节点数据会自动恢复。如果删除了三个节点,那么会下载失败。
异构存储(冷热数据分离)
经常使用的数据是热数据,不经常使用的数据是冷数据
异构存储主要解决的问题:不同的数据,存储在不同类型的硬盘中,达到最佳性能。
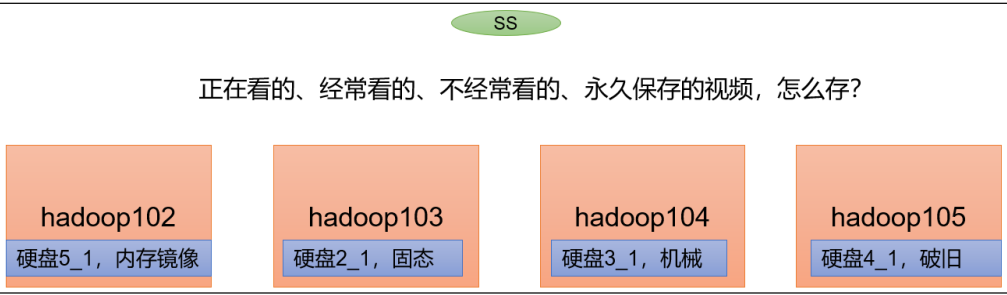
需求场景
假设有四个硬盘,一堆视频分为:正在看的、经常看的、不经常看的、永久保存(不看)
正在看的存储在内存镜像里,经常看的存储在固态里,不经常看的存储在机械里,永久保存的存储在破旧
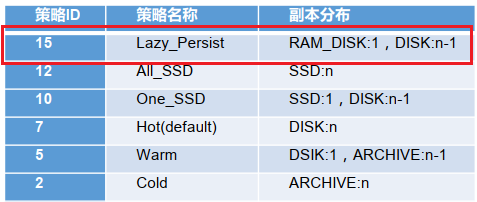
存储类型和存储策略
存储类型
RAM_DISK: 内存镜像文件系统,速度最快
SSD: SSD固态硬盘
DISK: 普通磁盘, 在HDFS中, 如果没有主动声明数据目录存储类型默认都是DISK
ARCHIVE:档案文件 没有特指哪种存储介质, 主要的指的是计算能力比较弱而存储密度比较高的存储介质, 用来解决数据量的容量扩增的问题, 一般用于归档
存储策略
类似纠删码,对路径设置策略!

异构存储的Shell操作
查看当前有哪些存储策略可以用
[ranan@hadoop106 subdir0]$ hdfs storagepolicies -listPolicies
Block Storage Policies:
BlockStoragePolicy{PROVIDED:1, storageTypes=[PROVIDED, DISK], creationFallbacks=[PROVIDED, DISK], replicationFallbacks=[PROVIDED, DISK]}
BlockStoragePolicy{COLD:2, storageTypes=[ARCHIVE], creationFallbacks=[], replicationFallbacks=[]}
BlockStoragePolicy{WARM:5, storageTypes=[DISK, ARCHIVE], creationFallbacks=[DISK, ARCHIVE], replicationFallbacks=[DISK, ARCHIVE]}
BlockStoragePolicy{HOT:7, storageTypes=[DISK], creationFallbacks=[], replicationFallbacks=[ARCHIVE]}
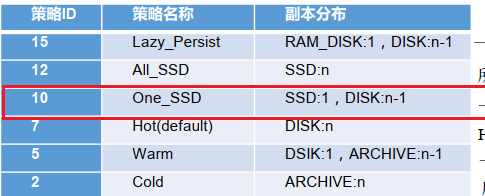
BlockStoragePolicy{ONE_SSD:10, storageTypes=[SSD, DISK], creationFallbacks=[SSD, DISK], replicationFallbacks=[SSD, DISK]}
BlockStoragePolicy{ALL_SSD:12, storageTypes=[SSD], creationFallbacks=[DISK], replicationFallbacks=[DISK]}
BlockStoragePolicy{LAZY_PERSIST:15, storageTypes=[RAM_DISK, DISK], creationFallbacks=[DISK], replicationFallbacks=[DISK]}
为指定路径(数据存储目录) 设置指定的存储策略
hdfs storagepolicies -setStoragePolicy -path xxx -policy xxx
获取指定路径(数据存储目录或文件)的存储策略
hdfs storagepolicies -getStoragePolicy -path xxx
取消存储策略;执行改命令之后该目录或者文件,以其上级的目录为准,如果是根目录,那么就是 HOT
hdfs storagepolicies -unsetStoragePolicy -path xxx
查看文件块的分布
bin/hdfs fsck xxx -files -blocks -locations
查看集群节点
hadoop dfsadmin -report
测试环境准备
测试环境描述
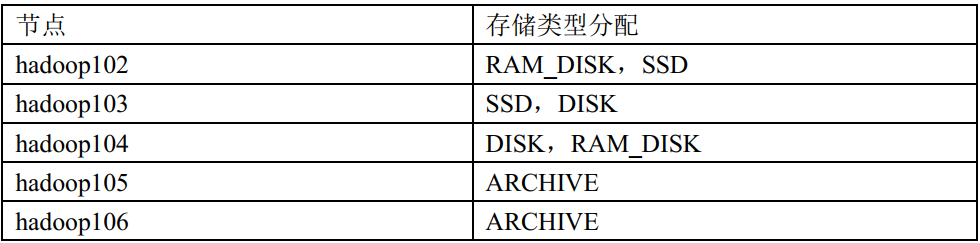
服务器:5台
集群配置:副本数为 2,创建好带有存储类型的目录(提前创建)
集群规划:
配置文件信息
1.hadoop102节点的hdfs-site.xml添加如下信息
这里显示把存储策略打开,其实默认是打开的
之前配置过的datanode记得删掉
<property><!--副本数-->
<name>dfs.replication</name>
<value>2</value>
</property>
<property>
<name>dfs.storage.policy.enabled</name>
<value>true</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>[SSD]file:///opt/module/hadoop-3.1.3/hdfsdata/ssd,[RAM_DISK]file:///opt/module/hadoop-3.1.3/hdfsdata/ram_disk</value>
</property>

2.hadoop103节点的hdfs-site.xml添加如下信息
<property>
<name>dfs.replication</name>
<value>2</value>
</property>
<property>
<name>dfs.storage.policy.enabled</name>
<value>true</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>[SSD]file:///opt/module/hadoop-3.1.3/hdfsdata/ssd,[DISK]file:///opt/module/hadoop-3.1.3/hdfsdata/disk</value>
</property>
3.hadoop104节点的hdfs-site.xml添加如下信息
<property>
<name>dfs.replication</name>
<value>2</value>
</property>
<property>
<name>dfs.storage.policy.enabled</name>
<value>true</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>[RAM_DISK]file:///opt/module/hdfsdata/ram_disk,[DISK]file:///opt/module/hadoop-3.1.3/hdfsdata/disk</value>
</property>
4.hadoop105节点的hdfs-site.xml添加如下信息
<property>
<name>dfs.replication</name>
<value>2</value>
</property>
<property>
<name>dfs.storage.policy.enabled</name>
<value>true</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>[ARCHIVE]file:///opt/module/hadoop-3.1.3/hdfsdata/archive</value>
</property>
5.hadoop106节点的hdfs-site.xml添加如下信息
<property>
<name>dfs.replication</name>
<value>2</value>
</property>
<property>
<name>dfs.storage.policy.enabled</name>
<value>true</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>[ARCHIVE]file:///opt/module/hadoop-3.1.3/hdfsdata/archive</value>
</property>
数据准备
1.格式化集群
- 关闭集群
- 删除data、log
- 格式化
- 重启集群
# 这里集群是关闭了的,就不用再关闭集群了
[ranan@hadoop102 hadoop-3.1.3]$ rm -rf data/ logs/
[ranan@hadoop103 hadoop-3.1.3]$ rm -rf data/ logs/
[ranan@hadoop104 hadoop-3.1.3]$ rm -rf data/ logs/
[ranan@hadoop105 hadoop-3.1.3]$ rm -rf data/ logs/
[ranan@hadoop106 hadoop-3.1.3]$ rm -rf data/ logs/
[ranan@hadoop102 hadoop-3.1.3]$ hdfs namenode -format
[ranan@hadoop102 hadoop-3.1.3]$ myhadoop.sh start
2.在 HDFS 上创建文件目录
[ranan@hadoop102 hadoop-3.1.3]$ touch NOTICE.txt
[ranan@hadoop102 hadoop-3.1.3]$ hadoop fs -mkdir /hdfsdata
3.将文件资料上传
[ranan@hadoop102 hadoop-3.1.3]$ hadoop fs -put NOTICE.txt /hdfsdata
HOT(default) 存储策略案例
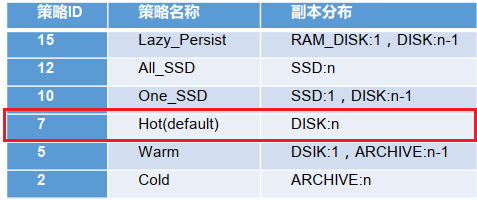
1.在开始未设置存储策略的情况下,我们获取该目录的存储策略
[ranan@hadoop102 hadoop-3.1.3]$ hdfs storagepolicies -getStoragePolicy -path /hdfsdata
The storage policy of /hdfsdata is unspecified
2.我们查看上传的文件块分布
这个命令看不出来,那就查看文件块分布来进行匹配
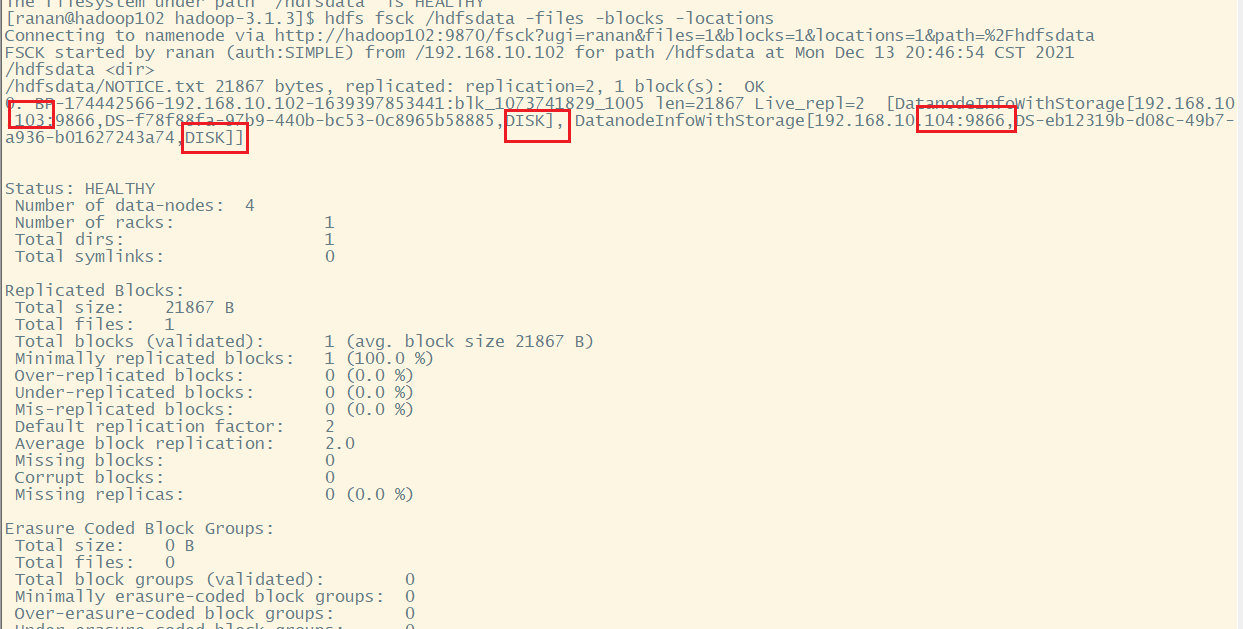
[ranan@hadoop102 hadoop-3.1.3]$ hdfs fsck /hdfsdata -files -blocks -locations
/hdfsdata/NOTICE.txt 21867 bytes, replicated: replication=2, 1 block(s): OK
0. BP-174442566-192.168.10.102-1639397853441:blk_1073741829_1005 len=21867 Live_repl=2 [DatanodeInfoWithStorage[192.168.10.103:9866,DS-f78f88fa-97b9-440b-bc53-0c8965b58885,DISK], DatanodeInfoWithStorage[192.168.10.104:9866,DS-eb12319b-d08c-49b7-a936-b01627243a74,DISK]]

WARN 存储策略测试
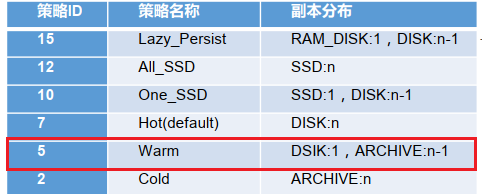
1.设置WARN存储策略
[ranan@hadoop102 hadoop-3.1.3]$ hdfs storagepolicies -setStoragePolicy -path /hdfsdata -policy WARM
2.再次查看文件块分布,我们可以看到文件块依然放在原处。
[ranan@hadoop102 hadoop-3.1.3]$ hdfs fsck /hdfsdata -files -blocks -locations
还是在disk,原因不会自动把文件从一个盘移入另一个盘

3.我们需要让他 HDFS 按照存储策略自行移动文件块
MOVER定期扫描HDFS文件,检查文件的存放是否符合它自身的存储策略。如果数据块不符合自己的策略,它会把数据移动到该去的地方。
可以手动移动
[ranan@hadoop102 hadoop-3.1.3]$ hdfs mover /hdfsdata
4.移动完之后再次查看文件块分布
[ranan@hadoop102 hadoop-3.1.3]$ hdfs fsck /hdfsdata -files -blocks -locations

COLD 存储策略测试
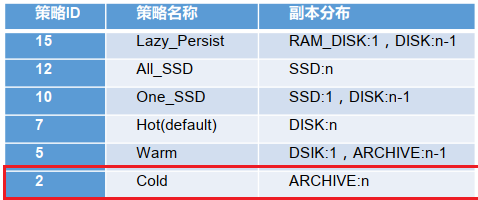
注意:当我们将目录设置为 COLD 并且我们未配置 ARCHIVE 存储目录的情况下,不可以向该目录直接上传文件,会报出异常。
# 设置策略
[ranan@hadoop102 hadoop-3.1.3]$ hdfs storagepolicies -setStoragePolicy -path /hdfsdata -policy COLD
Set storage policy COLD on /hdfsdata
# 移动
[ranan@hadoop102 hadoop-3.1.3]$ hdfs mover /hdfsdata
# 查看文件块分布
[ranan@hadoop102 hadoop-3.1.3]$ hdfs fsck /hdfsdata -files -blocks -locations
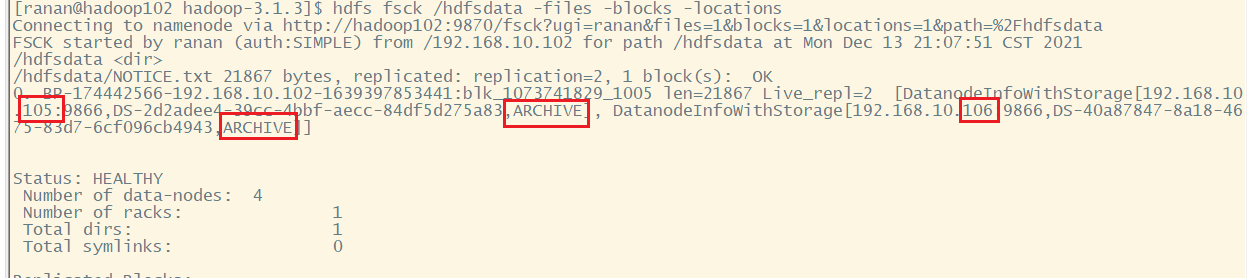
One_SSD 存储策略测试
[ranan@hadoop102 hadoop-3.1.3]$ hdfs storagepolicies -setStoragePolicy -path /hdfsdata -policy One_SSD
# 移动
[ranan@hadoop102 hadoop-3.1.3]$ hdfs mover /hdfsdata
# 查看文件块分布
[ranan@hadoop102 hadoop-3.1.3]$ hdfs fsck /hdfsdata -files -blocks -locations

All_SSD 存储策略测试
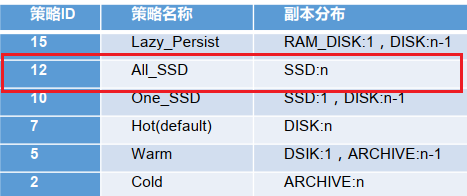
[ranan@hadoop102 hadoop-3.1.3]$ hdfs storagepolicies -setStoragePolicy -path /hdfsdata -policy All_SSD
# 移动
[ranan@hadoop102 hadoop-3.1.3]$ hdfs mover /hdfsdata
# 查看文件块分布
[ranan@hadoop102 hadoop-3.1.3]$ hdfs fsck /hdfsdata -files -blocks -locations
错误1 Some blocks can’t be moved. Exiting…

暂时不知道什么原因,我发现下面的过程中怎么没有创建192.168.10.102节点,刚好102又配置了SSD,是不是因为要两个副本又只有hadoop103一个是SSD所以移动失败
2021-12-13 21:46:39,041 INFO net.NetworkTopology: Adding a new node: /default-rack/192.168.10.106:9866
2021-12-13 21:46:39,041 INFO net.NetworkTopology: Adding a new node: /default-rack/192.168.10.105:9866
2021-12-13 21:46:39,041 INFO net.NetworkTopology: Adding a new node: /default-rack/192.168.10.104:9866
2021-12-13 21:46:39,041 INFO net.NetworkTopology: Adding a new node: /default-rack/192.168.10.103:9866
看102的配置,果然路径出问题了
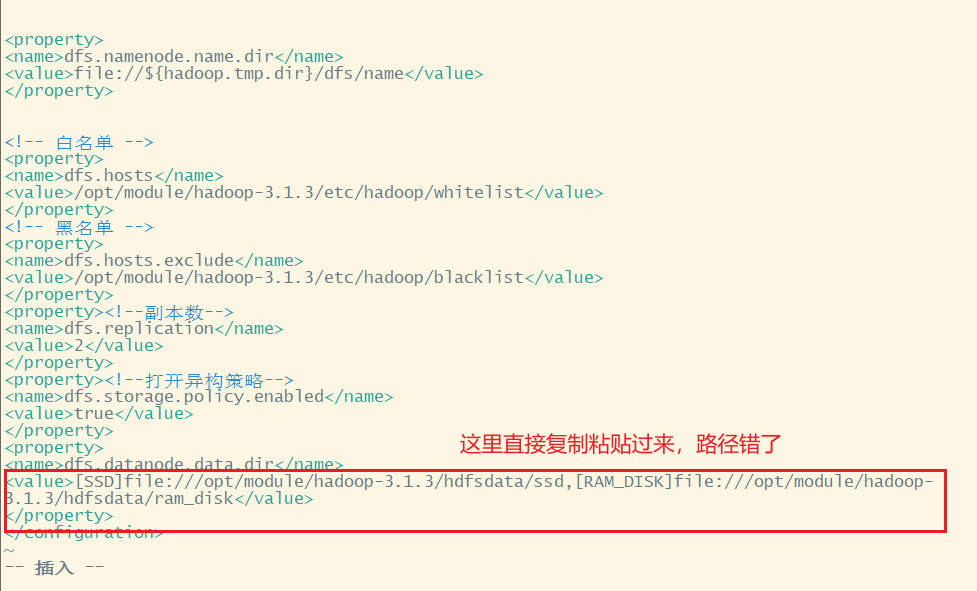
修改之后又格式化集群、重新启动集群、新建目录、与改变策略之后,执行成功了
注意格式化的不仅删除data、log 还要删除我们新建的hdfsdata,这个路径没有在data下面所以需要手动删除,不然会出现版本对不上的事情。
lazy_persist 存储策略测试(不常用)

p-3.1.3]$ hdfs storagepolicies -setStoragePolicy -path /hdfsdata -policy lazy_persist
# 移动
[ranan@hadoop102 hadoop-3.1.3]$ hdfs mover /hdfsdata
# 查看文件块分布
[ranan@hadoop102 hadoop-3.1.3]$ hdfs fsck /hdfsdata -files -blocks -locations
发现所有的文件块都是存储在 DISK,按照理论一个副本存储在 RAM_DISK,其他副本存储在 DISK 中,

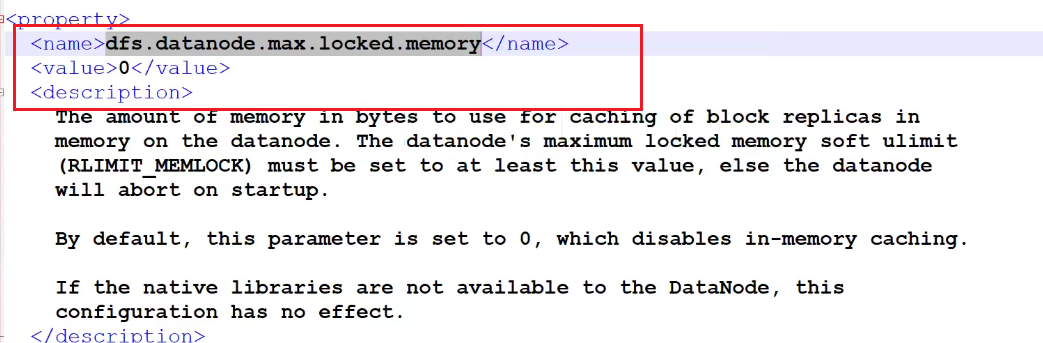
hdfs对在内存数据存储的限制
原因是因为存储到内存镜像中有限制,需要配置允许在内存中存储多少数据dfs.datanode.max.locked.memory默认是0,
通常按块大小来存储数据,那么加载到内存至少是一块,所以配置的值需要大于dfs.block.size
linux对在内存存储数据的限制
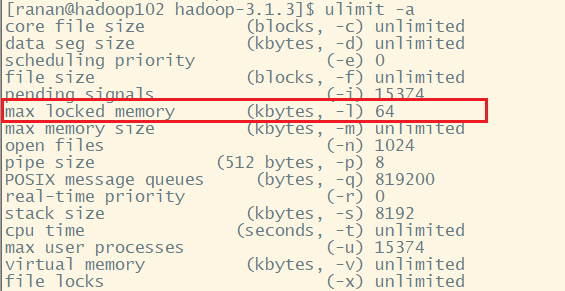
但是由于虚拟机的“max locked memory”为 64KB,所以,如果参数配置过大,还会报出错误
ERROR org.apache.hadoop.hdfs.server.datanode.DataNode: Exception in
secureMain
java.lang.RuntimeException: Cannot start datanode because the configured
max locked memory size (dfs.datanode.max.locked.memory) of 209715200
bytes is more than the datanode's available RLIMIT_MEMLOCK ulimit of
65536 bytes.
使用ulimit命令查看
[ranan@hadoop102 hadoop-3.1.3]$ ulimit -a
如果要看见效果,由于linux对内存的限制,可以先修改max locked memory 然后修改 dfs.datanode.max.locked.memory
文件块存储在DISK上的原因
那么出现存储策略为 LAZY_PERSIST 时,文件块副本都存储在 DISK 上的原因有如下两点:
1.当客户端所在的 DataNode 节点没有 RAM_DISK 时,则会写入客户端所在的DataNode 节点的 DISK 磁盘,其余副本会写入其他节点的 DISK 磁盘。
2.当客户端所在的 DataNode 有 RAM_DISK,但“dfs.datanode.max.locked.memory”参数值未设置或者设置过小(小于“ dfs.block.size”参数值)时,则会写入客户端所在的DataNode 节点的 DISK 磁盘,其余副本会写入其他节点的 DISK 磁盘

















 1369
1369

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









