







目录
一、AE自编码器
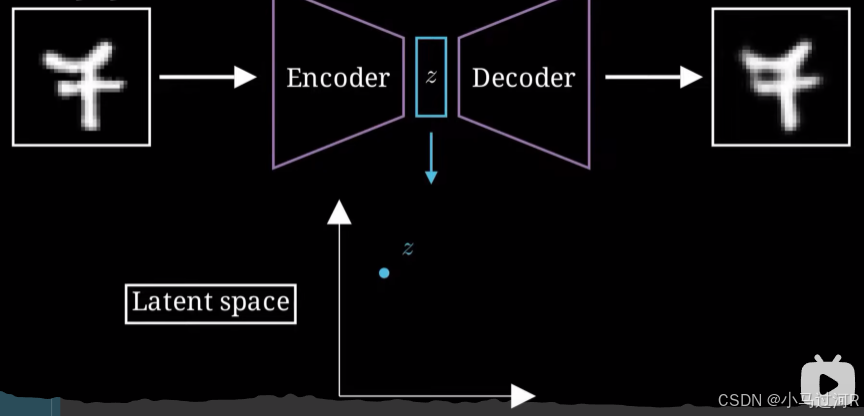
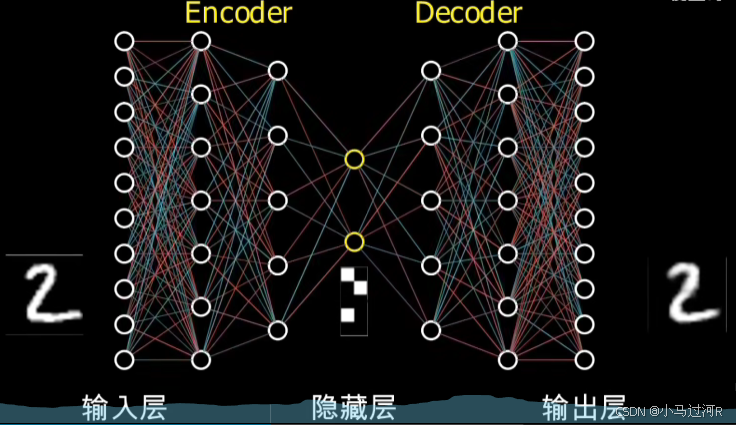
Autoencoder(自编码器,简称AE)是一种无监督学习的神经网络模型,主要用于数据的降维、特征提取和数据重建。其核心思想是通过学习输入数据的压缩表示(即编码),再从中重构出原始数据。Autoencoder由两部分组成:编码器(Encoder)和解码器(Decoder)。
AE的核心组成
编码器(Encoder):
将输入数据映射到一个低维的潜在表示(Latent Representation)。
通常是一个神经网络,用于压缩数据。
潜在空间(Latent Space):
编码器输出的低维表示,是输入数据的压缩版本。
潜在空间的维度通常远小于输入数据的维度。
解码器(Decoder):
从潜在空间中重构原始数据。
通常是一个神经网络,用于将压缩表示还原为原始数据。
AE的工作原理
编码过程:
输入数据通过编码器被压缩到潜在空间,生成一个低维表示。
解码过程:
解码器从潜在空间中重构出原始数据。
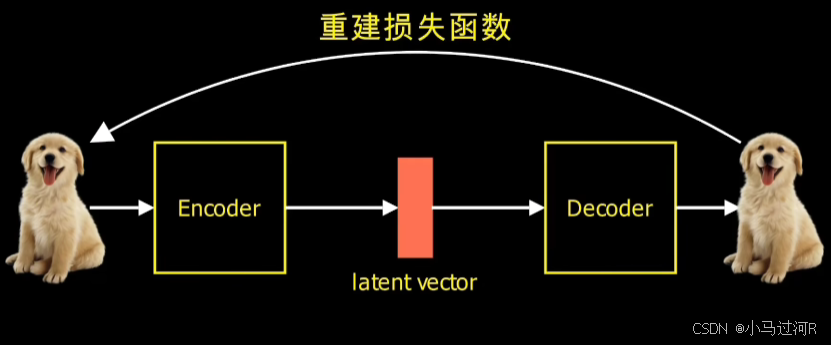
训练目标:
最小化输入数据与重构数据之间的误差(如均方误差,MSE)。
通过这种方式,Autoencoder学习到输入数据的重要特征。
AE的类型
标准Autoencoder:
最基本的自编码器,用于数据压缩和重建。
稀疏Autoencoder(Sparse Autoencoder):
在损失函数中加入稀疏性约束,使得潜在表示更加稀疏。
去噪Autoencoder(Denoising Autoencoder):
输入数据被加入噪声,Autoencoder学习从噪声数据中重建原始数据。
变分Autoencoder(VAE, Variational Autoencoder):
基于概率生成模型,用于生成新的数据样本。
卷积Autoencoder(Convolutional Autoencoder):
使用卷积神经网络(CNN)作为编码器和解码器,适用于图像数据。
AE的应用
数据降维:
类似于PCA,但Autoencoder可以学习非线性映射。
特征提取:
潜在空间中的表示可以作为输入数据的特征,用于后续任务(如分类、聚类)。
数据去噪:
去噪Autoencoder可以用于去除数据中的噪声。
图像压缩与重建:
适用于图像数据的压缩和重建任务。
生成模型:
变分Autoencoder(VAE)可以用于生成新的数据样本。
AE的优缺点
优点:
无监督学习:不需要标签数据,可以从未标记数据中学习特征。
灵活性:可以通过调整网络结构适应不同类型的数据。
降维与特征提取:能够学习到数据的低维表示,适用于高维数据的处理。
缺点:
生成能力有限:标准Autoencoder主要用于数据重建,生成新数据的能力较弱(VAE和GAN更适合生成任务)。
潜在空间解释性差:潜在空间的表示通常难以直接解释。
总结
AE是一种强大的无监督学习工具,广泛应用于数据降维、特征提取、去噪和重建等任务。通过编码器和解码器的协作,Autoencoder能够学习到输入数据的低维表示,并在许多领域(如图像处理、自然语言处理)中发挥重要作用。
二、VAE变分自编码器
这个不是许嵩哈。
VAE(Variational Autoencoder,变分自编码器)是一种生成模型,主要用于学习数据的潜在表示并生成与原始数据分布相似的新数据。其核心思想是通过编码器将输入数据映射到潜在空间,再通过解码器从潜在空间中重构或生成数据。
VAE的核心组成
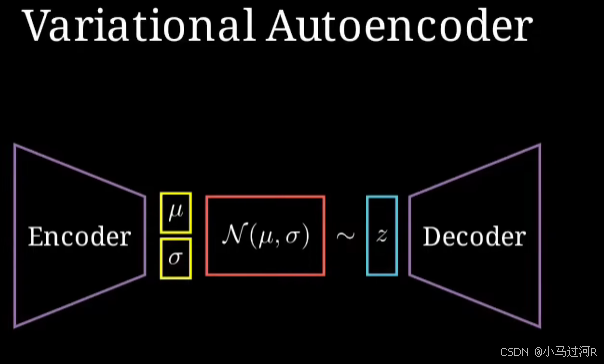
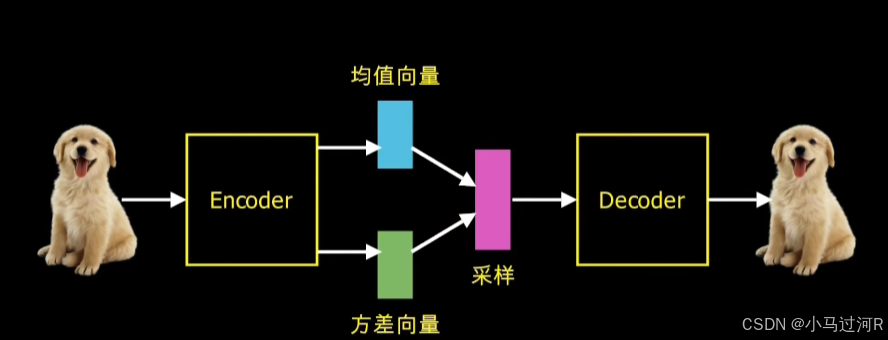
编码器(Encoder):将输入数据压缩为一组隐变量,通常用高斯分布表示,输出均值和方差。
潜在空间(Latent Space):由编码器生成的隐变量构成,用于表示输入数据的潜在特征。
解码器(Decoder):从潜在空间中采样并重构或生成新的数据。
VAE的工作原理
编码过程:编码器将输入数据映射到潜在空间,生成隐变量的分布。
采样与生成:从隐变量分布中采样,通过解码器生成新的数据样本。
训练目标:包括重构损失(确保解码器准确重建输入数据)和KL散度(衡量隐变量分布与先验分布的相似度)。
VAE的应用
图像生成:如Stable Diffusion等模型中使用VAE提升图像生成质量。
数据重建:通过学习潜在表示,VAE能够重建输入数据并生成新的样本。
特征提取:VAE可以用于提取数据的潜在特征,应用于无监督学习任务。
VAE的优势
生成能力:能够从训练数据中建模真实的数据分布,并生成多样化的新数据。
潜在空间连续性:潜在空间的连续性使得VAE能够通过平滑插值生成新的样本。
广泛应用:在图像处理、风格迁移、数据增强等领域表现优异。
VAE通过其独特的编码-解码架构和变分推断方法,成为生成模型领域的重要技术。
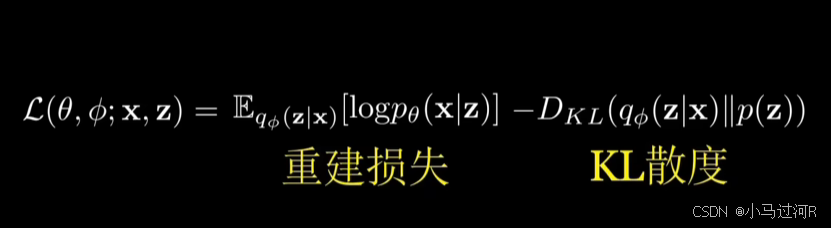
损失函数
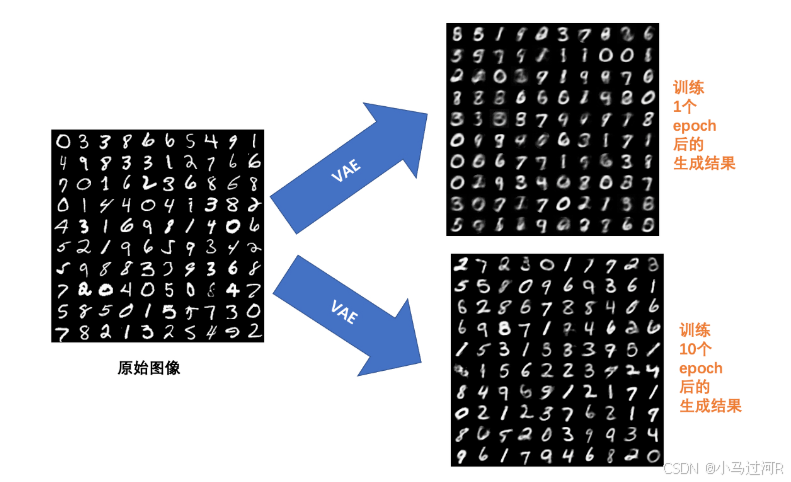
总结
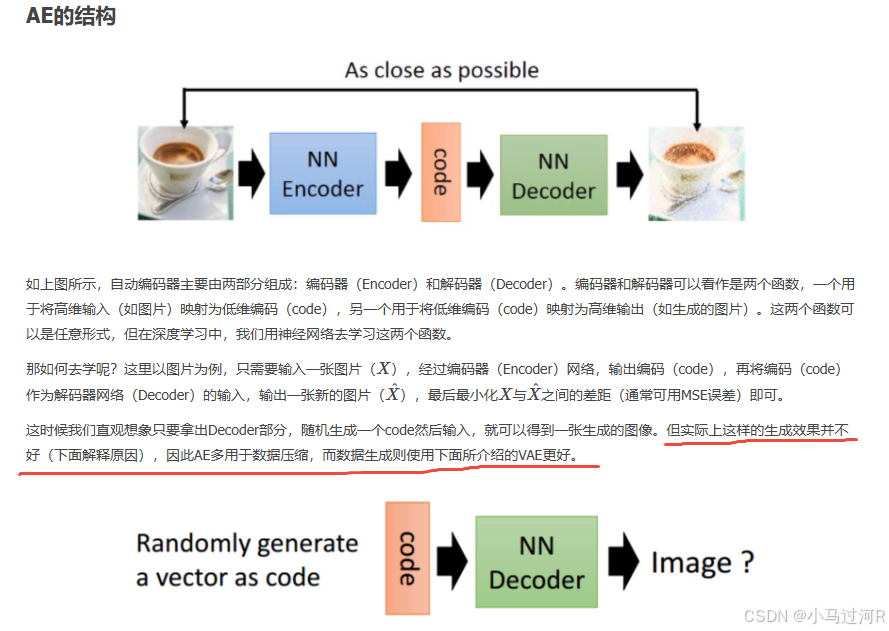
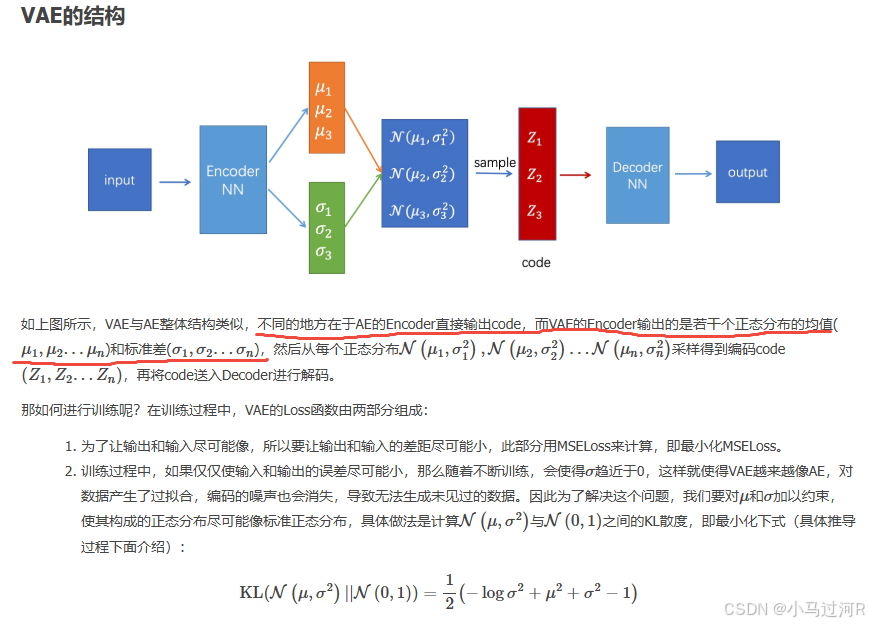
AE主要用于数据的压缩与还原,在生成数据上使用VAE(如上图);
AE是将数据映直接映射为数值code,而VAE是先将数据映射为分布,再从分布中采样得到数值code;
VAE的缺点是生成的数据不一定那么“真”,如果要使生成的数据“真”,则要用到GAN。
从原理来看,VAE之所以模糊,是因为VAE 通常被设计为生成具有相似分布的新图像,而不是生成与原始数据完全相同的重构图像。生成的数据不够真实的主要原因包括以下几点:
1.信息损失:VAE通过将数据压缩到低维的潜在空间,再从潜在空间重构回原始空间,这一过程中会丢失一些细节信息。由于潜在空间是低维的,它很难完美地重建高维空间中的所有细节,尤其是那些复杂的纹理和细节,如头发、皮肤质感等。
2.模型设计:VAE的核心思想是通过潜在变量来建模数据的分布,这导致它生成的图像往往比较平滑,缺乏细节和纹理。VAE的生成过程是通过潜在变量的均值和方差来决定的,这限制了其生成具有复杂细节图像的能力。
3.重构误差:在Fourier空间中,重建误差主要由低频误差主导,因为自然图像的高频信息比低频信息少。这使得VAE在重建图像时更倾向于保留低频信息,从而忽略了高频细节。
4.感知损失和对抗损失的应用不足:VAE通常只使用重构损失来训练,这导致生成的图像在视觉上不够真实。相比之下,GAN(Generative Adversarial Networks)通过对抗训练可以生成更真实的图像,因为它直接优化生成图像与真实图像之间的差异。
三、VAE与GAN两者的关系
VAE(Variational Autoencoder,变分自编码器)和GAN(Generative Adversarial Network,生成对抗网络)都是生成模型,用于生成与训练数据分布相似的新数据,但它们在原理、架构和应用上有显著区别,同时也有一些联系。
GAN是什么:
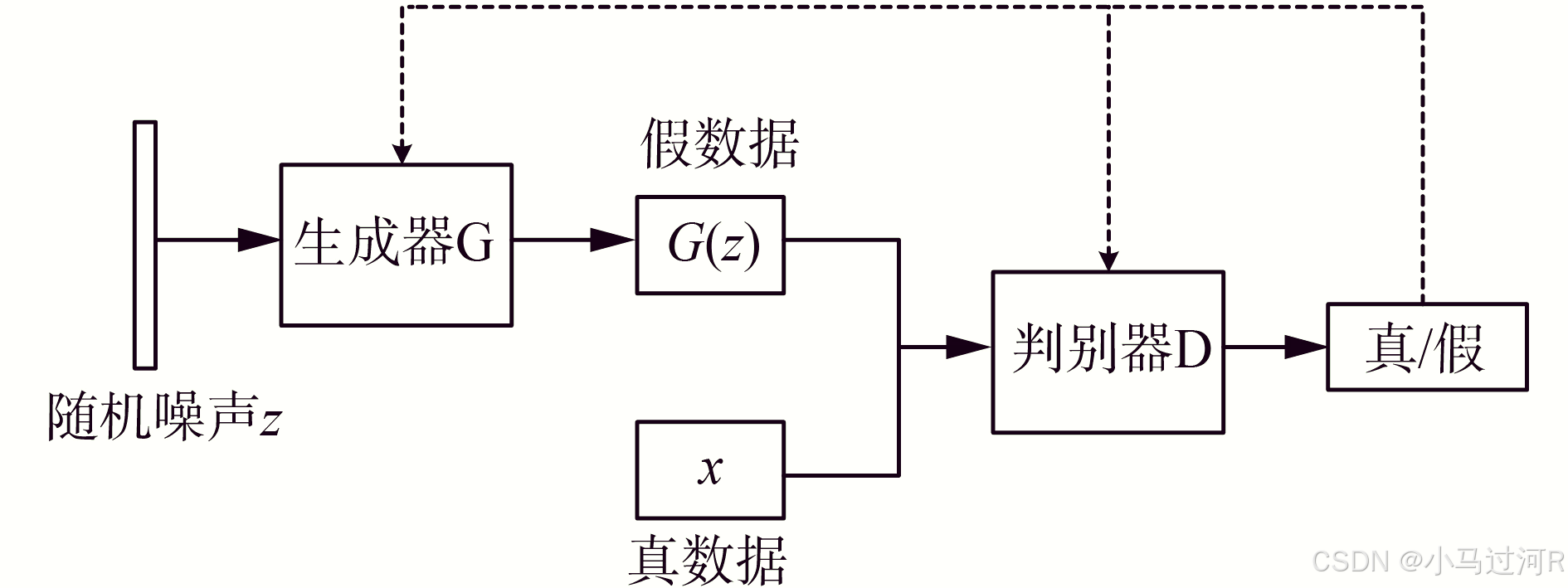
GAN原理文字描述通俗解释可以参看这里《一文搞懂深度学习》的“对抗生成网络(GAN)”目录。
VAE与GAN的区别
1. 核心原理
VAE:
基于变分推断(Variational Inference),通过优化数据分布的似然函数来学习潜在表示。
目标是学习数据的潜在空间,并通过解码器从潜在空间生成数据。
训练过程中最小化重构误差(Reconstruction Loss) 和 KL散度(KL Divergence)。
GAN:
基于博弈论,通过生成器(Generator)和判别器(Discriminator)的对抗训练来生成数据。
生成器试图生成逼真的数据,判别器试图区分生成数据和真实数据。
目标是使生成数据分布与真实数据分布尽可能接近。
2. 架构
VAE:
由编码器和解码器组成。
编码器将输入数据映射到潜在空间,解码器从潜在空间生成数据。
潜在空间通常是连续的,适合插值和生成平滑变化的数据。
GAN:
由生成器和判别器组成。
生成器从随机噪声生成数据,判别器评估生成数据的真实性。
没有显式的潜在空间,但生成器隐含地学习数据的分布。
3. 训练方式
VAE:
通过最大化证据下界(ELBO)进行训练,同时优化重构误差和KL散度。
训练过程稳定,但生成的数据可能模糊(由于重构误差的限制)。
GAN:
通过生成器和判别器的对抗训练进行优化。
训练过程不稳定,容易出现模式崩溃(Mode Collapse)或训练困难,但生成的数据通常更清晰。
4. 生成质量
VAE:
生成的数据通常较为平滑,但可能模糊(尤其在图像生成任务中)。
适合需要连续性和插值的任务。
GAN:
生成的数据通常更清晰、逼真,但可能出现模式崩溃或不稳定。
适合高分辨率图像生成和复杂数据分布建模。
5. 应用场景
VAE:
数据重建、特征提取、插值生成、无监督学习。
例如:图像生成、风格迁移、数据增强。
GAN:
高质量图像生成、超分辨率、图像修复、风格转换。
例如:DeepFake、艺术生成、图像编辑。
在图像处理中,插值(Interpolation)就是如何在缩放图片时,生成新的像素点,让图片看起来更自然、更清晰。
VAE与GAN的联系
生成模型:
两者都是生成模型,旨在从训练数据中学习分布并生成新的数据样本。
潜在空间:
VAE显式地学习潜在空间,而GAN的生成器隐含地学习潜在空间。
一些GAN变体(如VAE-GAN)结合了VAE的潜在空间和GAN的对抗训练。
结合使用:
VAE和GAN可以结合使用,例如VAE-GAN,利用VAE学习潜在空间,同时使用GAN提升生成质量。
应用领域:
两者都广泛应用于图像生成、数据增强、风格迁移等领域。
总结
VAE:基于变分推断,训练稳定,生成数据平滑但可能模糊,适合连续性和插值任务。
GAN:基于对抗训练,生成数据清晰逼真,但训练不稳定,适合高质量生成任务。
联系:两者都是生成模型,可以结合使用以互补优势。
选择VAE还是GAN取决于具体任务需求:如果需要稳定性和连续性,VAE更合适;如果需要高质量生成,GAN是更好的选择。
四、AE和Transformer的关系
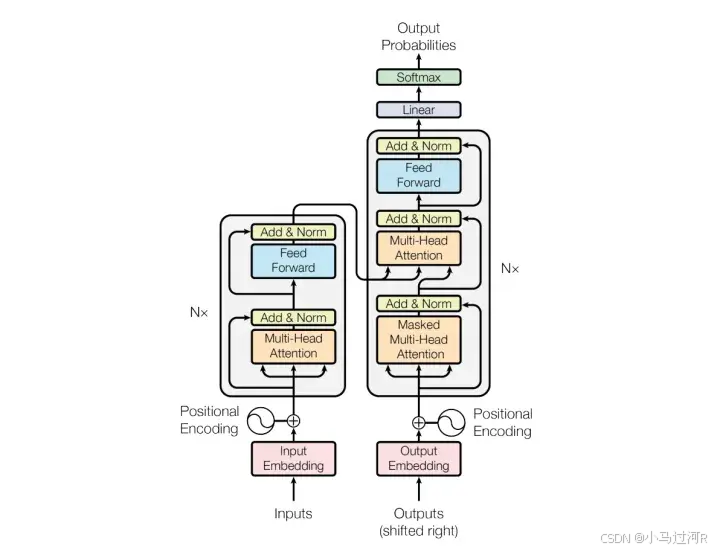
Transformer结构示意图⇧
Autoencoder(AE)和Transformer是深度学习中两种重要的架构,分别用于不同的任务,但它们在某些方面存在关联和结合点。以下是它们的关系和区别的总结:
核心功能与架构
Autoencoder (AE):
功能:主要用于无监督学习,通过编码器(Encoder)将输入数据压缩为低维潜在表示,再通过解码器(Decoder)重构原始数据。
架构:由对称的编码器和解码器组成,通常使用全连接层或卷积层。
Transformer:
功能:最初设计用于序列建模(如NLP),通过自注意力机制(Self-Attention)捕获长距离依赖关系。
架构:由编码器(Encoder)和解码器(Decoder)堆叠组成,但编码器和解码器的结构基于多头注意力机制和前馈网络。
联系与结合
共同点:
两者均包含编码器-解码器结构,但目标不同:AE专注于数据压缩与重建,Transformer专注于序列转换(如翻译)。
均可用于特征提取:AE学习数据的低维表示,Transformer通过注意力机制提取全局特征。
结合形式:
Transformer Autoencoder:将Transformer的编码器-解码器架构用于自编码任务,利用自注意力机制改进传统AE对长序列或复杂数据的建模能力。
应用场景:如Vision Transformer(ViT)与Masked Autoencoder(MAE)结合,用于图像生成或表示学习。
关键区别
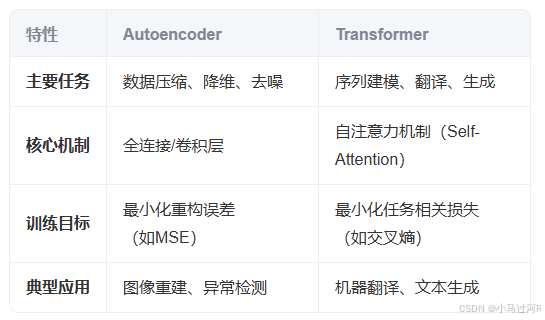
典型结合案例
Masked Autoencoder (MAE):基于Transformer架构,通过随机掩码输入数据(如图像块),训练模型重建缺失部分,结合了AE的重构能力和Transformer的全局建模优势。
Vision Transformer (ViT):将图像分块后输入Transformer编码器,部分工作引入解码器(类似AE)进行图像生成或分类。
总结
AE:擅长无监督特征学习,结构简单但局限于局部特征捕获。
Transformer:通过注意力机制处理全局依赖,但需大量数据训练。
结合方向:Transformer的注意力机制可增强AE对复杂数据的建模能力,尤其在图像和序列生成任务中。
相关文章:
AE(自动编码器)与VAE(变分自动编码器)简单理解
- 彩蛋没有也得硬生…




















 2345
2345

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











