










 本文介绍如何使用pandas库在Python中读取Excel文件中的数字区域,并进行数值填充操作,专注于数据处理的高效实践。
本文介绍如何使用pandas库在Python中读取Excel文件中的数字区域,并进行数值填充操作,专注于数据处理的高效实践。
'''自动填充'''
import pandas as pd
# 读取文件
books = pd.read_excel('Books.xlsx')
# 猜想padas是否能自动跳过前面的空行和空列(不能自动跳过)
print(books)
# 跳过空行(前三行空行)
books = pd.read_excel('Books.xlsx', skiprows=3)
# 跳过空列 调整错位列名 此处查看c到f列
books = pd.read_excel('Books.xlsx', skiprows=3, usecols='c,d,e,f')
books = pd.read_excel('Books.xlsx', skiprows=3, usecols='c:f')
# dataframe 的每个列都是一个序列
# 设置第一个ID
books['ID'].at[0]=100
print(books['ID'])
# 使用for(迭代)循环设置所有id 迭代books的index
for i in books.index:
# 设置id (i+1是为了设置index和书的id匹配)
books['ID'].at[i] = i+1
# 此处books的输出ID为小数(float类型)
print(books)
# 但不进行填充时 列里面空的地方会被读成NaN
# 当pandas读取excel文件出现NaN时 会自动将NaN的数据类型设置为浮点类型
# 查看数据类型(在打印出的数据的最后一行)
print(books['ID'])
# 解决(自动将NaN的数据类型设置为浮点类型)方法
# books = pd.read_excel('Books.xlsx', skiprows=3, usecols='c:f', dtype={'ID': int}) #设置ID列的类型为int 报错(NaN在转换时不允许被转换为int类型)
books = pd.read_excel('Books.xlsx', skiprows=3, usecols='c:f', dtype={'ID': str, 'InStore': str, 'Date': str}) #设置ID列的类型为str
# 再读取数据 ID就不再是float类型的了
for i in books.index:
# 设置id (i+1是为了设置index和书的id匹配)
books['ID'].at[i] = i+1
# 设置InStore为Yes和No交替出现
books['InStore'].at[i] = 'Yes'if i%2==0 else 'No'
print(books)
from datetime import date, timedelta
# 初始化数据Date
start = date(2018, 1, 1)
for i in books.index:
# 设置id (i+1是为了设置index和书的id匹配)
books['ID'].at[i] = i+1
# 设置InStore为Yes和No交替出现
books['InStore'].at[i] = 'Yes'if i%2==0 else 'No'
# 暂且先设置所有Date等于start
books['Date'].at[i] = start
print(books)
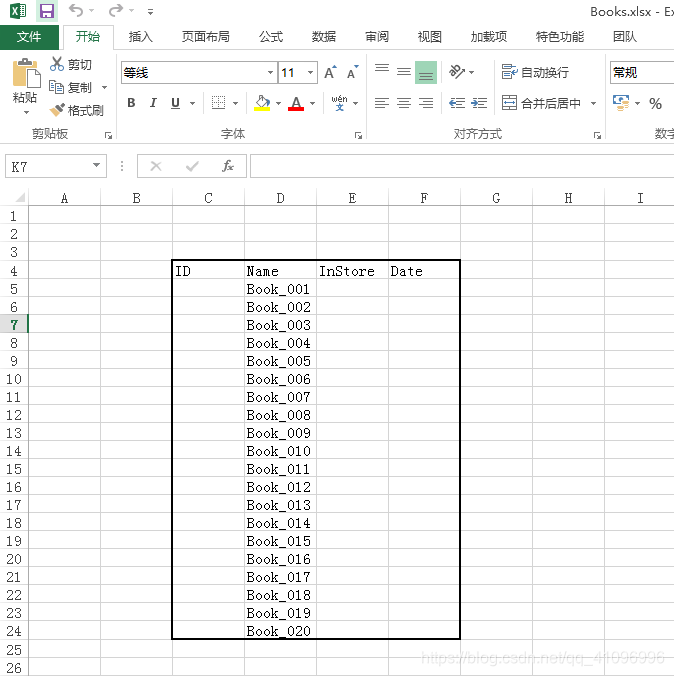
Books.xlsx:

















 278
278

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









