







 本文详细介绍了MySQL中的JOIN(包括INNER JOIN、NATURAL JOIN、LEFT JOIN、RIGHT JOIN)和UNION的区别与用法,通过实例展示了如何在数据库查询中使用这些操作来组合和过滤数据。特别强调了JOIN在连接条件下的数据筛选,以及UNION和UNION ALL在合并结果集时的处理方式。
本文详细介绍了MySQL中的JOIN(包括INNER JOIN、NATURAL JOIN、LEFT JOIN、RIGHT JOIN)和UNION的区别与用法,通过实例展示了如何在数据库查询中使用这些操作来组合和过滤数据。特别强调了JOIN在连接条件下的数据筛选,以及UNION和UNION ALL在合并结果集时的处理方式。
理解 MySQL 中的 JOIN 与 UNION
起步
最近公司接到一个项目,任务是根据需求制表。完整过程是:用 SQL 汇总数据,再写进 Execel 文件中。SQL 这门课倒是大学里学过,过久不用,不记得许多,顶多 SELECT 几下。总之是勉强应付。
这周五接到一个需求,差点应付不过去,卡在联表操作上了。午觉再不敢睡,总结 MySQL 查询时的多表联合。临阵磨枪管用,当测试发来 “OK” 的时候我这样想。
笔记至此,遗忘再寻。
开始前的准备
(student.sql 与 score.sql 下载链接)
现在套用一个俗套的现实场景:中学生期末考试。
有学生,那么这里会有一个 student 表,用来存放学生信息。表结构如下:
+--------+--------------------------+------+-----+---------+-------+
| Field | Type | Null | Key | Default | Extra |
+--------+--------------------------+------+-----+---------+-------+
| name | varchar(10) | NO | | NULL | |
| age | int(2) unsigned zerofill | YES | | NULL | |
| gender | varchar(10) | YES | | NULL | |
| id | int(4) unsigned zerofill | NO | PRI | NULL | |
+--------+--------------------------+------+-----+---------+-------+
- name 是学生名字;
- age 表示学生年龄;
- gender 表示性别;
- id 是学生的学号。
由于多个学生的名字相同,所以用 id 作为唯一标识,也就是 student 表的主键。
还需要成绩,因此还会有一张 score 表,存放学生成绩。表结构如下:
+---------+-------------+------+-----+---------+-------+
| Field | Type | Null | Key | Default | Extra |
+---------+-------------+------+-----+---------+-------+
| id | int(4) | NO | PRI | NULL | |
| math | int(2) | YES | | NULL | |
| english | int(2) | YES | | NULL | |
| chinese | int(2) | YES | | NULL | |
| name | varchar(10) | YES | | *** | |
+---------+-------------+------+-----+---------+-------+
- id 表示学生的学号,主键;
- math、english、chinese 分别表示数学成绩、英语成绩、语文成绩;
- name 是考生姓名,默认为 “***”。为保证公平,让学生匿名没什么不对。
可以看到,student 和 score 两张表之间的关联是 id 字段,因而接下来 id 会被频繁使用。同时,为方便实验,我们还需要在两张表中插入一些特定的数据,使得这些数据看上去存在一些“意外”。
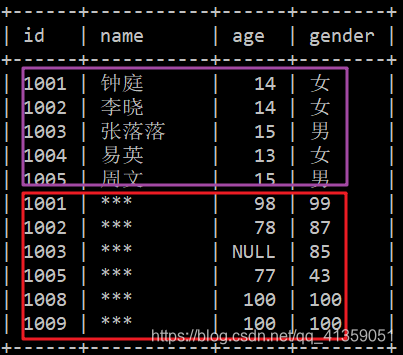
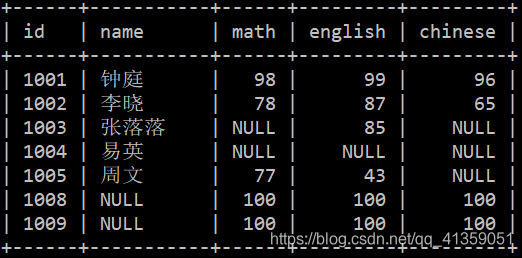
学生信息如下:
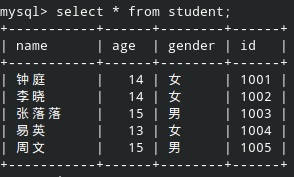
成绩信息如下:
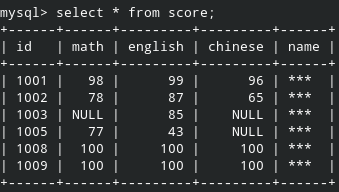
意外说明:
- student 表中,id 取值在 [1001, 1006) 区间,且连续整数。然而 score 则是 [1001, 1004) ∪ [1005, 1006) ∪ [1008, 1010)。也就是说,学生 “易英(1004)” 没有参与此次考试,所以 score 表中没有她的成绩。而学号为 1008 和 1009 的学生,因转学走了,导致 student 表中没有这两人的信息。
好了,准备就绪。我们进入主题吧!
JOIN
在 MySQL 中,JOIN 默认是 INNER JOIN,也就是内连接。不加连接条件的内连接其实就是笛卡尔积,也就说,student 表中的每一条数据,都会和 score 表中的每一条数据结合。stundet 表中有五条数据,score 表中有六条数据,因而 SELECT * FROM student JOIN score 的结果会是 30 条数据。
为便于观察,我们可以对结果排序。先以 student 表中 name 降序,再以 score 表中的 id 升序,SQL 如下:
SELECT *
FROM student
JOIN score
ORDER BY student.name DESC, score.id ASC;
运行结果的部分数据如下:
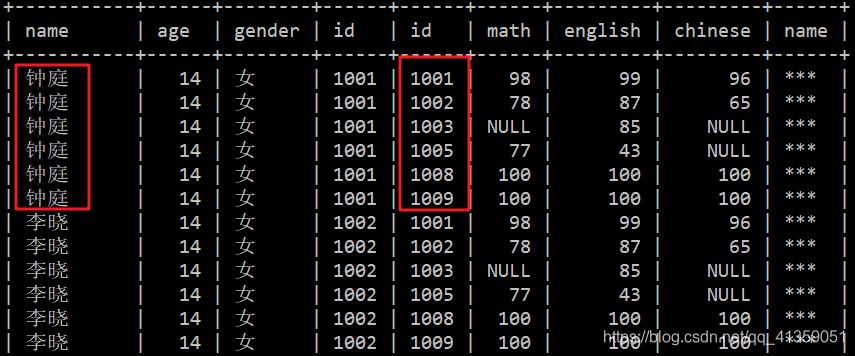
在实际需求中,是需要连接条件的,因为任意数据相连接得到的结果大多时候没有意义。比如,我们希望得到每个学生的真实名字,学号,以及她们的科目成绩。直接 JOIN 肯定得不到我们想要的结果,这时候就需要加上连接条件,SQL 中连接两张表的连接词是 ON。
完成一张有真实姓名的成绩单,其 SQL 应该书写如下:
SELECT
stu.id, stu.name,
sco.math, sco.english, sco.chinese
FROM student AS stu
JOIN score AS sco ON stu.id = sco.id;
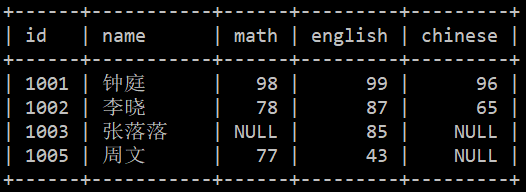
此次运行结果我们应该尤其注意:结果集里没有学号为 1004 的易英,也没有考了满分就转学的 1008 和 1009。所以形如 SELECT ... FROM A JOIN B ON A.id = B.id 是在求 A 表中 id 与 B 表中 id 的交集。
A([1001, 1004)) ∩ B([1001, 1004) ∪ [1005, 1006) ∪ [1008, 1010)) = [1001, 1004) ∪ [1005, 1006)
交集结果是:id = 1001, 1002, 1003, 1005。再把 stundet 表中 student.id = 1001 的数据与 score 表中 score.id = 1001 的数据连接起来,student.id = 1002 与 score.id = 1002 的数据连接起来,依次继续。完成连接后就得到了上面的结果。
事实上,上面 SQL 得到的数据并非对应 “每个学生的真实名字,学号,以及她们的科目成绩”。准确的说应该是:获取参考且在校学生的真实名字,学号,以及她们的成绩。“参考”意味着没有 1004,“在校”意味着没有 1008 和 1009。
另外,SQL99 标准中提供了 USING 关键字,用来简化相等条件时的 ON,即:
JOIN score AS sco ON stu.id = sco.id;
等同于
JOIN score AS sco USING (id)。
NATURAL JOIN
NATURAL JOIN 是自然连接的意思,其实是程序员的偷懒行为,它默认将两张表相同的字段按 ON ... = ... 连接起来。如果存在多个同名字段,如 student 里有 id,name;score 表里有 id,name,那么默认的连接条件会是:ON student.id = score.id AND student.name = score.name。
显然,student 表和 score 表中的 name 总是不等,因此自然连接的结果是空。
SELECT
*
FROM student
NATURAL JOIN score;
-- Empty set (0.00 sec)
我们可以利用 SQL 嵌套,让两张表中只有 id 这一个同名字段。再来看看自然连接效果。
SELECT
*
FROM (SELECT id, name FROM student) AS stu
NATURAL JOIN (SELECT id, math, english, chinese FROM score) AS sco;
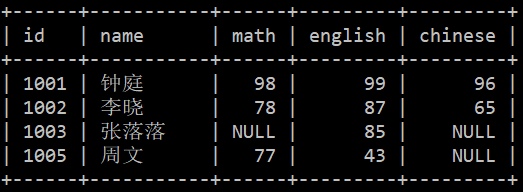
通过这种方式,证明了 NATURAL JOIN 的确会默认连接同名字段。
LEFT JOIN
LEFT JOIN 是左连接,用意是保证左边表的数据完整,同时把右边表的数据连接过来。如果在指定条件下,左边表有数据,而右边表没有对应数据,右边表中的字段会填充 NULL。
上边的说法很抽象,我们可以举个实例理解。现在需求是:绘制一张在校学生的成绩单。
“在校”,意味结果中有 student 表中的全部学生。但是 score 表中并没有 1004 学生的成绩,既是没有,填充 NULL 就好。SQL 应如下:
SELECT
stu.id, stu.name,
sco.math, sco.english, sco.chinese
FROM student AS stu
LEFT JOIN score AS sco USING (id);
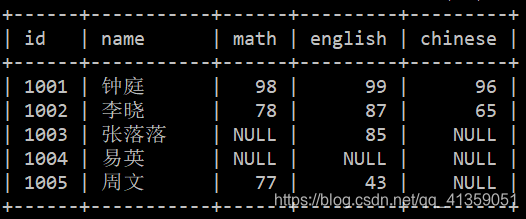
结果显而易见,没有 1008 和 1009 同学的成绩。左连接会无条件满足左边表,也因此存在右表丢失数据的可能。
RIGHT JOIN
RIGHT JOIN 是右连接,与左连接恰好相反。右连接会保证右表的数据完整,可能造成左表数据丢失。
需求:绘制一张参考成绩单,找出每个参考学生的真实名字。
SELECT
sco.id, stu.name,
sco.math, sco.english, sco.chinese
FROM student AS stu
RIGHT JOIN score AS sco USING (id);
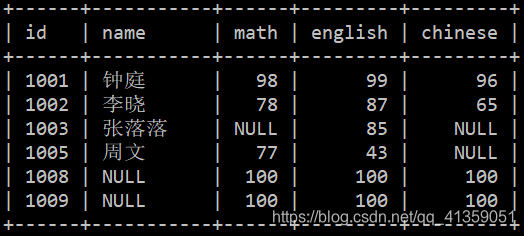
学生参考后一定会有成绩(至少有一门课的成绩),因而需要将 score 作为主表,保证它的数据完整。但由于 1008 和 1009 转学走了,student 中没有这两位学生的名字,所以填充 NULL。
UNION
UNION 操作符用于两个或多个 SELECT 语句的结果集。你可以理解为“拼接”。
同 JOIN 不一样,JOIN 是将两张表的数据按一定条件结合起来,得到一条新数据,这些新数据再组合成最终结果。而 UNION 是纯粹地把两个 SELECT 后的结果集上下拼接。因而,使用 UNION 必须确保两个集合的列的数量相等,不然报错:The used SELECT statements have a different number of columns。通常还要保证对应列的类型相同。如果类型不同,MySQL 会尝试转换类型;如果类型转换失败,MySQL 报错。
下面是一个没有意义的 UNION 操作,主要为展示运行效果。
SELECT id, name, age, gender FROM student
UNION
SELECT id, name, math, english FROM score;
UNION ALL
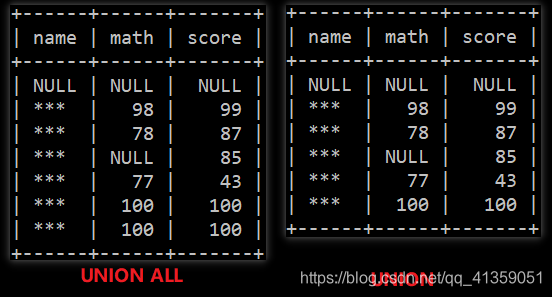
UNION ALL 与 UNION 的区别在于,如果存在相同行,UNION 会默认只保留其中一个。示例如下:
UNION ALL
SELECT NULL AS name, NULL AS math, NULL AS score
UNION ALL
SELECT name, math, english FROM score;
UNION
SELECT NULL AS name, NULL AS math, NULL AS score
UNION ALL
SELECT name, math, english FROM score;
那么 UNION 到底什么时候用呢?一般是:当一次 SQL 中有多个主表的时候。之前说过 LEFT JOIN 会把左表当做主表,RIGHT JOIN 会把右表当做主表,这就意味着它们总会造成另一张表中的数据丢失。
现在有这么个需求:计算此次考试各科平均成绩。额外要求有二:1. 不论学生是否转学,都需要纳入计算;2. 如果学生未参与考试,按 0 分处理。
根据上述要求,我们需要先绘制一张成绩单,保证这张成绩单理既有缺考 1004,也有转学 1008,1009。得 SQL 如下:
SELECT
stu.id, stu.name,
sco.math, sco.english, sco.chinese
FROM student AS stu
LEFT JOIN score AS sco USING (id) -- 左连接,保证 student 表数据完整
UNION -- UNION,达到去重效果
SELECT
sco.id, stu.name,
sco.math, sco.english, sco.chinese
FROM student AS stu
RIGHT JOIN score AS sco USING (id); -- 右连接,保证 score 表数据完整
最后求各科平均成绩的 SQL 如下:
SELECT
AVG(t.math), AVG(t.english), AVG(t.chinese)
FROM
(SELECT
stu.id, stu.name,
IFNULL(sco.math, 0) AS math,
IFNULL(sco.english, 0) AS english,
IFNULL(sco.chinese, 0) AS chinese
FROM student AS stu
LEFT JOIN score AS sco USING (id)
UNION
SELECT
sco.id, stu.name,
IFNULL(sco.math, 0) AS math,
IFNULL(sco.english, 0) AS english,
IFNULL(sco.chinese, 0) AS chinese
FROM student AS stu
RIGHT JOIN score AS sco USING (id)
) as t;
有一个点需要注意。内置函数 AVG 会避开 NULL,即:AVG(2, 4, NULL) 的时候,平均值不是 (2 + 4 ) / 3,而是 (2 + 4) / 2。这样一来,求出来的平均值就不能满足需求,需要把 NULL 转换成 0。IFNULL(x, y) 的意思就是,如果 x 不是空,返回 x;如果 x 是空,返回 y。
+-------------+----------------+----------------+
| AVG(t.math) | AVG(t.english) | AVG(t.chinese) |
+-------------+----------------+----------------+
| 64.7143 | 73.4286 | 51.5714 |
+-------------+----------------+----------------+

















 1069
1069

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









