






 该博客介绍了如何使用SparkSQL处理大数据场景下的分组TopN问题。首先,创建了一个Maven项目,添加了Scala和Spark的相关依赖。接着,通过Scala编写代码,读取HDFS上的学生成绩数据,将其转换为DataFrame,然后执行SQL查询,对每个学生取成绩最高的前三名。最后,展示了查询结果。
该博客介绍了如何使用SparkSQL处理大数据场景下的分组TopN问题。首先,创建了一个Maven项目,添加了Scala和Spark的相关依赖。接着,通过Scala编写代码,读取HDFS上的学生成绩数据,将其转换为DataFrame,然后执行SQL查询,对每个学生取成绩最高的前三名。最后,展示了查询结果。
分组求TopN是大数据领域常见的需求,主要是根据数据的某一列进行分组,然后将分组后的每一组数据按照指定的列进行排序,最后取每一组的前N行数据。
有一组学生成绩数据
张三 98
李四 87
王五 70
赵六 85
胡八一 68
张三 88
李四 79
王五 85
赵六 77
胡八一 70
张三 89
李四 90
王五 83
赵六 73
胡八一 93
张三 70
李四 75
王五 69
赵六 80
胡八一 79
- 启动集群的HDFS与Spark
- 设置项目的类型
二、完成项目
(一)新建Maven项目
增加scala目录
(二)添加相关依赖与构建插件
- 在pom.xml 添加依赖
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<groupId>net.cch.sql</groupId>
<artifactId>SparkSQL</artifactId>
<version>1.0-SNAPSHOT</version>
<properties>
<maven.compiler.source>8</maven.compiler.source>
<maven.compiler.target>8</maven.compiler.target>
</properties>
<dependencies>
<dependency>
<groupId>org.scala-lang</groupId>
<artifactId>scala-library</artifactId>
<version>2.11.12</version>
</dependency>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-core_2.11</artifactId>
<version>2.1.1</version>
</dependency>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-sql_2.11</artifactId>
<version>2.1.1</version>
</dependency>
</dependencies>
<build>
<sourceDirectory>src/main/scala</sourceDirectory>
<plugins>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-assembly-plugin</artifactId>
<version>3.3.0</version>
<configuration>
<descriptorRefs>
<descriptorRef>jar-with-dependencies</descriptorRef>
</descriptorRefs>
</configuration>
<executions>
<execution>
<id>make-assembly</id>
<phase>package</phase>
<goals>
<goal>single</goal>
</goals>
</execution>
</executions>
</plugin>
<plugin>
<groupId>net.alchim31.maven</groupId>
<artifactId>scala-maven-plugin</artifactId>
<version>3.3.2</version>
<executions>
<execution>
<id>scala-compile-first</id>
<phase>process-resources</phase>
<goals>
<goal>add-source</goal>
<goal>compile</goal>
</goals>
</execution>
<execution>
<id>scala-test-compile</id>
<phase>process-test-resources</phase>
<goals>
<goal>testCompile</goal>
</goals>
</execution>
</executions>
</plugin>
</plugins>
</build>
</project>
 (三)创建日志属性文件
(三)创建日志属性文件
添加log4j.properties日志文件
log4j.rootLogger=ERROR, stdout, logfile
log4j.appender.stdout=org.apache.log4j.ConsoleAppender
log4j.appender.stdout.layout=org.apache.log4j.PatternLayout
log4j.appender.stdout.layout.ConversionPattern=%d %p [%c] - %m%n
log4j.appender.logfile=org.apache.log4j.FileAppender
log4j.appender.logfile.File=target/spark.log
log4j.appender.logfile.layout=org.apache.log4j.PatternLayout
log4j.appender.logfile.layout.ConversionPattern=%d %p [%c] - %m%n2
-
(四)创建分组排行榜单例对象
- 创建GradeTopNSQL单例对象
编写GradeTopNSQL代码
import org.apache.spark.sql.SparkSession
/**
* 功能: 利用Spark SQL 实现分组排行榜
* 作者: 蒋勤辉
* 时间: 2022年06月10日
*/
object GradeTopNBySQL {
def main(args: Array[String]): Unit = {
// 创建或得到Spark会话2对象
val spark = SparkSession.builder()
.appName("")
.master("local[*]")
.getOrCreate()
// 读取HDFS上的成绩文件
val lines = spark.read.textFile("hdfs://master:9000/input/grades.txt")
lines.show()
import spark.implicits._
// 将数据集中的数据按空格拆分并合并
val grades = lines.flatMap(_.split(" ")).show()
//创建成绩数据集
val gradeDS = lines.map(
line =>{
val fields = line.split(" ")
val name = fields(0)
val score = fields(1).toInt
Grade(name,score)
}
)
gradeDS.show()
// 将数据集转换数据帧
val df = gradeDS.toDF()
// 显示内容
df.show()
df.createOrReplaceTempView("t_grade")
// 查询临时表,得到分组排行
val top3 = spark.sql(
"""
|SELECT name,score FROM
| (SELECT name,score,row_number() OVER (PARTITION BY name ORDER BY score DESC) rank from t_grade) t
| WHERE t.rank <= 3
|""".stripMargin
)
top3.show()
}
case class Grade(name:String,score:Int)
}
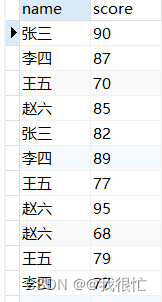
(五)本地运行程序,查看结果
- 在控制台输出来查看结果。

















 725
725

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









