







综合基础
- 讲讲制作一个LLM的流程以及各阶段的作用
- 发现模型性能不好,如何从各个阶段去排查问题
查看各阶段中是否有对应训练数据,然后再向下排查。
- 手写一个深度学习训练代码
import torch
import torch.nn as nn
import torch.optim as optim
from torch.utils.data import DataLoader, TensorDataset
class SimpleModel(nn.Module):
def __init__(self, input_size, hidden_size, output_size):
super().__init__()
self.f1 = nn.Linear(input_size, hidden_size)
self.r1 = nn.ReLU()
self.f2 = nn.Linear(hidden_size, hidden_size * 2)
self.r2 = nn.ReLU()
self.f3 = nn.Linear(hidden_size * 2, output_size)
def forward(self, x):
x = self.f1(x)
x - self.r1(x)
x = self.f2(x)
x = self.r2(x)
x = self.f3(x)
return x
def train(model, train_loader, optimizer, criterion, epochs=10):
for epoch in range(epochs):
print("Epoch: {}".format(epoch + 1))
total_loss = 0.0
for batch_idx, (data, target) in enumerate(train_loader):
optimizer.zero_grad()
output = model(data)
loss = criterion(output, target)
loss.backward()
optimizer.step()
total_loss += loss.item()
print("Train Loss: {:.6f}",format(total_loss / len(train_loader)))
if __name__ == "__main__":
X = torch.randn(256, 3)
Y = torch.randn(256, 1)
dataset = TensorDataset(X, Y)
loader = DataLoader(dataset, batch_size=8, shuffle=True)
model = SimpleModel(3, 4, 1)
optimizer = optim.SGD(model.parameters(), lr=0.01)
criterion = nn.MSELoss()
train(model, loader, optimizer, criterion)
print(model(torch.randn(256, 3)))
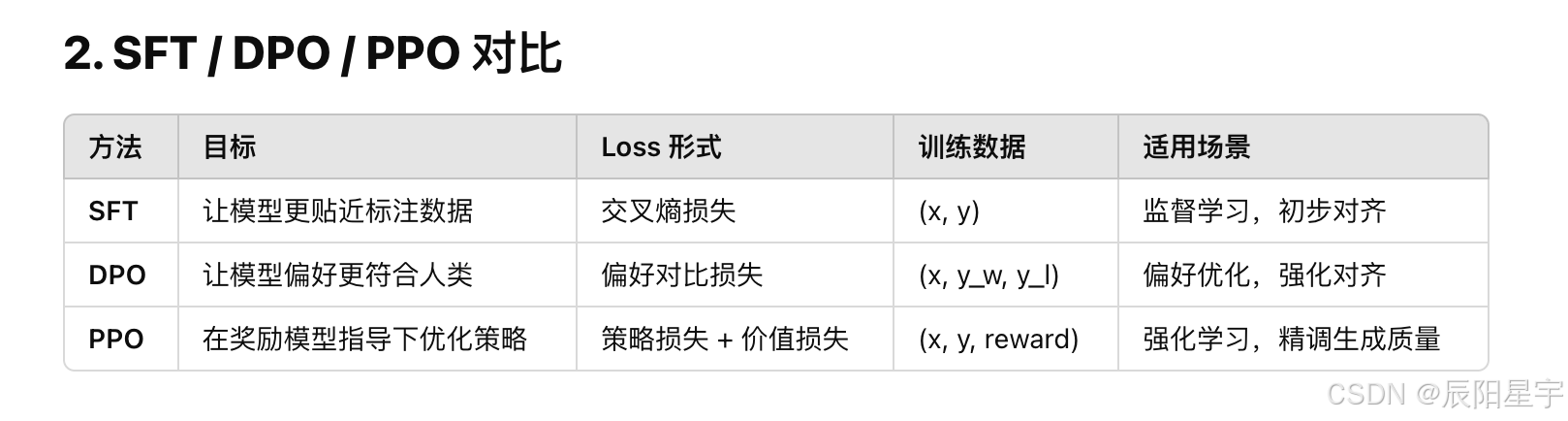
- SFT、DPO和PPO的Loss区别
1、SFT目标:最小化模型输出和标注数据之间的差距,即让模型更接近人类提供的优质示例。
Loss 函数:通常是 交叉熵损失(Cross-Entropy Loss)。
2、DPO目标:直接优化模型使其更符合人类偏好,而不需要计算 KL 散度约束(区别于 PPO)。
Loss 函数:基于偏好对比损失,优化两个样本(优选 ym和次优yl )之间的相对概率。
3、PPO目标:最大化奖励,同时保持新旧策略变化的稳定性,避免策略大幅度更新导致训练不稳定。
PPO 的 Loss 通常由**策略更新损失(policy loss)和价值函数损失(value loss)**组成:
(1)策略损失(Policy Loss):PPO 采用裁剪的目标函数,限制新旧策略之间的变化幅度
(2)价值函数损失(Value Loss):模型型估计的状态价值与奖励模型给出的真实回报之间差的平方
总损失是策略损失加上乘上超参数c1的价值函数损失再减去乘上超参数c2的熵损失。(熵损失增加探索性,防止策略过早收敛。)
5. SFT、DPO和PPO的适用场景是什么?什么时候使用?



6. Decoder-only比Encoder-only的优势有哪些?




7. 手写注意力机制
自注意力机制、多头自注意力机制、填充掩码 Python实现
注:如果seq_len长度不一样的时候,考虑填充padding,然后再加上一个mask,对mask部分取值为无穷小,让softmax最后计算时候为0。
-
Python的可变对象(传入数组后在数组内部修改值后,外部的值也会变)有哪些
有list、set、dict -
Python的函数参数是如何传递的
Python 函数参数传递采用的是对象引用传递,也就是将对象的引用(类似于指针)传递给函数,而非对象本身。- 不可变对象:不可变对象(像整数、浮点数、字符串、元组等)一旦创建,其值就无法改变。当把不可变对象当作参数传递给函数时,函数内部对参数的修改不会影响到函数外部的原始对象。
- 可变对象:可变对象(如列表、字典、集合等)在创建之后,其内部状态可以改变。当把可变对象作为参数传递给函数时,函数内部对参数的修改会影响到函数外部的原始对象。
-
函数参数类型有哪些?
Python 函数参数还有不同的类型,分别是位置参数、关键字参数、默认参数、可变参数(*args 和 **kwargs)。- 位置参数:依据参数在函数定义时的顺序,依次传递对应的实参。
- 关键字参数:调用函数时,通过指定参数名来传递实参,这样就不用按照函数定义时的参数顺序传递。
- 默认参数:在函数定义时,为参数指定默认值,若调用函数时没有提供该参数的值,就会使用默认值。
- 可变参数:
*args用于接收任意数量的位置参数,这些参数会被封装成一个元组。**kwargs用于接收任意数量的关键字参数,这些参数会被封装成一个字典。
-
异常有哪些
- NameError:当使用未定义的变量、函数或类名时会抛出该异常。
- TypeError:在操作或函数调用中使用了不适当的数据类型时会触发此异常。
- IndexError:当使用的索引超出序列(如列表、元组、字符串)的有效范围时会抛出此异常。
- KeyError:在字典中尝试访问不存在的键时会引发此异常。
- ValueError:当函数接收到正确类型但值不合适的参数时会抛出此异常。
- FileNotFoundError:尝试打开一个不存在的文件时会触发此异常。
- ZeroDivisionError:在进行除法运算时,除数为零会抛出此异常。
-
finally的作用是什么
不存try-except结果是什么样的,最终都会执行fianl后的语句
高效使用GPU
-
运行xB的大模型,需要显存多大?
xB * 2 -
采用ZeRO 3的时候,全量微调xB的大模型,需要显存多大?
xB * 16 -
FP16和BF16的区别是什么?什么时候使用?
FP(Floating Point)16的指数位是5位,尾数位为10位。BF16(Brain Floating Point)的指数位是8位,尾数位为7位。因此,FP半精度浮点数的精度更高,而BF半浮点数的可表示范围更大。
在混合精度训练时,常使用BF16。因为FP32和BF16的指数位相同,进行转换时,相比于FP16更容易。FP16的指数位小于FP32,因此可能会出现溢出问题。
在推理阶段,由于不需要反向传播训练,因此数值范围变化较小,更常采用FP16。
详解FP16和BF16的区别、大模型训练BF16和FP16总结 -
混合精度训练的目的?
混合精度训练是一种在训练过程中同时使用 fp16 和 fp32 的方法。具体来说,混合精度训练将模型参数和前向传播过程中的激活值存储为 fp16,以减少内存消耗。同时,在梯度计算和权重更新过程中使用 fp32,以保持计算的稳定性。混合精度训练能够加快训练速度,有效降低显存占用,因此能够允许我们使用更大的batch size。
预训练
- Transformer相关:
-
Transfomer模型介绍一下
-
讲讲 Q、K、V
-
Transfomer模型中Encoder输出给Decoder的输入参数有哪些?
K和V -
引入多头注意力机制的原因
它允许模型同时关注来自不同位置的信息。通过分割原始的输入向量到多个头(head),每个头都能独立地学习不同的注意力权重,从而增强模型对输入序列中的不同部分的关注能力, 增加模型的复杂性和多样性。 -
Transformer组件架构
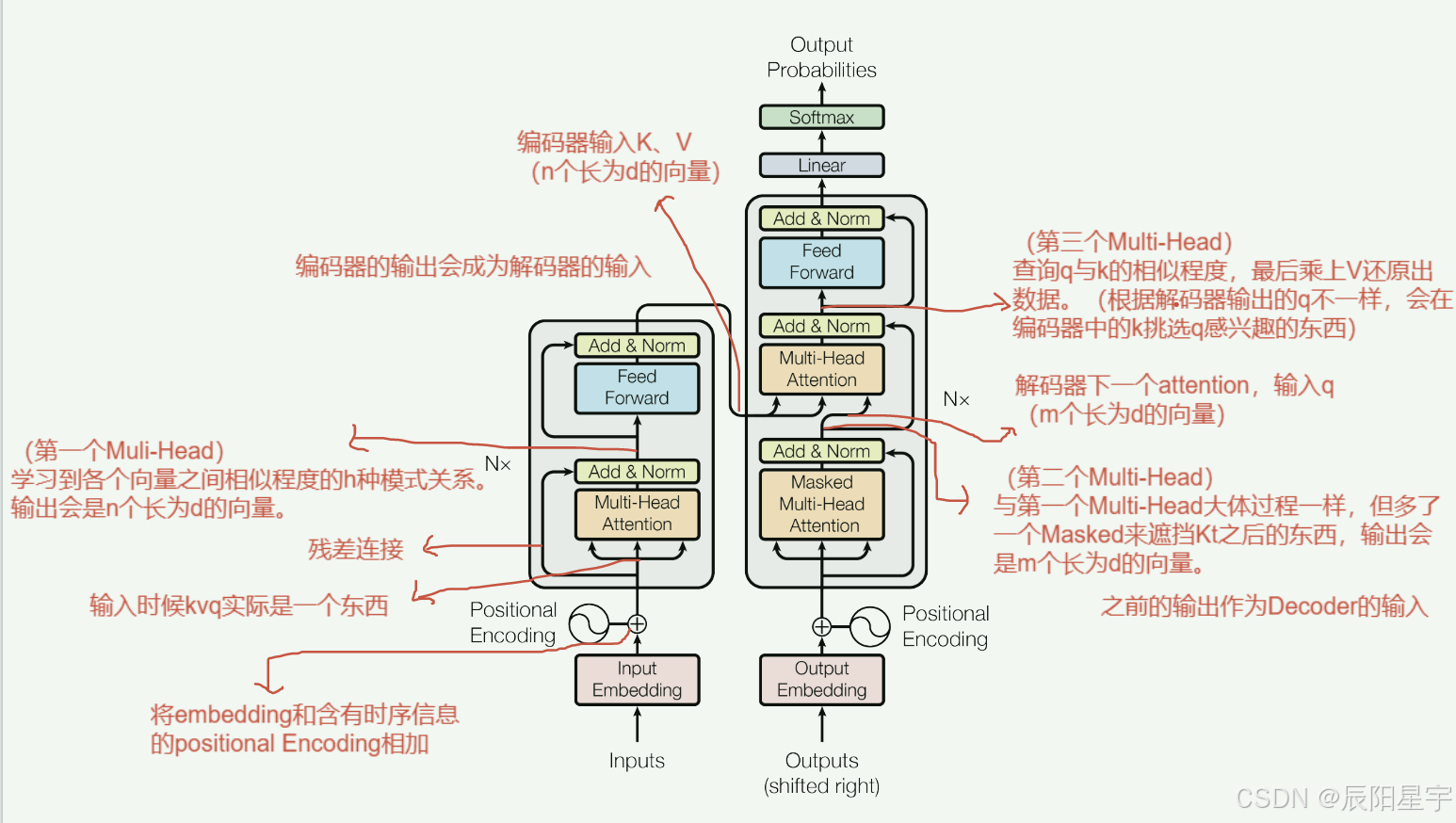
· 多头自注意力机制(Multi-Head Self-Attention)
多头自注意力机制是 Transformer 的关键组件,它允许模型通过多个注意力头(Heads)并行地关注输入序列中的不同位置,从而捕捉丰富的上下文信息。每个注意力头计算一个加权的输入序列表示,而这些加权的表示最终会被拼接或平均,输出最终的注意力表示。
· 前馈神经网络
每个 Transformer 层还包括一个前馈神经网络(FFN),通常由两个全连接层组成。该组件对每个位置的向量进行独立的非线性变换。
· 层归一化
对每个输入样本(而非批次)进行标准化,确保其均值为零,方差为一。这有助于训练时避免梯度爆炸或消失。
· 残差连接
在每个子层的输入和输出之间添加跳跃连接,以防止深度神经网络中的梯度消失问题。
· 位置编码
由于 Transformer 是完全基于自注意力机制的,并没有像 RNN 或 CNN 那样的内在顺序信息,因此必须显式地加入位置编码。位置编码为每个输入嵌入向量添加一个表示位置的向量,通常使用正弦和余弦函数生成。
· Dropout
为了防止过拟合,Transformer 中还引入了 Dropout,它在训练过程中随机丢弃一定比例的神经元,通常应用于:自注意力机制的计算、前馈神经网络的输出、层归一化前的结果。
- 讲讲padding的类别和使用举例
有left_padding和right_padding。
GPT会使用 left_padding
BERT会使用 right_padding
- 梯度突然消失和突然爆炸,如何排查问题
1、考虑激活函数
2、考虑数据
3、考虑学习率等参数
- 讲一讲Deepspeed和ZeRO
- Deepseed
1、Deepspeed用于高效并行计算,支持数据并行 、模型并行和流水线并行等。
2、内存优化技术中引入了ZeRO(Zero Redundancy Optimizer)技术,通过优化模型状态的存储和通信来大幅减少所需的内存占用。
3、支持混合精度训练。支持同时使用单精度(FP32)和半精度(FP16)浮点数进行训练,可以在保持模型性能的同时减少内存占用和计算时间。 - ZeRO
1、ZeRO通过优化模型状态的存储和通信来大幅减少所需的内存占用,使得在有限的内存资源下训练更大规模的模型成为可能。
2、ZeRO的核心思想是将模型的参数、梯度和优化器状态进行分片,并平均分配到所有的GPU中。这样,每个GPU只存储一部分数据,从而减少了单个设备的内存需求。
同时,ZeRO还通过动态通信调度在分布式设备之间共享必要的状态,以保持数据并行的计算粒度和通信量,进一步减少内存占用。
3、ZeRO提供了多个优化级别,包括ZeRO-1、ZeRO-2和ZeRO-3,每个级别都在前一个级别的基础上减少更多的内存冗余。
例如,ZeRO-1主要优化优化器的存储,ZeRO-2进一步优化模型参数和优化器状态的存储,而ZeRO-3还包括对激活的优化。随着优化级别的提高,能够支持的模型大小也随之增加,但同时对集群的通信和计算能力要求也更高。
- 预训练过程中都使用了哪些数据?
常识知识、多语种、代码数据、数学题等
-
为什么加入代码题能提升模型的推理能力?
-
为什么现在大部分预训练模型都用Decoder-only?
-
为什么预训练语言模型不用Encoder-onley或者Encoder-Decoder?
-
介绍一下Llama2和传统的Transformer模型架构上的区别
1、归一化层。采用RMSNorm,它移除了LayerNorm中的均值项,由于没有计算均值,所以方差计算也没有了减去均值的操作,使它的计算效率更高。归一化层被前置。
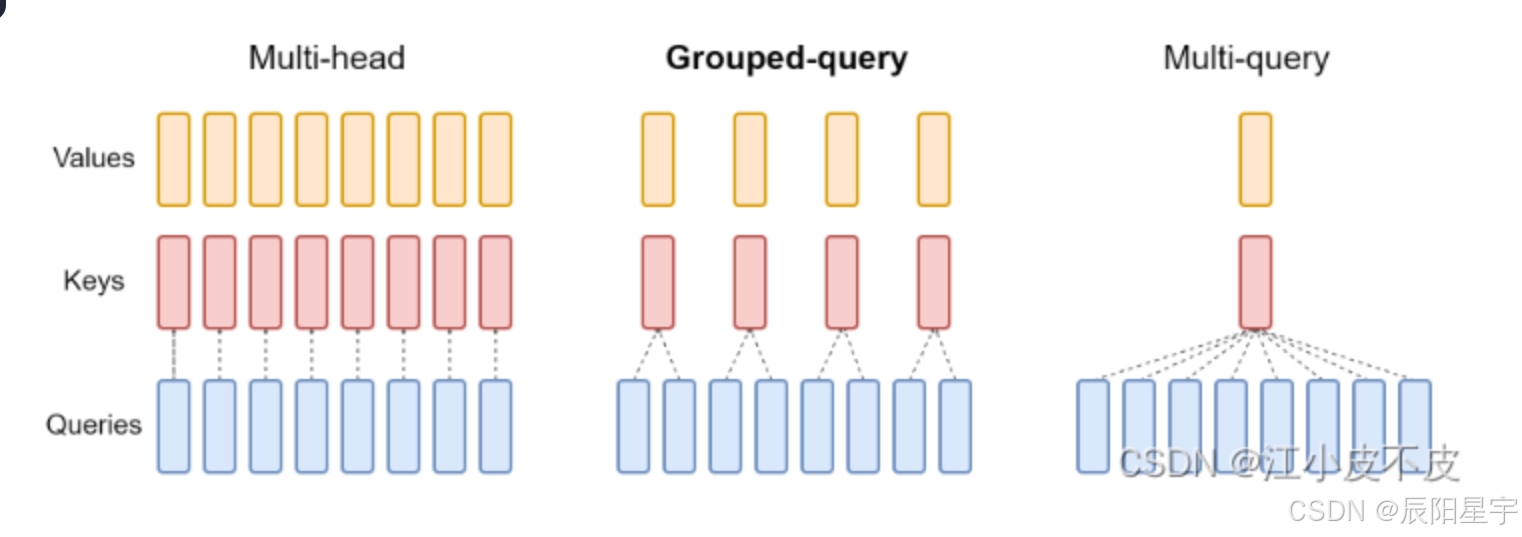
2、多头注意力机制。Llama2采用GQA,组内共享同一个K和V,每个Q都有自己独立的参数不共享。
Llama采用MQA多查询注意力。它是MHA多头注意力机制的改进算法 。
传统的MHA中,每个Q、K、V都有各自的参数,而MQA中,只有Q才有各自的参数,K和V的参数共享。通过在head之间共享相同的K和V转换,参数和操作的数量大大减少。
3、位置编码。RoPE。Transformer模型通常在输入序列经过Embedding层后只做一次位置编码,而llama2模型选择在每个Attention层中分别对Query(Q)和Key(K)进行旋转位置编码(Rotary Positional Embedding,RoPE),即每次计算Attention时,都需要对当前层的Q和K进行位置编码。
RoPE是利用绝对位置编码表示相对位置的一种方式,不仅保持位置编码,还能保持相对位置的关系。
4、激活函数。传统的Transfromer采用的是ReLU,而Llama采用的是SwiGLU。
(1)ReLU:f(x) = max(0, x)。有点是计算简单,具备稀疏性,可以输出真正的零,有助于训练深度网络。缺点是当有一个梯度过大的流进入ReLU后,若被更新为0,则以后该神经元的梯度就永远为0。如果学习率设置过大,会导致过多神经元都失活。
(2)SwiGLU:Swith激活函数和GLU门控单元的组合。它是一个GLU,但不是将sigmoid作为激活函数,而是使用ß=1的swish:SwiGLU(x) = Swish(W1x+b) ⊗ (Vx+c)。
其中,Swith激活函数 Swish(x) = x*sigmoid(ßx),Swish是个处处可导的非线性函数。
(3)GLU门控单元是一种门控结构(有参数),通过sigmoid控制各个维度的激活程度。 GLU(x) = sigmoid(W1x+b)⊗(Vx+c)。GLU可以有效地捕获序列中的远程依赖关系,同时避免与lstm和gru等其他门控机制相关的一些梯度消失问题。
MHA、GQA、MQA的区别:
- 特殊分割符号
[MASK]:表示这个词被遮挡。需要带着[],并且mask是大写,对应的编码是103
[SEP]:表示分隔开两个句子。对应的编码是102
[CLS]:用于分类场景,该位置可表示整句话的语义。对应的编码是101
[UNK]:文本中的元素不在词典中,用该符号表示生僻字。对应编码是100
[PAD]:针对有长度要求的场景,填充文本长度,使得文本长度达到要求。对应编码是0
-
Deepseek的训练为什么快?
因为它是MLA(多头潜在注意力机制)而不是MHA。其中,把Q变成了类似于LoRA里的AB(把 KV 降维到一个潜在向量C,当需要计算时再把C升维到 KV),参数量减少了所以快。
DeepSeek V3推理: MLA与MOE解析 -
讲讲MoE架构
MoE的特点是每个FFN中有多个并行的线性层,训练完后实现特定的输入,映射到特定的几个线性层中。 -
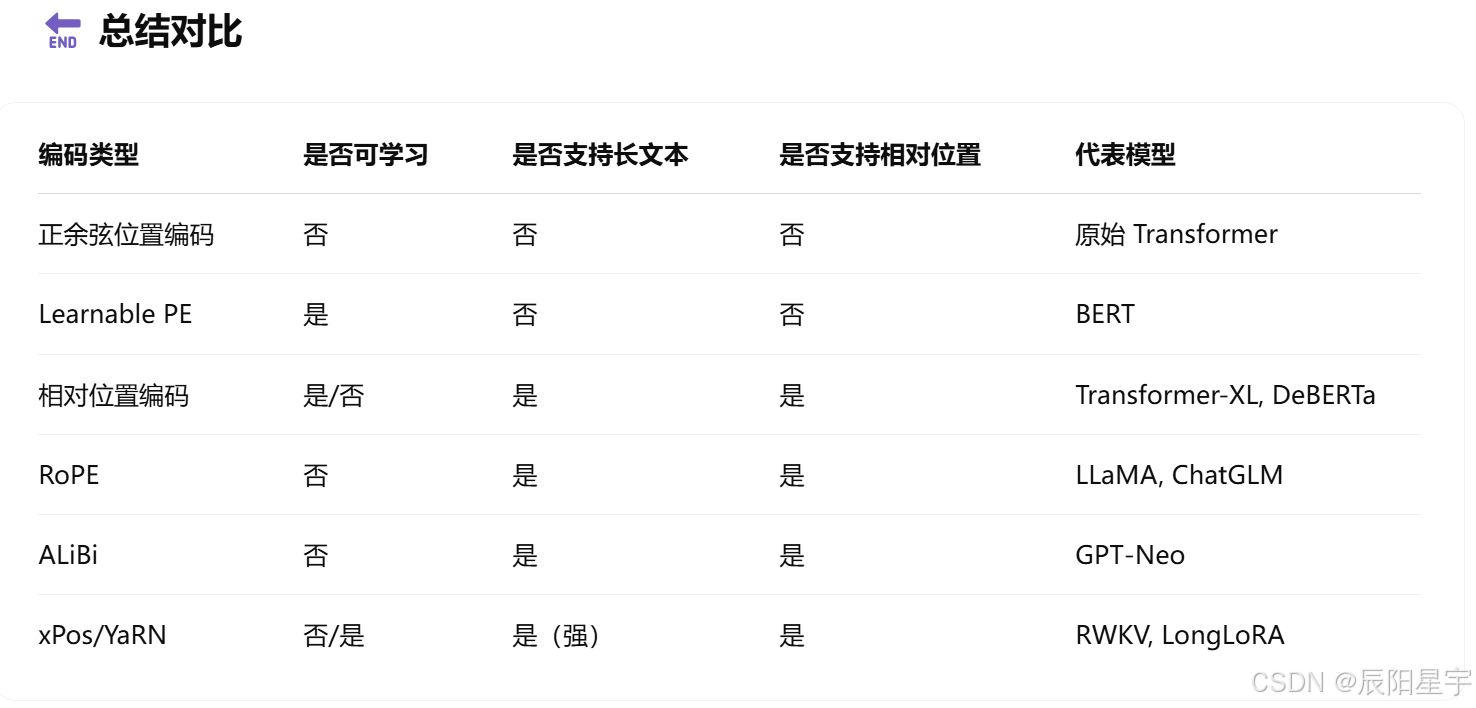
讲讲你知道的位置编码




SFT阶段
- 如何制作SFT数据
- 如何制作长文数据
- 讲讲正向数据和反向数据制作
- 如何去解决敏感数据问题
- SFT阶段的目的是什么
1、激发垂直领域知识
2、引导LLM的输出内容的风格、输出形式等等
- 采用什么比例进行微调,为什么采用这个比例进行微调?
- 讲一讲高效微调这几种方法
- 1、LoRA(Low-Rank Adaptation)
LoRA(Hu et al., 2021)是一种基于低秩分解的微调方法,主要用于减少存储和计算开销,同时保持或接近全参数微调的性能。
LoRA 主要针对 Transformer 结构中的 线性层(Linear Layer) 进行低秩分解,假设全参数微调直接对权重 W 进行更新,而 LoRA 通过引入 低秩矩阵近似 来减少参数更新的维度。- 优势:减少参数更新量、加速训练、兼容性强、无需额外存储完整模型副本
- 适用场景:大模型、计算受限、多任务学习(可为不同任务存储多个LoRA适配器,而不是复制整个模型)
- 2、Adapter
Aadpter (Houlsby et al., 2019) 在 Transformer 的 每个层之间 插入一个小型的 瓶颈层(Bottleneck Layer),它包含:
· 降维层:将隐藏状态维度从 𝑑降到一个较小的维度r
· 非线性变换(ReLU、GELU)
· 升维层:再将维度恢复到 𝑑
Adapter 只训练这部分额外的参数,而不改变原模型权重。
Adapter vs. LoRA
Adapter 插入额外层,改变了前向传播路径,可能影响推理速度
LoRA 仅调整权重,计算效率更高 - 3、Prompt Tuning
Prompt Tuning (Lester et al., 2021) 直接优化一个 可训练的 Prompt 嵌入,用它替换人工设计的 Prompt,以适应不同任务。
Prompt Tuning vs. LoRA
Prompt Tuning 适用于超大模型(如 GPT-3),避免参数更新
LoRA 适用于更广泛的场景,适配不同 Transformer 模型 - 4、Prefix Tuning
Prefix Tuning (Li & Liang, 2021) 通过在 输入序列前面 添加一个 可训练的前缀向量,并将其引入 Transformer 的注意力机制,而不改变原模型参数。
Prefix Tuning vs. LoRA
Prefix Tuning 适用于文本生成任务,如 GPT 系列
LoRA 更通用,适用于多种 Transformer 任务
对比:

8. SFT的损失函数
9. 训练时,loss曲线抖动过大常见原因:
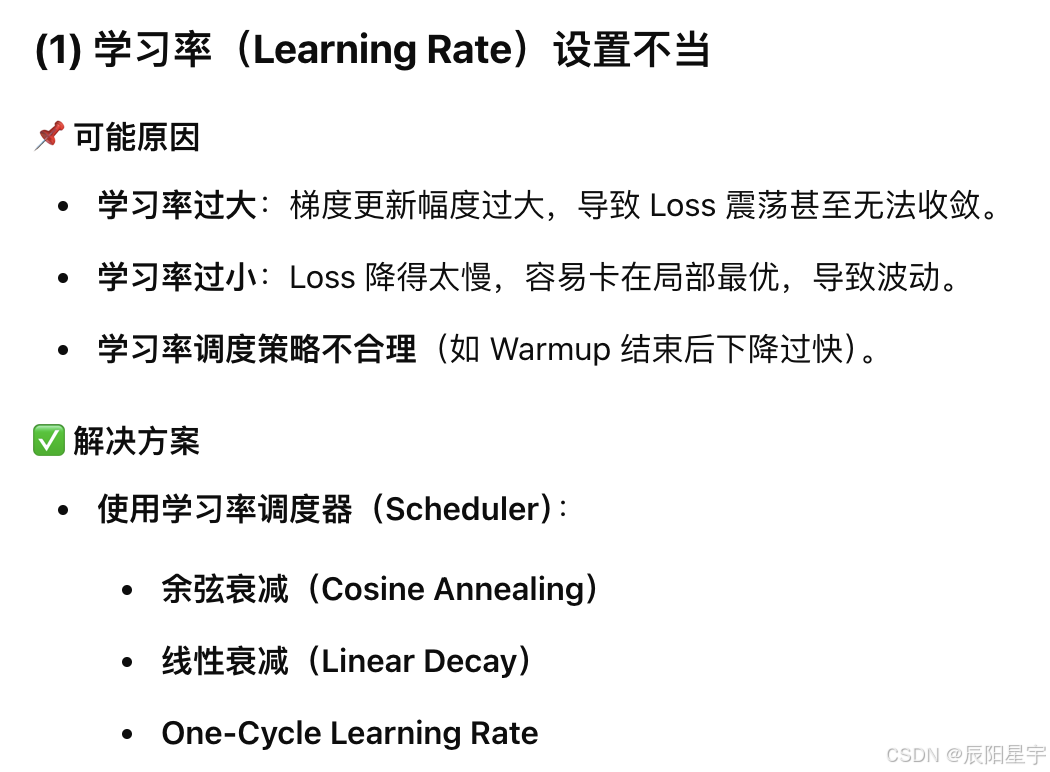


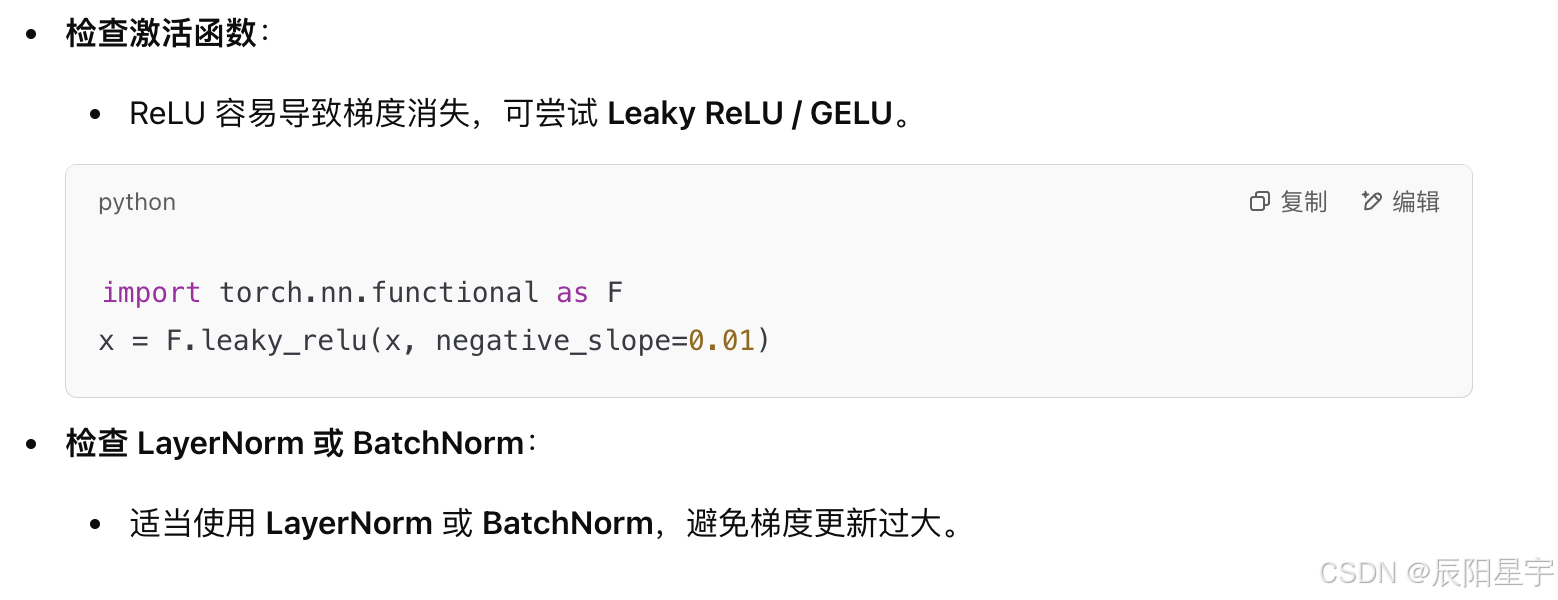




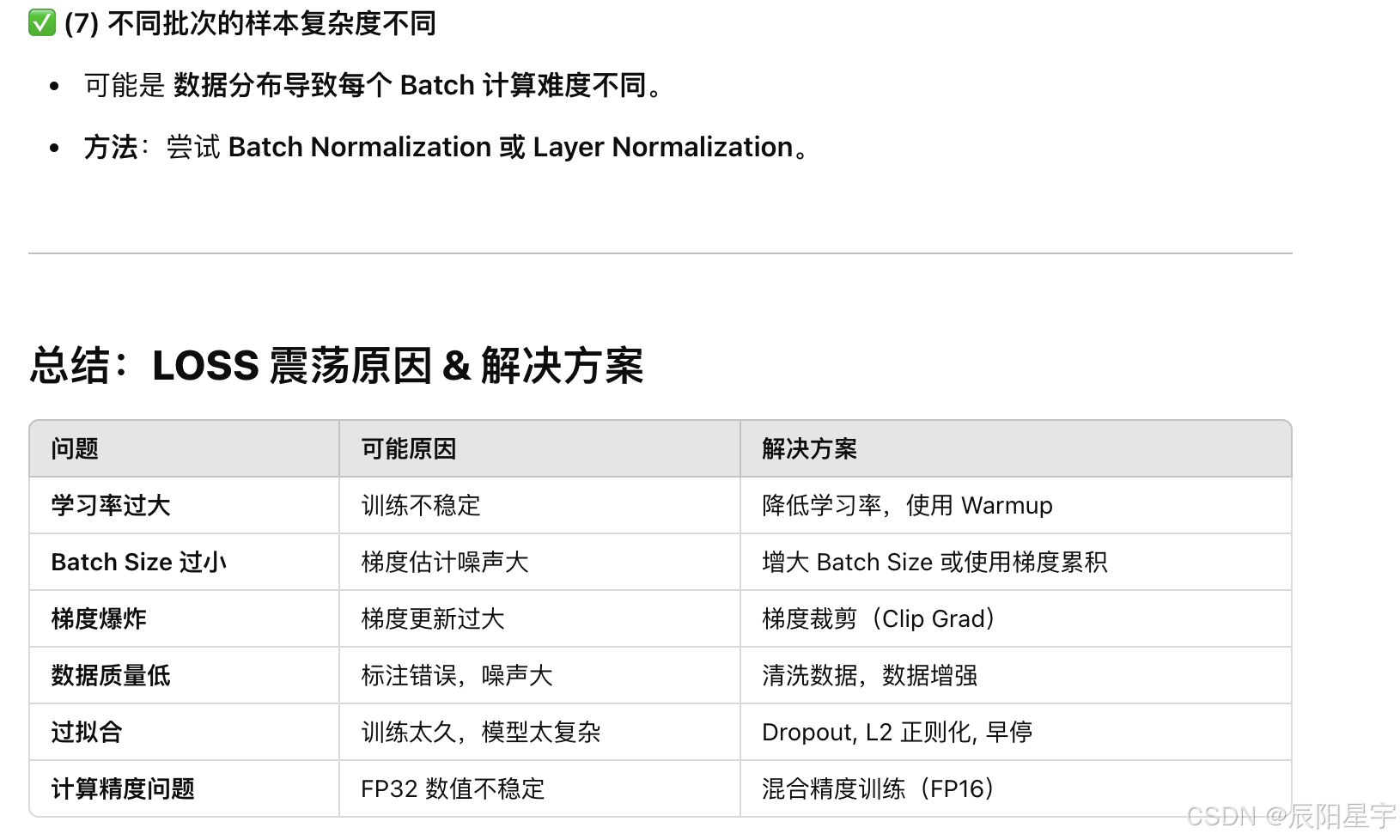

10. 训练时,Loss曲线上升是什么原因?





-
如何将LoRA训练的权重merge到模型里?
将A和B矩阵相乘后,矩阵中对应的位置加到原模型矩阵中 -
A和B矩阵的初始化数是什么?
A按照高斯分布初始化,B全部初始化为0。全部初始化为0的原因是为了保证A乘B为0,让AB相加到模型原权重时候整体值和模型原权重保持一致,保证是从原模型权重开始训练。然后,训练完一轮反向传播后,A和B被更新。 -
模型训练时候学习率设置
LoRA参数设置一般为1e-4 ~ 5e-5
全量参数设置一般为1e-5 ~ 6e-5
LoRA学习率一般要大于全量的学习率,因为LoRA参数少可以快一点避免陷入局部最优,全量参数多需要小一点,保证学习更充分一些。 -
哪些参数会影响训练效果?
epoch: 迭代步数,过小会欠拟合,过大会过拟合。最好的曲线是最后一小段区间趋近于不变,则到达拟合能力上限。
batch_size:小一点增强泛化性,但是更新次数变多速度变慢。大一点更新速度更快,更新更稳定一些。
learning rate: 根据模型参数多少设置学习率,参数少学习率大,参数大学习率小。
num warmup steps / num warmup rate: 预热学习步数/比率,前期时候学习率小一点,让训练更稳定,然后再逐渐增大。
Aligment阶段
强化学习基础知识
- 强化学习中有哪些价值函数
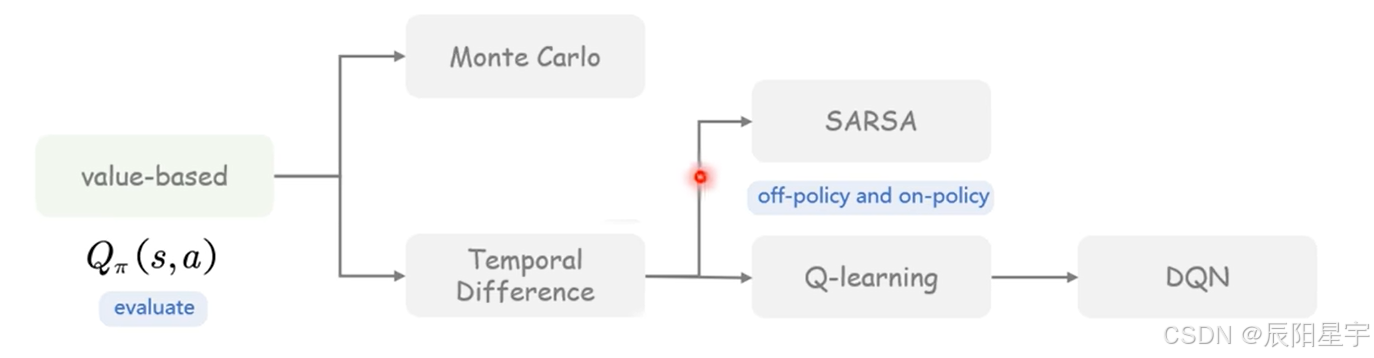
主要有两种,基于蒙特卡洛的方式和基于时序差分的方式。

 蒙特卡洛方法就是生成多个结果,最后求一个均值。
蒙特卡洛方法就是生成多个结果,最后求一个均值。

蒙特卡洛是多步的方式,它的方差会比较大,偏差会比较小。由于采样数据很多,所以会出现方差大的情况,但是由于经过了多次采样后,就会让他的偏差变小。

时序差分的方法就是用真实的值,来更新当前状态下的值
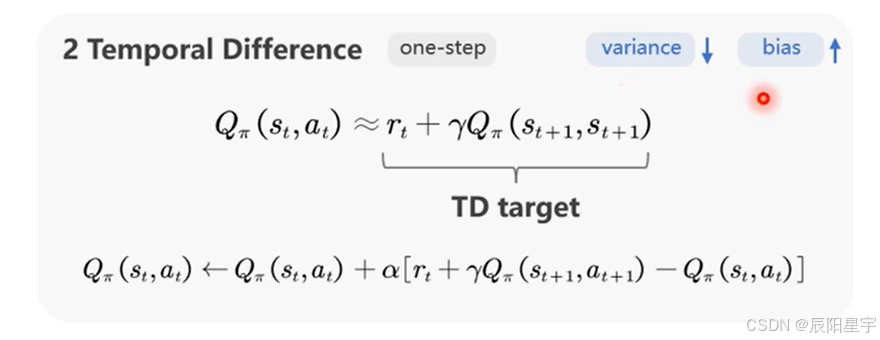
蒙特卡洛是单步的方式,它的方差会比较小,偏差会比较大。由于只对一步进行更新,所以会出现方差不会很大,但是由于只采样一次,会导致偏差变大的情况。
- SARSA算法和Q-Learning算法
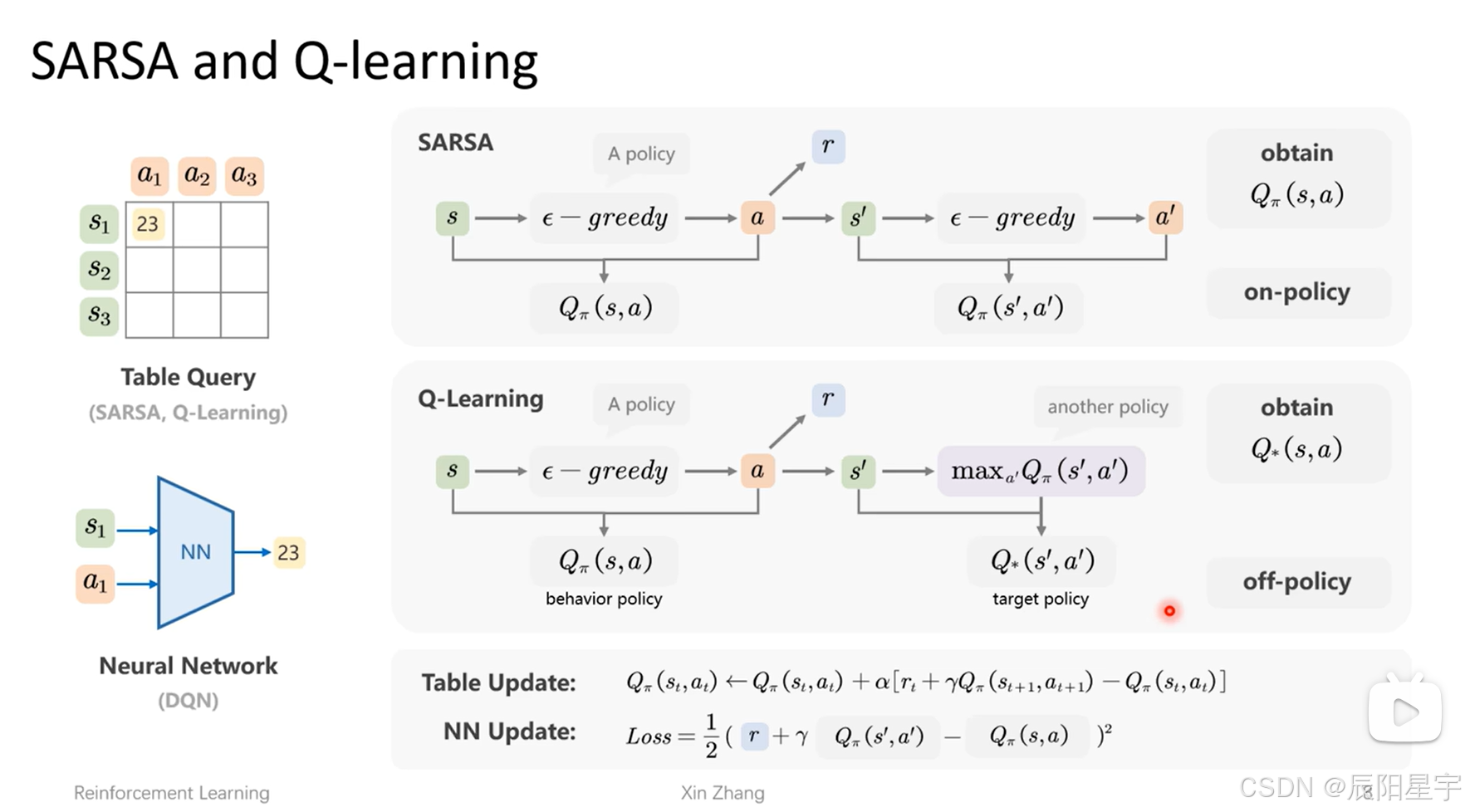
- SARSA:第一步和环境交互后,得到一个价值、一个奖励和下一个状态,第二步会从当前状态生成下一个动作和一个价值。由于第一步行为策略和第二步目标策略都相同,因此为同策略,就是on-policy
- Q-Learning:第一步得到一个价值、一个奖励和下一个状态,下一步会用一个策略从表中所有价值中选出一个最高价值得到,不需要再生成一个动作。由于第一步行为策略和第二步目标策略不同,是一个异策略,就是off-policy。
- 有了当前和下一步的价值后,可以对Table或者NN进行更新。

- 讲讲优势函数
优势函数衡量某个动作在某个状态下,相比于策略平均水平,究竟好了多少。我做出这个动作,相比于刚才的状态,优势有多少。

状态动作价值Q减去其状态动作价值的均值。

- 其中V是怎么算出来的?
多次采样的均值。
- 策略有哪些
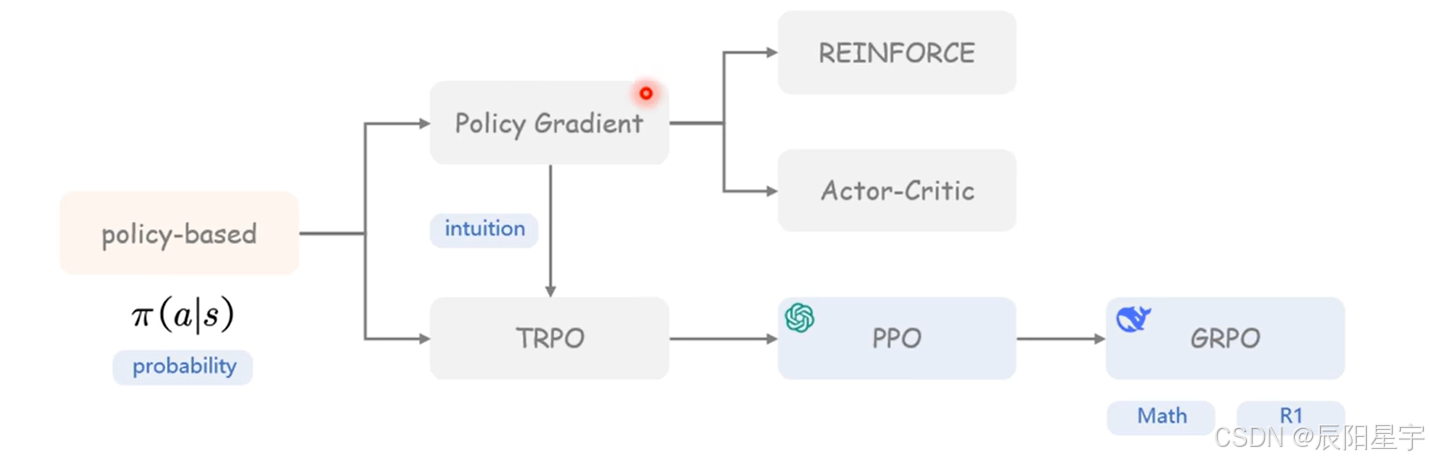
策略梯度

对动作求一个梯度,再对动作求一个价值,得到多次采样的期望值。我们希望最终能让Q值大的动作策略值也大。
策略梯度算法

TRPO

PPO

4. on-policy和off-policy
on-policy:采集数据和训练模型的策略是同一个,采集的数据只能用一次就被丢弃,需要重新采集,导致训练速度慢。第一步产生动作策略和第二步动作策略是同一个策略,同策略。
off-policy:采数据集和训练模型的策略不是同一个,采集的数据可以用来被多次训练,加快训练速度。第一步产生动作策略和第二步动作策略不是同一个策略,异策略。
Reject sampling
为解决ppo训练过于复杂的问题,使用拒采样的方式来优化模型。
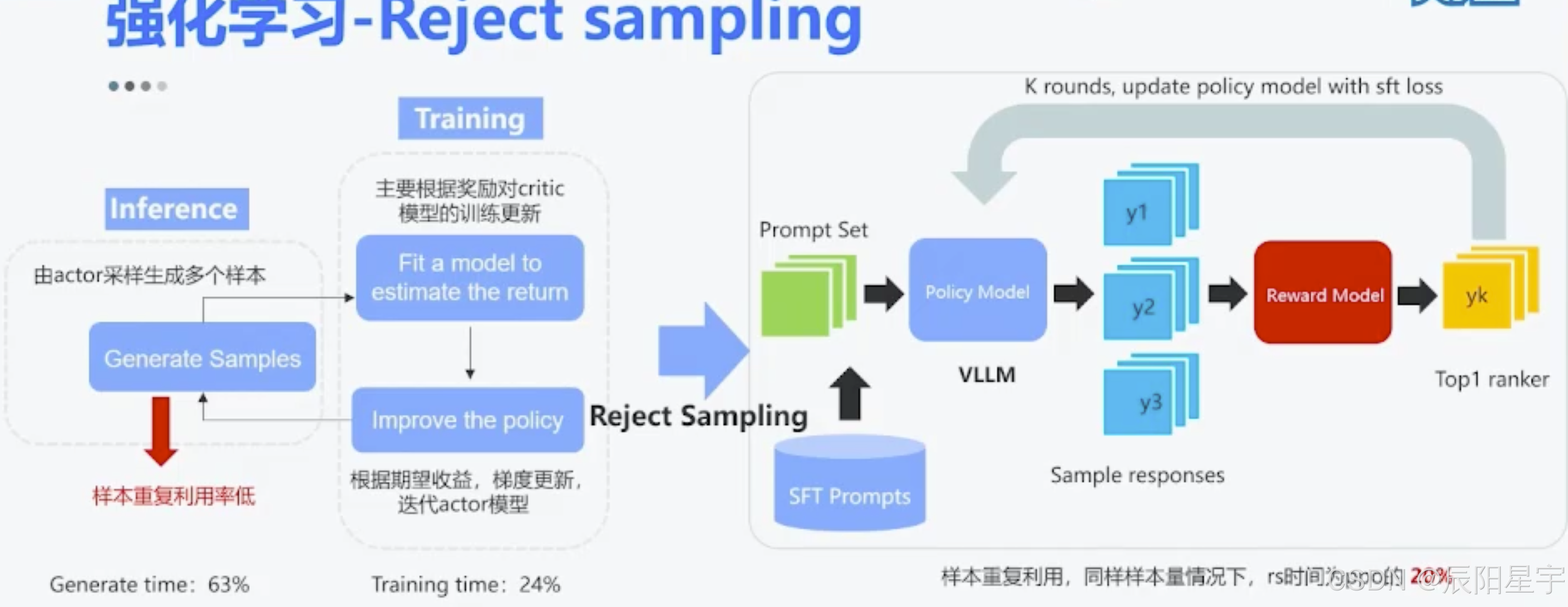

使用reward model对生成的多个response进行打分,选取top-k再使用SFT方式训练给模型。
DPO
- 讲一讲DPO
大模型中的DPO(Direct Preference Optimization,直接偏好优化)技术是一种用于将语言模型(LM)的行为与人类偏好对齐的方法。DPO技术的核心思想是直接优化语言模型,以最大化模型生成符合人类偏好的响应的概率。具体来说,DPO通过以下步骤实现:
1、标注偏好数据集(x, y1, y2)
2、优化语言模型。基于标注的数据集和获取的πref,优化语言模型πθ来最小化DPO损失函数。这个损失函数旨在增大偏好响应相较于不偏好响应的log概率,同时包含一个动态的、每个样本上的重要性权重,以避免模型退化。
3、避免过拟合。DPO的一个潜在缺点是容易过拟合偏好数据集。为了缓解这个问题,可以引入正则化项,如身份偏好优化(IPO),以使模型在训练过程中更加稳定。

2. DPO该如何调参

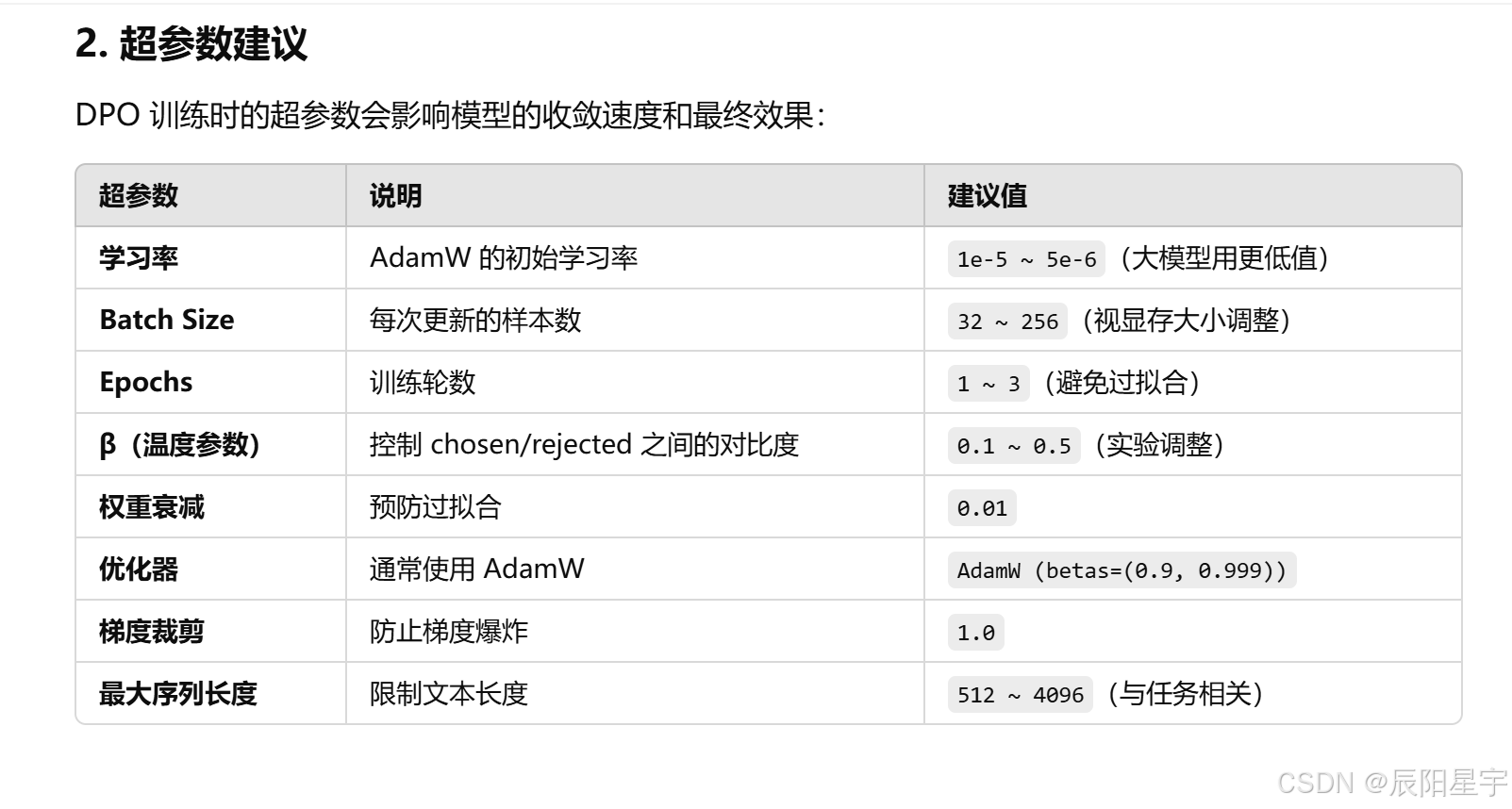
- beta 是 DPO loss 的温度,通常在 0.1 到 0.5 之间。该参数控制了我们对 ref 模型的关注程度,beta 越小,模型训练越忽略 ref 模型。
- dpo_loss_scale:dpo loss 前的权重系数,默认为 1.0,通常保持默认。
- lm_loss_scale:lm loss 前的权重系数,默认为 1.0,启用 lm_loss 时,需显示设置该系数,通常设置为 0~1 之间。


学习率参数:1e-6~5e-7
KL系数:0.2
- 训练指标
示例:
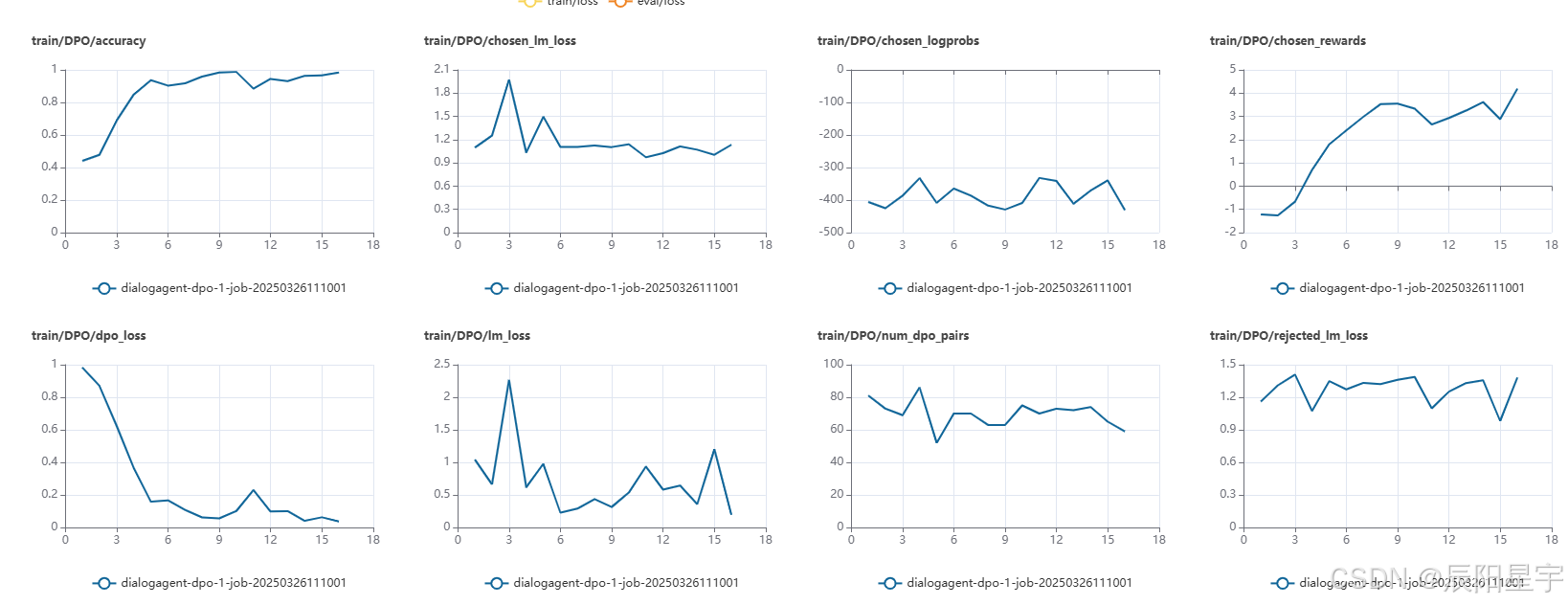
- train/DPO/accuracy
代表 DPO 训练过程中模型在训练数据上的准确率。
曲线从 0.4 迅速上升到接近 1,说明模型在逐渐学习,并且对偏好数据的匹配度在提高。 - train/DPO/chosen_lm_loss & train/DPO/rejected_lm_loss
chosen_lm_loss:被选中(preferred)的文本对应的语言模型损失。
rejected_lm_loss:被拒绝(non-preferred)的文本对应的语言模型损失。
chosen_lm_loss 逐渐稳定在 1 附近,而 rejected_lm_loss 在 1.2~1.4 之间,表明模型在降低对正确选择的损失,并保持 rejected 的损失较高,符合优化目标。 - train/DPO/chosen_logprobs & train/DPO/rejected_logprobs
chosen_logprobs:表示模型对选中样本的 log 概率值(通常为负数,越大越好)。
rejected_logprobs:表示模型对被拒绝样本的 log 概率值(越小越好)。
这两个指标在 -300 到 -500 之间波动,表明模型在试图让 chosen 样本的概率更大,同时降低 rejected 样本的概率。 - train/DPO/chosen_rewards & train/DPO/rejected_rewards
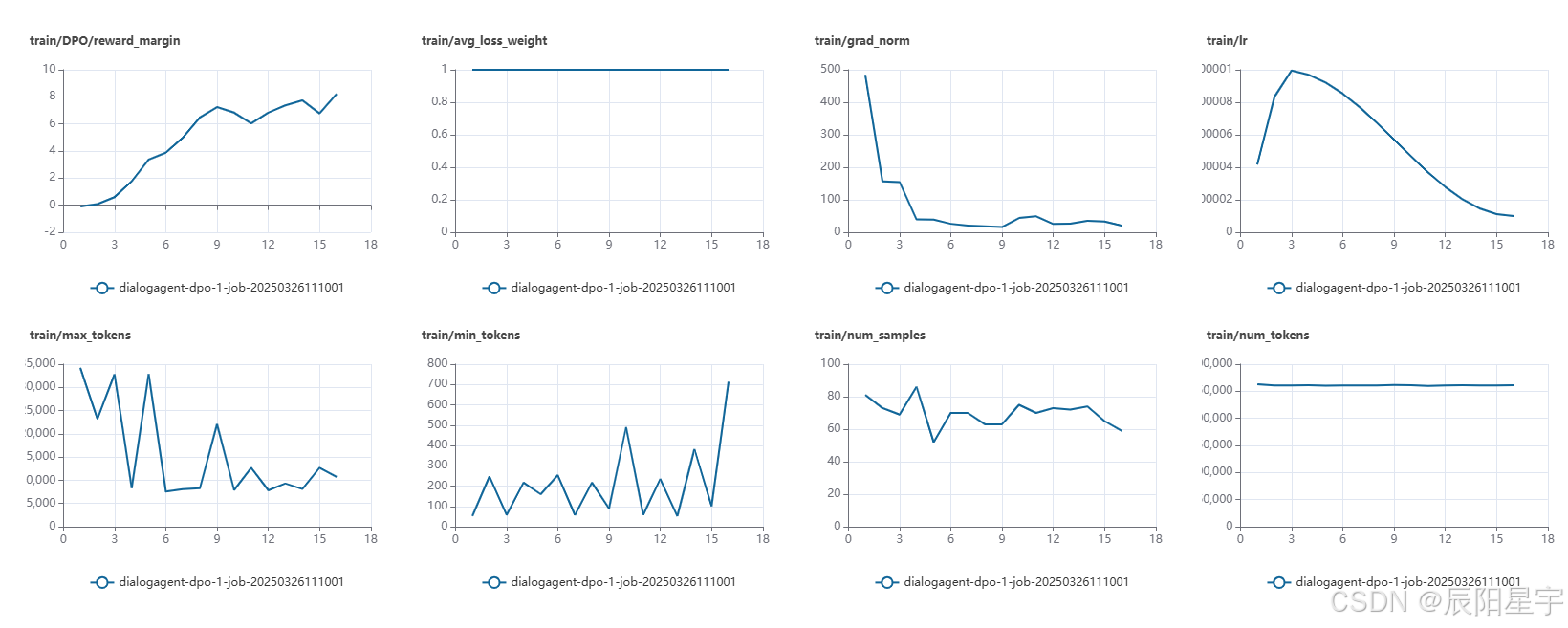
chosen_rewards逐渐从 -2 提升到 4,而 rejected_rewards 逐渐从 -1 降低到 -4,说明 DPO 训练成功在优化 reward 分数。
reward_margin也在增加,说明 chosen 样本的 reward 相较于 rejected 样本的差距变大,符合 DPO 目标。 - train/DPO/dpo_loss
这个是 DPO 训练的核心损失,数值越小代表模型收敛得越好。
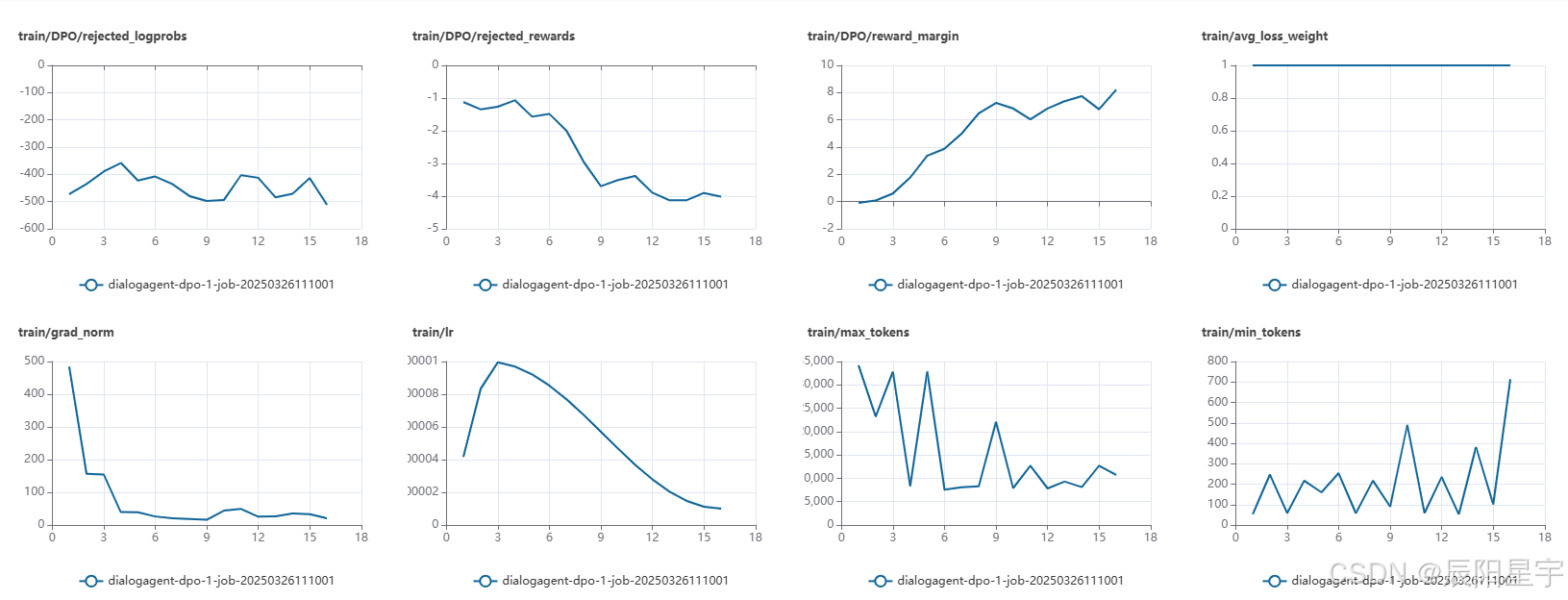
观察曲线,dpo_loss 从 1 迅速下降到接近 0,说明训练效果较好,损失下降。 - train/DPO/num_dpo_pairs & train/num_samples
代表 DPO 训练过程中使用的训练样本对数(偏好对)。
数值基本保持在 60~80 之间,说明训练数据对的数量是稳定的。 - train/grad_norm
代表梯度范数,反映梯度的大小。
梯度从 500 降到较低的水平,说明初始训练阶段梯度较大,但后续训练趋于稳定,符合预期。 - train/lr
代表学习率(learning rate)。
初期迅速上升后逐渐下降,符合常见的学习率调度策略(如 Cosine Decay 或 Warmup + Decay)。 - train/max_tokens & train/min_tokens
max_tokens 变化较大,而 min_tokens 在逐渐增加,说明训练过程中模型输出长度有所波动。

- dpo_loss和chosen_lm_loss与rejected_lm_loss的关系是什么



- DPO算法主要解决PPO算法中的什么问题?
DPO 是为了简化并稳定强化学习对齐流程,相比 PPO,它免去了 reward model 和 KL 正则项,直接优化策略,使得对齐训练更高效、更稳健。



PPO
- PPO有哪些组件,各个组件的作用是什么
1、演员模型:目标训练模型
2、评论家模型:用于判断演员模型产生的动作,未来会获取的总收益有多大。这个模型的参数会被一起更新,用于让评判能力也“与时俱进”。主要实现是在初始的LLM的最后一层加一个求价值的层。
3、参考模型:原始的LLM,参数冻结。保证演员模型和最初的模型训练偏差不会太大,让模型不被训“歪”。
4、奖励模型:判断当前演员模型的动作产生的价值有多大。
- PPO过程中有哪些损失函数
1、策略损失函数:策略损失函数是PPO算法中用于优化策略网络的主要损失函数。它基于 **新旧策略的概率比例**(ratio)和 **优势函数** 来计算。
2、价值损失函数:价值损失函数用于优化价值网络的参数,使其能够更准确地估计给定状态下的未来累积奖励。价值损失函数通常使用均方误差(MSE)或均方根误差(RMSE)来计算预测值与真实值之间的差异。


3. PPO中critic模型是怎么更新的?



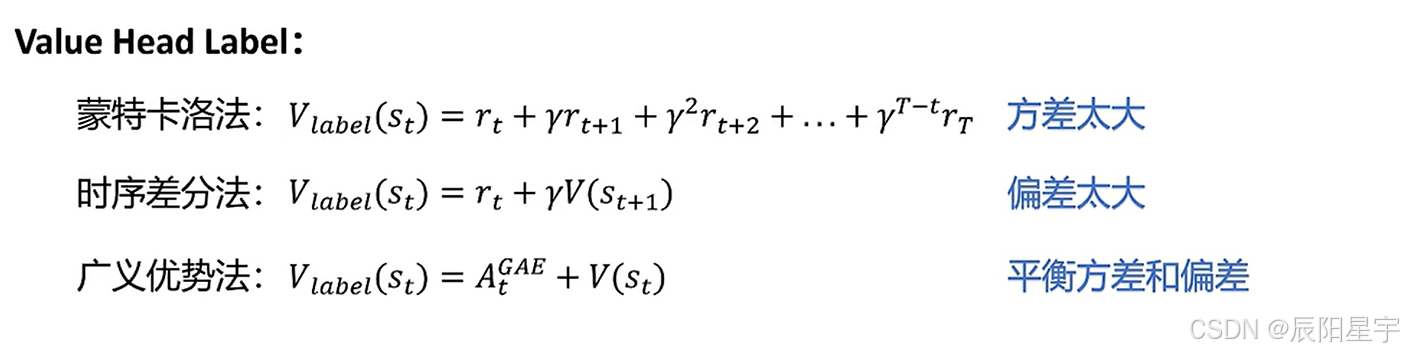



- RM的用途是什么
用于打分,让LLM对我们想要的数据偏好进行对齐。
- 如何训练RM
给RM输入一个价值偏好数据集(x, y1, y2),其中x是输入的数据,y1是正向偏好,y2是负向偏好。然后,更新RM参数,让模型给正向偏好打分更多,负向偏好打分更低。
-
如何对齐LLM
-
退火的作用是什么
让训练时梯度更新不会波动太大,渐进式的更新
- PPO的目的是什么
用于模型对齐,让模型的输出能更符合我们预期的价值偏好
GRPO
- 讲讲GRPO
GRPO把PPO的价值函数去掉了 ,采用规则匹配的方式。每次针对每个会生成一组数据,然后将高于组里平均值的数据进行强化,低于组里平均值的数据进行惩罚。
去掉原因:神经网络奖励函数存在奖励窃取问题。
- GPRO有哪几个模型
GRPO有三个模型,去掉了价值模型。
将计算未来优势的过程,变成了取平均值比较的过程。
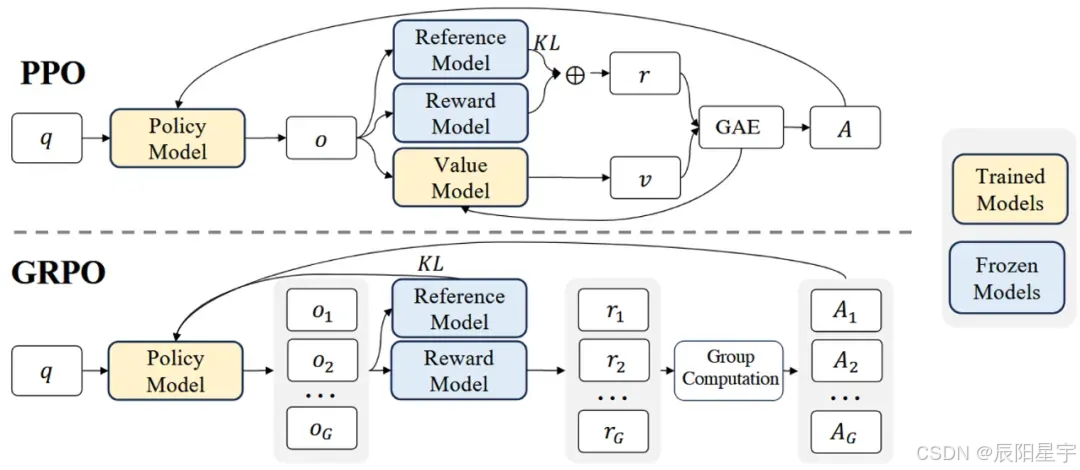
3. 讲讲GRPO的过程

个人开发者也能训练推理模型?GRPO 技术详解
RAG
- 讲讲RAG的过程
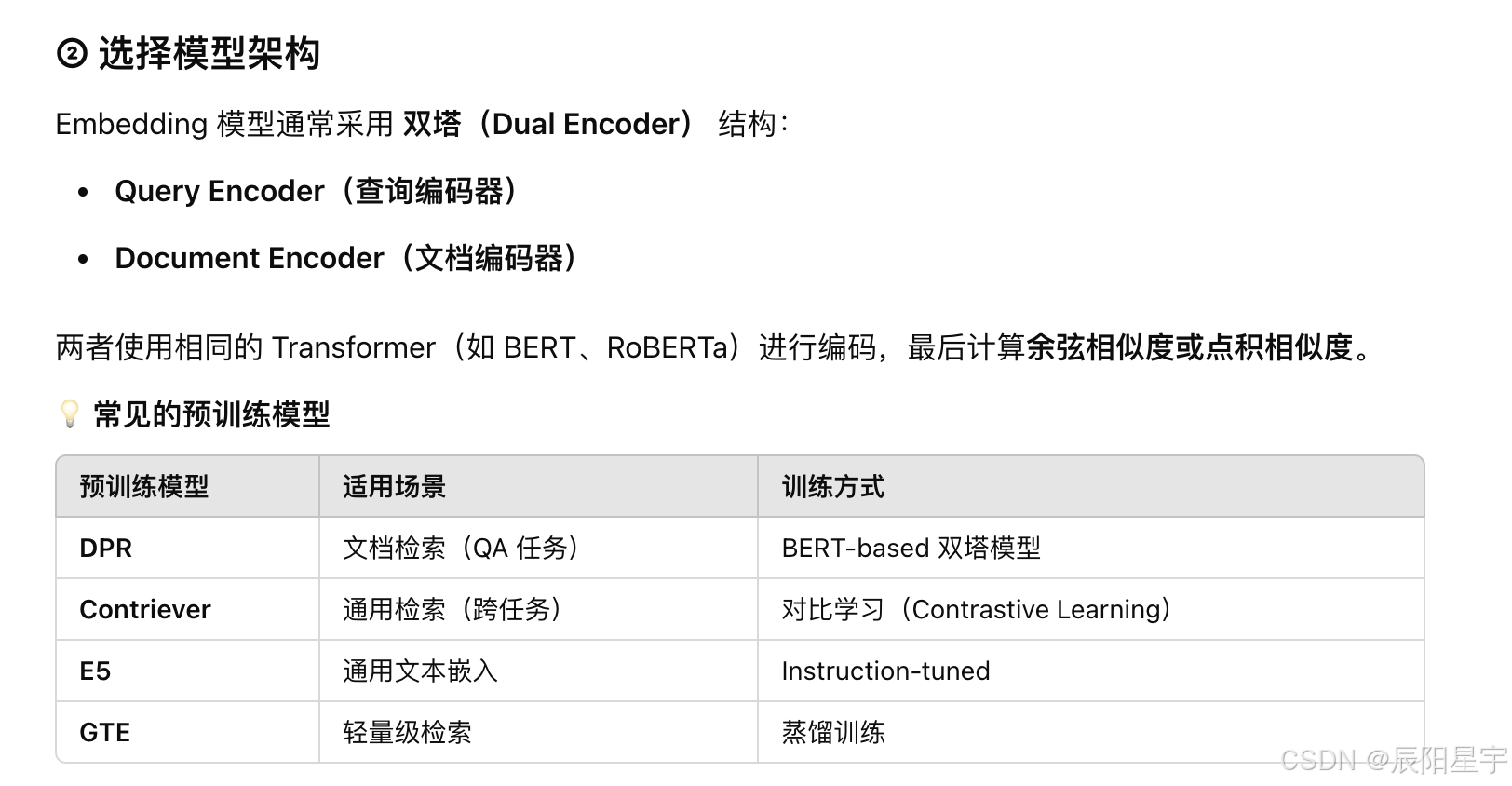
- 讲讲Encoder是如何制作的
- 使用的Embedding是什么
- RAG和事实增强结合起来进行讲解
- RAG中落地时的难点是哪些?
RAG使用时的情景检测;chunk切分;Embedding;粗检;细排re-rank
- 了解哪些chunk切分技术?
根据字数、根据token数、根据语义
- 使用过哪些框架、向量数据库
LangChain
FAISS
-
Embedding的训练方式
-
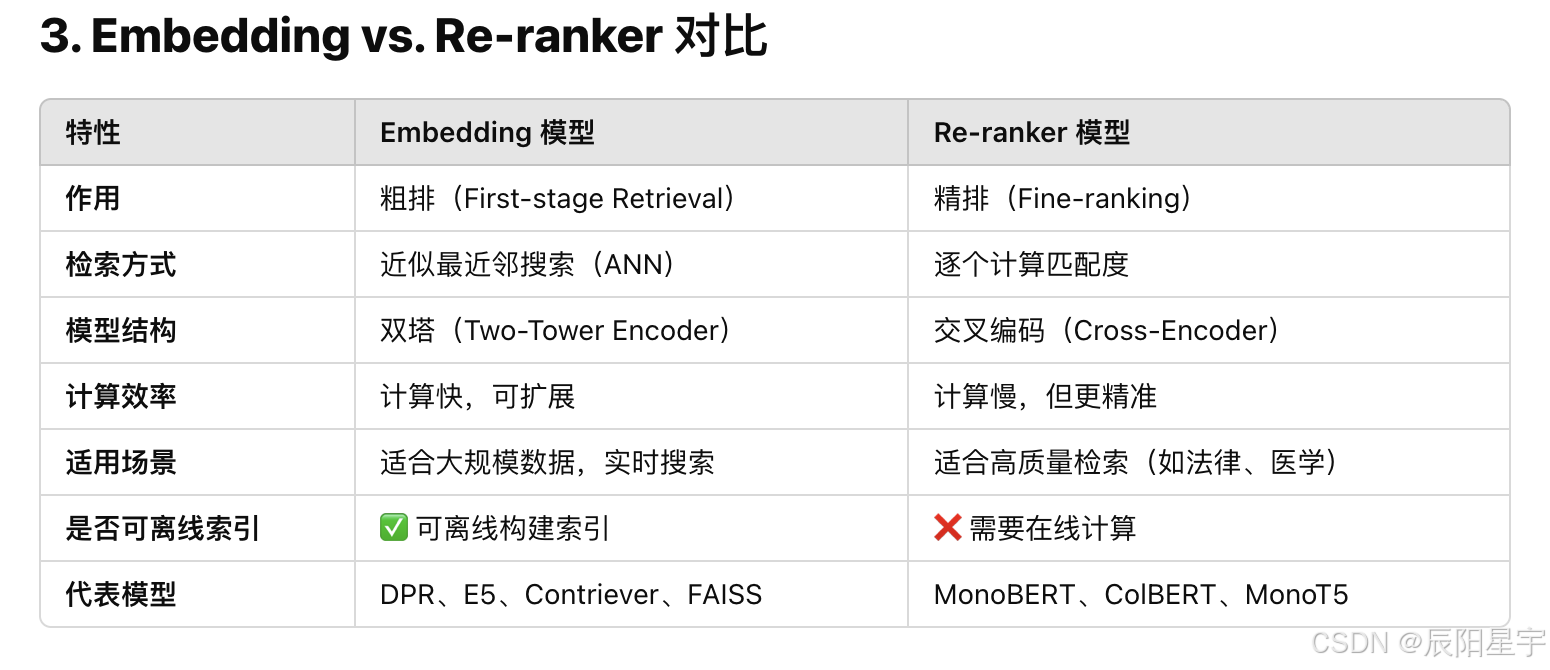
粗排和精排的区别




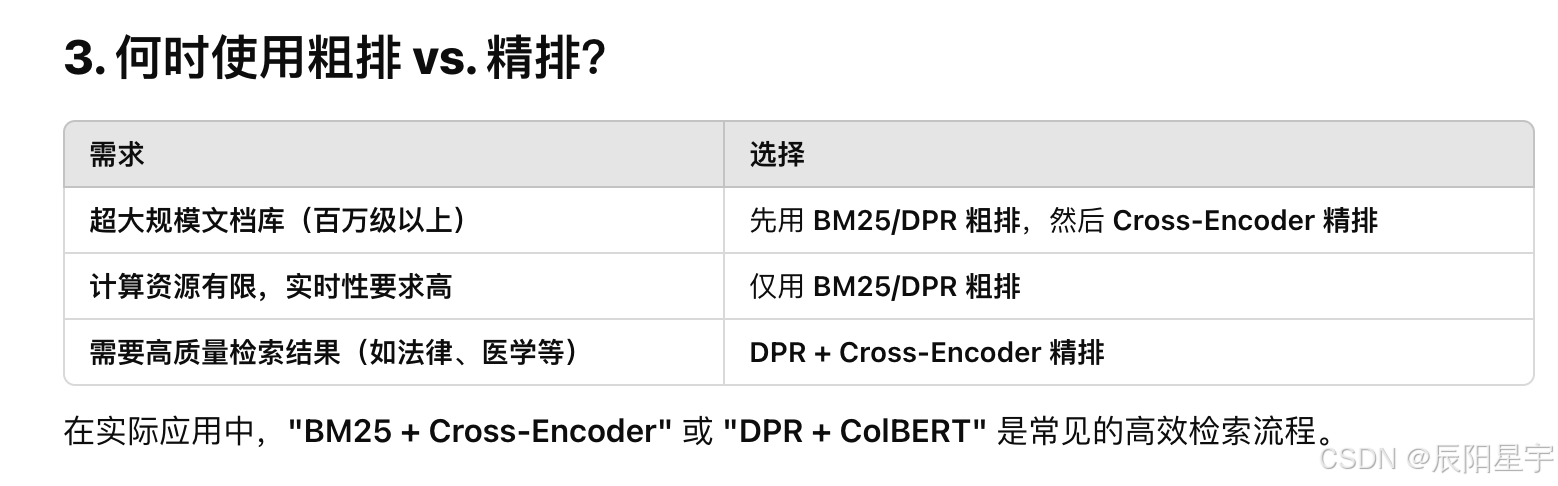
10. Embedding模型和re-ranker模型的区别


11. 讲讲双塔模型

Agent
- Agent的组件都有哪些
LLM任务规划、记忆组件、prompt模版、工具
- Agent在完成任务时候执行流程是什么
获取任务、任务分析并将任务分解成子任务、将信息反馈给环境、观察、根据反馈让LLM进行迭代更新
Prompt
- Promp的一些设计技巧
可以引入角色扮演、COT、自我一致性检测、规定输出格式、给示例、肯定句代替否定句
模型推理
- top-k、top-p、temperature、beam search的作用和效果上的体现
- 对比beam search、top-k、top-p
从效果上来看,top-k、top-p的调整要比beam search产生更多的多样性。
模型评估
- 如何去评估它的推理能力


















 3844
3844

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











