




入门
依赖
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-sql_2.12</artifactId>
<version>3.0.1</version>
<scope>provided</scope>
</dependency>
<dependency>
<groupId>org.codehaus.janino</groupId>
<artifactId>janino</artifactId>
<version>3.0.8</version>
</dependency>编码
import org.apache.spark.api.java.function.FilterFunction;
import org.apache.spark.sql.Dataset;
import org.apache.spark.sql.SparkSession;
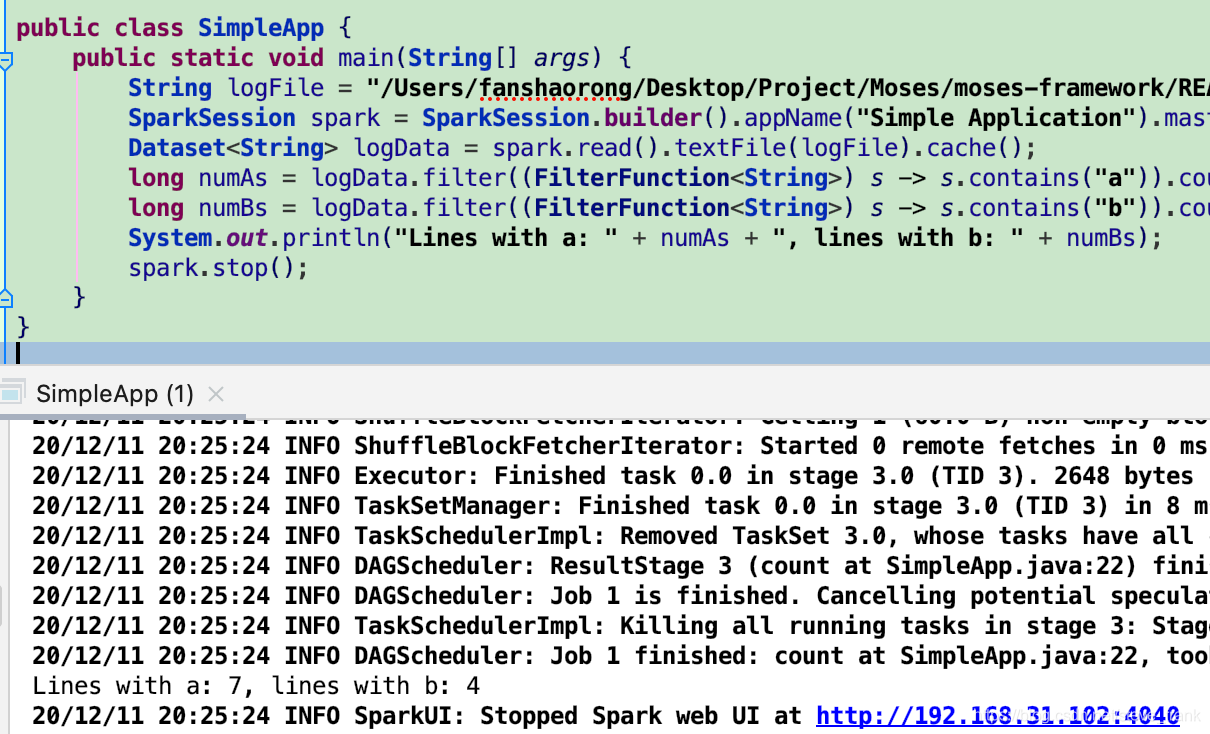
public class SimpleApp {
public static void main(String[] args) {
String logFile = "/Users/fanshaorong/Desktop/Project/Moses/moses-framework/README.md"; // Should be some file on your system
SparkSession spark = SparkSession.builder().appName("Simple Application").master("local").getOrCreate();
Dataset<String> logData = spark.read().textFile(logFile).cache();
long numAs = logData.filter((FilterFunction<String>) s -> s.contains("a")).count();
long numBs = logData.filter((FilterFunction<String>) s -> s.contains("b")).count();
System.out.println("Lines with a: " + numAs + ", lines with b: " + numBs);
spark.stop();
}
}查看
Spark RDDs
并行集合
import org.apache.spark.api.java.JavaRDD;
import org.apache.spark.api.java.JavaSparkContext;
import org.apache.spark.sql.SparkSession;
import java.util.ArrayList;
import java.util.List;
/**
* Computes an approximation to pi
* Usage: JavaSparkPi [partitions]
*/
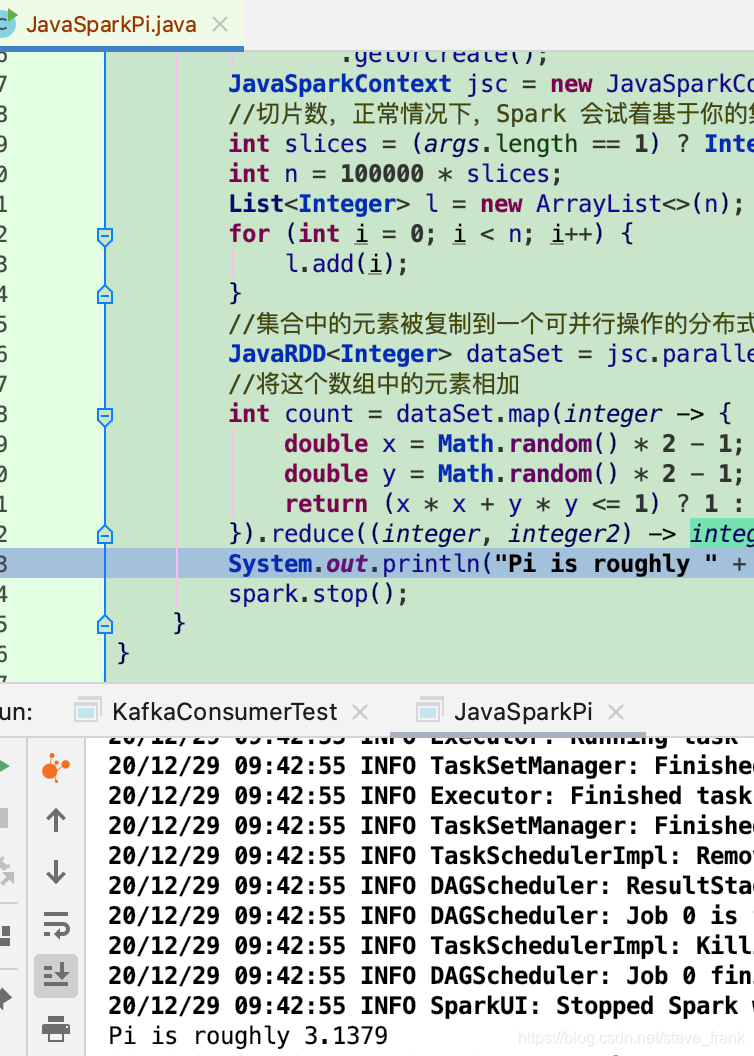
public final class JavaSparkPi {
public static void main(String[] args) throws Exception {
SparkSession spark = SparkSession
.builder()
.appName("JavaSparkPi")
.master("local")
.getOrCreate();
JavaSparkContext jsc = new JavaSparkContext(spark.sparkContext());
//切片数,正常情况下,Spark 会试着基于你的集群状况自动地设置切片的数目
int slices = (args.length == 1) ? Integer.parseInt(args[0]) : 2;
int n = 100000 * slices;
List<Integer> l = new ArrayList<>(n);
for (int i = 0; i < n; i++) {
l.add(i);
}
//集合中的元素被复制到一个可并行操作的分布式数据集中
JavaRDD<Integer> dataSet = jsc.parallelize(l, slices);
//将这个数组中的元素相加
int count = dataSet.map(integer -> {
double x = Math.random() * 2 - 1;
double y = Math.random() * 2 - 1;
return (x * x + y * y <= 1) ? 1 : 0;
}).reduce((integer, integer2) -> integer + integer2);
System.out.println("Pi is roughly " + 4.0 * count / n);
spark.stop();
}
}
RDD 操作
import org.apache.spark.api.java.JavaPairRDD;
import org.apache.spark.api.java.JavaRDD;
import org.apache.spark.sql.SparkSession;
import scala.Tuple2;
import java.util.Arrays;
import java.util.List;
import java.util.regex.Pattern;
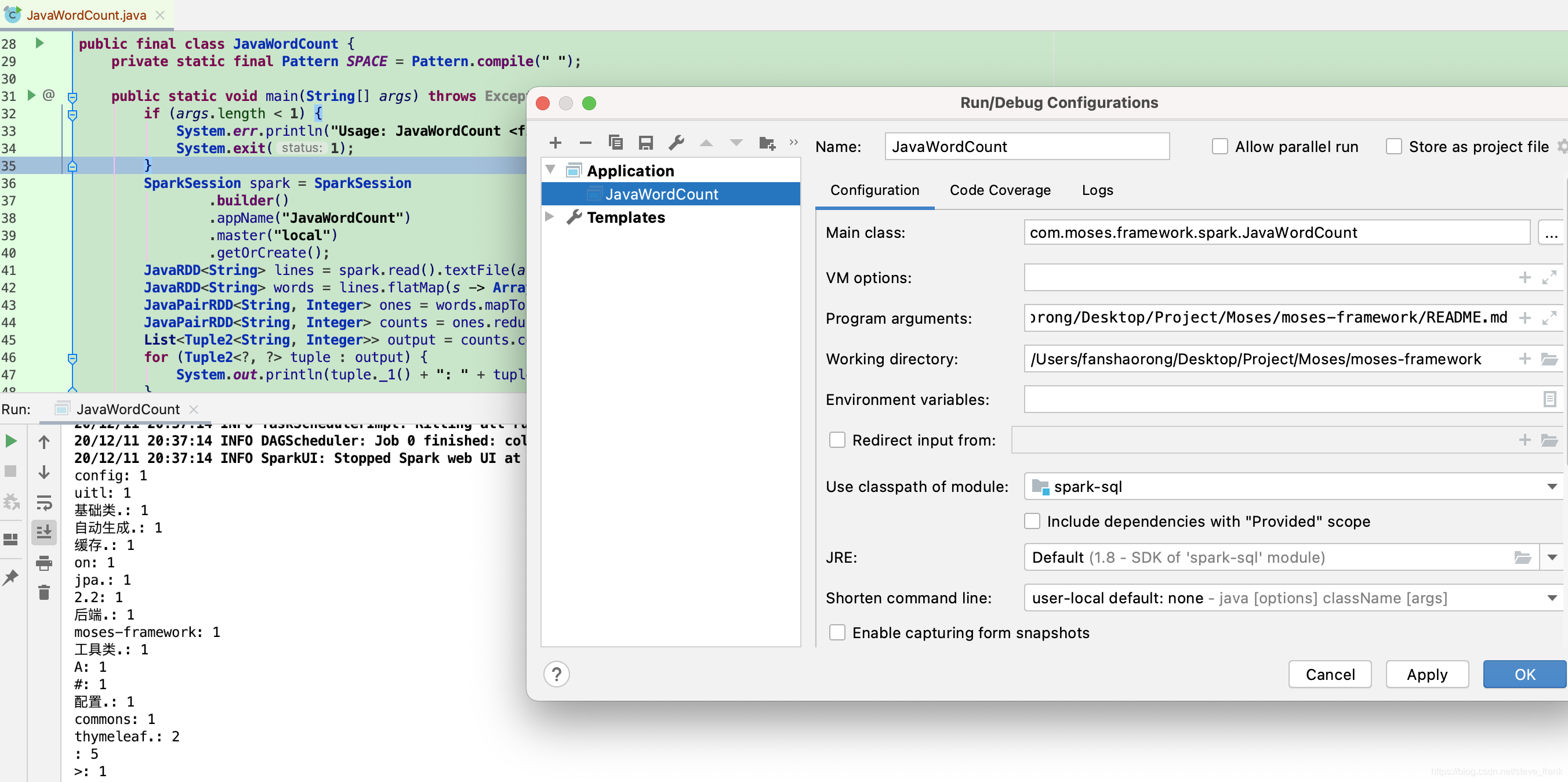
public final class JavaWordCount {
private static final Pattern SPACE = Pattern.compile(" ");
public static void main(String[] args) throws Exception {
if (args.length < 1) {
System.err.println("Usage: JavaWordCount <file>");
System.exit(1);
}
SparkSession spark = SparkSession
.builder()
.appName("JavaWordCount")
.master("local")
.getOrCreate();
JavaRDD<String> lines = spark.read().textFile(args[0]).javaRDD();
JavaRDD<String> words = lines.flatMap(s -> Arrays.asList(SPACE.split(s)).iterator());
JavaPairRDD<String, Integer> ones = words.mapToPair(s -> new Tuple2<>(s, 1));
JavaPairRDD<String, Integer> counts = ones.reduceByKey((i1, i2) -> i1 + i2);
List<Tuple2<String, Integer>> output = counts.collect();
for (Tuple2<?, ?> tuple : output) {
System.out.println(tuple._1() + ": " + tuple._2());
}
spark.stop();
}
}
Web框架
依赖
<dependency>
<groupId>com.sparkjava</groupId>
<artifactId>spark-core</artifactId>
<version>2.9.3</version>
</dependency>编码
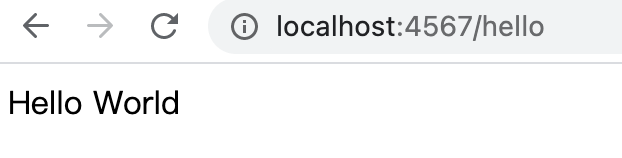
import static spark.Spark.get;
public class HelloWorld {
public static void main(String[] args) {
get("/hello", (req, res) -> "Hello World");
}
}
查看
视图和模版
使用Thymeleaf模板引擎渲染HTML
<dependency>
<groupId>com.sparkjava</groupId>
<artifactId>spark-template-thymeleaf</artifactId>
<version>2.7.1</version>
</dependency>编码
import spark.ModelAndView;
import spark.template.thymeleaf.ThymeleafTemplateEngine;
import java.util.HashMap;
import java.util.Map;
import static spark.Spark.get;
/**
* ThymeleafTemplateRoute example.
*/
public final class ThymeleafExample {
public static void main(final String[] args) {
get("/hello", (request, response) -> {
Map<String, Object> model = new HashMap<>();
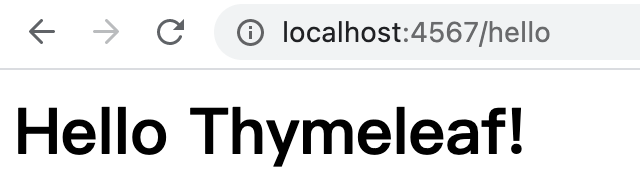
model.put("message", "Hello Thymeleaf!");
return new ModelAndView(model, "hello"); // located in resources/templates
}, new ThymeleafTemplateEngine());
}
}hello.html
<h1 th:text="${message}" xmlns:th="http://www.w3.org/1999/xhtml">Text inside tag will be replaced by ${message}</h1>
查看
Spark Streaming

Spark Streaming接收实时输入数据流,并将数据分成批次,然后由Spark引擎进行处理,以生成批次的最终结果流。

pom.xml
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-streaming_2.12</artifactId>
<version>3.0.1</version>
<scope>provided</scope>
</dependency>JavaQueueStream
import org.apache.spark.SparkConf;
import org.apache.spark.api.java.JavaRDD;
import org.apache.spark.streaming.Duration;
import org.apache.spark.streaming.api.java.JavaDStream;
import org.apache.spark.streaming.api.java.JavaPairDStream;
import org.apache.spark.streaming.api.java.JavaStreamingContext;
import scala.Tuple2;
import java.util.ArrayList;
import java.util.LinkedList;
import java.util.List;
import java.util.Queue;
public final class JavaQueueStream {
public static void main(String[] args) throws Exception {
// StreamingExamples.setStreamingLogLevels();
SparkConf sparkConf = new SparkConf().setMaster("local[2]").setAppName("JavaQueueStream");
// Create the context
JavaStreamingContext ssc = new JavaStreamingContext(sparkConf, new Duration(1000));
// Create the queue through which RDDs can be pushed to
// a QueueInputDStream
// Create and push some RDDs into the queue
List<Integer> list = new ArrayList<>();
for (int i = 0; i < 1000; i++) {
list.add(i);
}
Queue<JavaRDD<Integer>> rddQueue = new LinkedList<>();
for (int i = 0; i < 30; i++) {
rddQueue.add(ssc.sparkContext().parallelize(list));
}
// Create the QueueInputDStream and use it do some processing
JavaDStream<Integer> inputStream = ssc.queueStream(rddQueue);
JavaPairDStream<Integer, Integer> mappedStream = inputStream.mapToPair(
i -> new Tuple2<>(i % 10, 1));
JavaPairDStream<Integer, Integer> reducedStream = mappedStream.reduceByKey(
(i1, i2) -> i1 + i2);
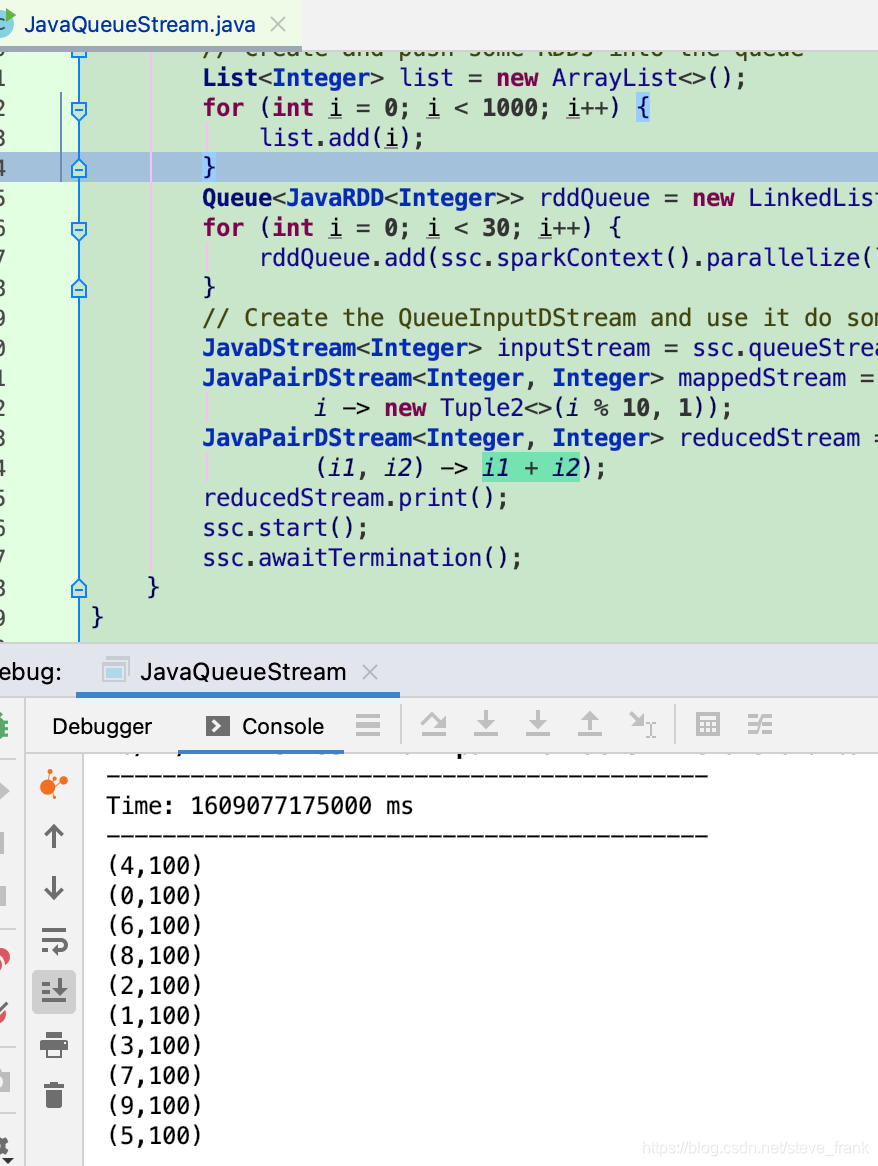
reducedStream.print();
ssc.start();
ssc.awaitTermination();
}
}
JavaNetworkWordCount
import org.apache.spark.SparkConf;
import org.apache.spark.streaming.Durations;
import org.apache.spark.streaming.api.java.JavaDStream;
import org.apache.spark.streaming.api.java.JavaPairDStream;
import org.apache.spark.streaming.api.java.JavaReceiverInputDStream;
import org.apache.spark.streaming.api.java.JavaStreamingContext;
import scala.Tuple2;
import java.util.Arrays;
import java.util.List;
import java.util.regex.Pattern;
/**
* Counts words in UTF8 encoded, '\n' delimited text received from the network every second.
* <p>
* Usage: JavaNetworkWordCount <hostname> <port>
* <hostname> and <port> describe the TCP server that Spark Streaming would connect to receive data.
* <p>
* To run this on your local machine, you need to first run a Netcat server
* `$ nc -lk 9999`
* and then run the example
* `$ bin/run-example org.apache.spark.examples.streaming.JavaNetworkWordCount localhost 9999`
*/
public final class JavaNetworkWordCount {
private static final Pattern SPACE = Pattern.compile(" ");
public static void main(String[] args) throws Exception {
// Create the context with a 1 second batch size
SparkConf conf = new SparkConf().setMaster("local[2]").setAppName("NetworkWordCount");
JavaStreamingContext jssc = new JavaStreamingContext(conf, Durations.seconds(10));
// Create a DStream that will connect to hostname:port, like localhost:9999
JavaReceiverInputDStream<String> lines = jssc.socketTextStream("localhost", 9999);
// Split each line into words
JavaDStream<String> words = lines.flatMap(x -> Arrays.asList(x.split(" ")).iterator());
// Count each word in each batch
JavaPairDStream<String, Integer> pairs = words.mapToPair(s -> new Tuple2<>(s, 1));
JavaPairDStream<String, Integer> wordCounts = pairs.reduceByKey((i1, i2) -> i1 + i2);
// Print the first ten elements of each RDD generated in this DStream to the console
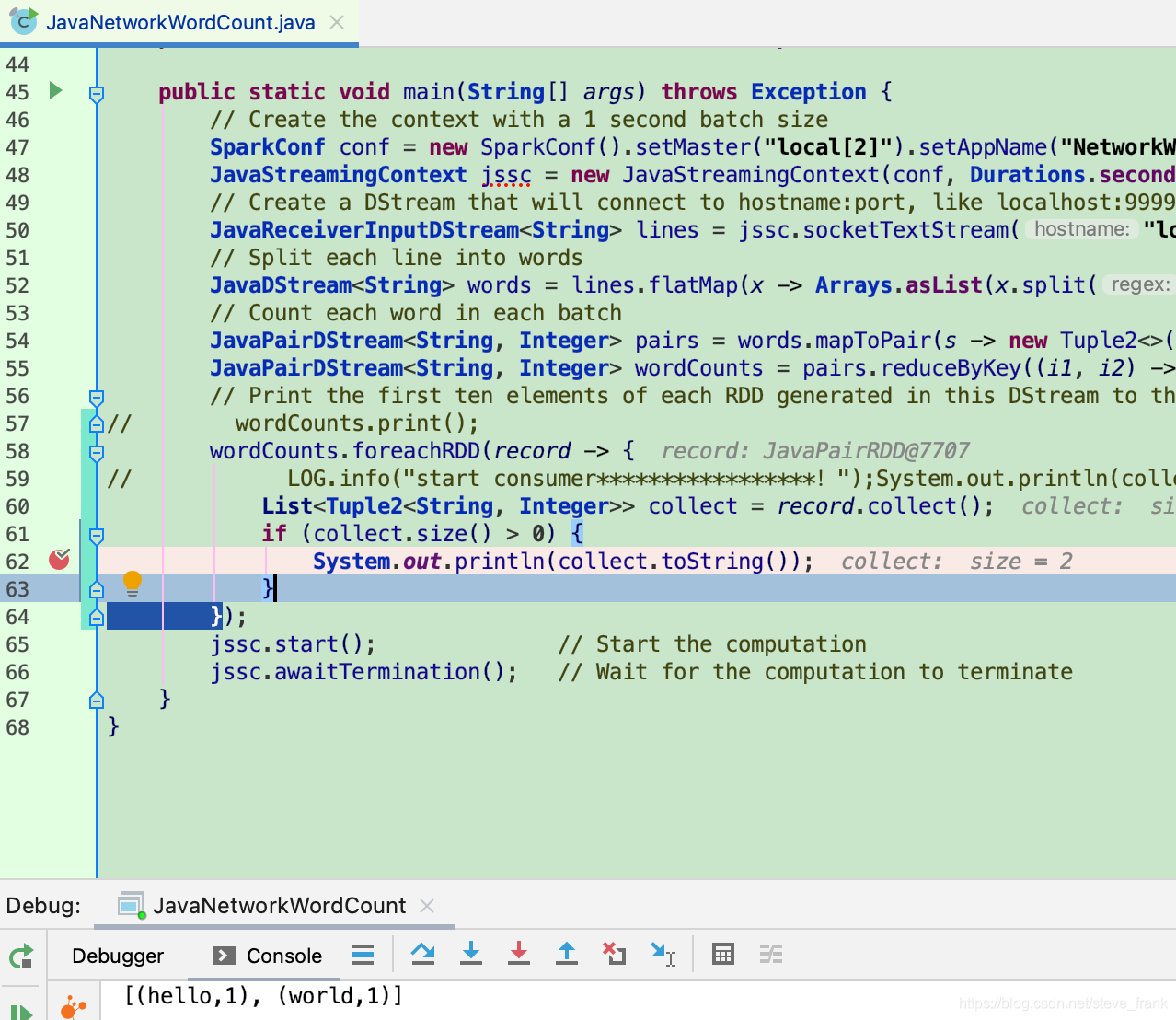
// wordCounts.print();
wordCounts.foreachRDD(record -> {
List<Tuple2<String, Integer>> collect = record.collect();
if (collect.size() > 0) {
System.out.println(collect.toString());
}
});
jssc.start(); // Start the computation
jssc.awaitTermination(); // Wait for the computation to terminate
}
}运行Netcat
nc -lk 9999
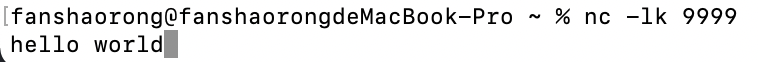
DStreams上的输出操作
| 输出操作 | 含义 |
|---|---|
| print() | 在运行流应用程序的驱动程序节点上,打印DStream中每批数据的前十个元素。这对于开发和调试很有用。 在Python API中称为 pprint()。 |
| saveAsTextFiles(prefix, [suffix]) | 将此DStream的内容另存为文本文件。基于产生在每批间隔的文件名的前缀和后缀:“前缀TIME_IN_MS [.suffix]”。 |
| saveAsObjectFiles(prefix, [suffix]) | 将此DStream的内容保存为SequenceFiles序列化Java对象的内容。基于产生在每批间隔的文件名的前缀和 后缀:“前缀TIME_IN_MS [.suffix]”。Python API中不可用。 |
| saveAsHadoopFiles(prefix, [suffix]) | 将此DStream的内容另存为Hadoop文件。基于产生在每批间隔的文件名的前缀和后缀:“前缀TIME_IN_MS [.suffix]”。 Python API中不可用。 |
| foreachRDD(func) | 最通用的输出运算符,将函数func应用于从流生成的每个RDD。此功能应将每个RDD中的数据推送到外部系统,例如将RDD保存到文件或通过网络将其写入数据库。请注意,函数func是在运行流应用程序的驱动程序进程中执行的,并且通常在其中具有RDD操作,这将强制计算流RDD。 |
Kafka集成
pom.xml
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-streaming-kafka-0-10_2.12</artifactId>
<version>3.0.1</version>
<scope>provided</scope>
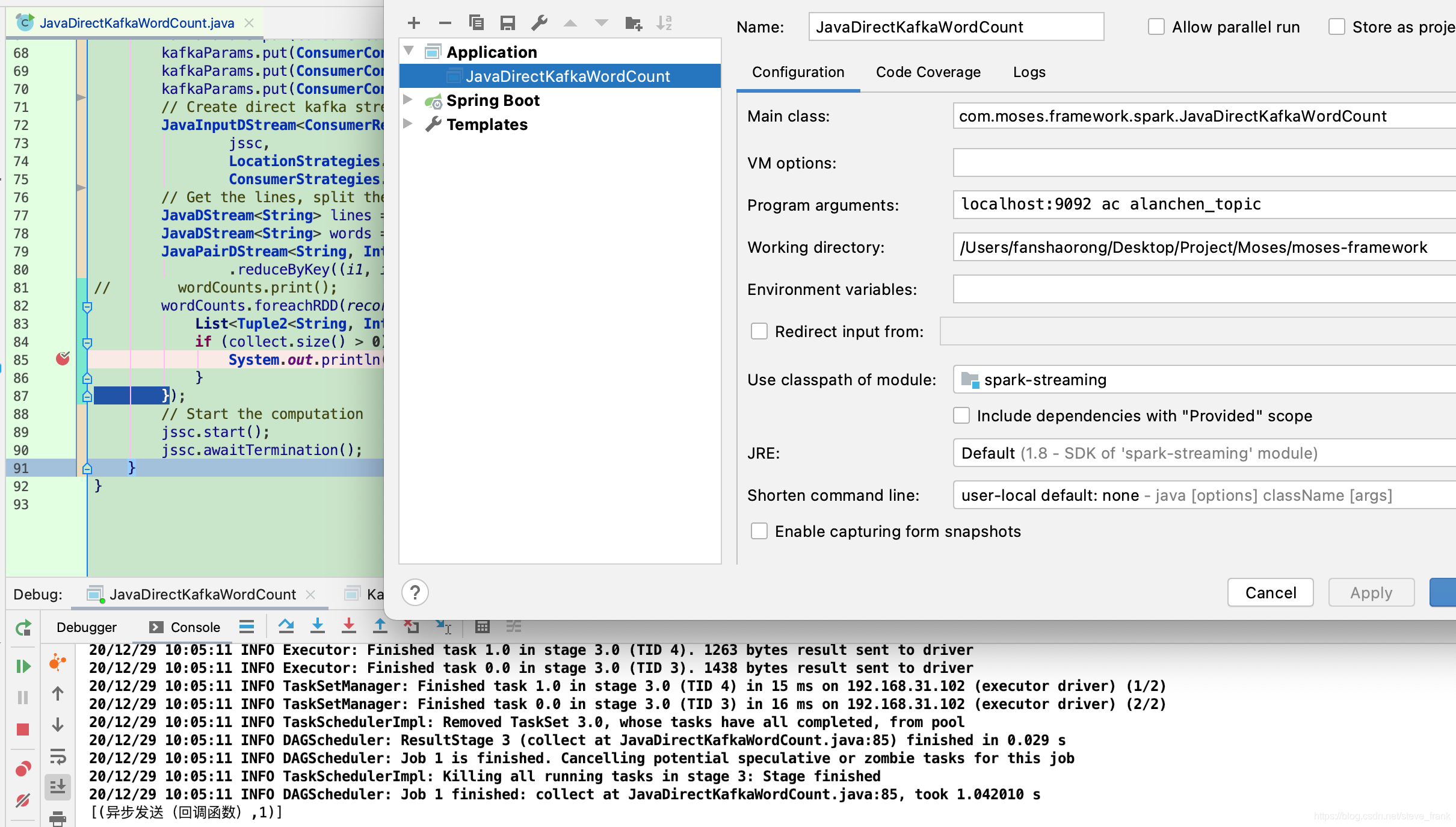
</dependency>JavaDirectKafkaWordCount
import org.apache.kafka.clients.consumer.ConsumerConfig;
import org.apache.kafka.clients.consumer.ConsumerRecord;
import org.apache.kafka.common.serialization.StringDeserializer;
import org.apache.spark.SparkConf;
import org.apache.spark.streaming.Durations;
import org.apache.spark.streaming.api.java.JavaDStream;
import org.apache.spark.streaming.api.java.JavaInputDStream;
import org.apache.spark.streaming.api.java.JavaPairDStream;
import org.apache.spark.streaming.api.java.JavaStreamingContext;
import org.apache.spark.streaming.kafka010.ConsumerStrategies;
import org.apache.spark.streaming.kafka010.KafkaUtils;
import org.apache.spark.streaming.kafka010.LocationStrategies;
import scala.Tuple2;
import java.util.*;
import java.util.regex.Pattern;
/**
* Consumes messages from one or more topics in Kafka and does wordcount.
* Usage: JavaDirectKafkaWordCount <brokers> <groupId> <topics>
* <brokers> is a list of one or more Kafka brokers
* <groupId> is a consumer group name to consume from topics
* <topics> is a list of one or more kafka topics to consume from
* <p>
* Example:
* $ bin/run-example streaming.JavaDirectKafkaWordCount broker1-host:port,broker2-host:port \
* consumer-group topic1,topic2
*/
public final class JavaDirectKafkaWordCount {
private static final Pattern SPACE = Pattern.compile(" ");
public static void main(String[] args) throws Exception {
if (args.length < 3) {
System.err.println("Usage: JavaDirectKafkaWordCount <brokers> <groupId> <topics>\n" +
" <brokers> is a list of one or more Kafka brokers\n" +
" <groupId> is a consumer group name to consume from topics\n" +
" <topics> is a list of one or more kafka topics to consume from\n\n");
System.exit(1);
}
// StreamingExamples.setStreamingLogLevels();
String brokers = args[0];
String groupId = args[1];
String topics = args[2];
// Create context with a 2 seconds batch interval
SparkConf sparkConf = new SparkConf().setMaster("local[2]").setAppName("JavaDirectKafkaWordCount");
JavaStreamingContext jssc = new JavaStreamingContext(sparkConf, Durations.seconds(2));
Set<String> topicsSet = new HashSet<>(Arrays.asList(topics.split(",")));
Map<String, Object> kafkaParams = new HashMap<>();
kafkaParams.put(ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG, brokers);
kafkaParams.put(ConsumerConfig.GROUP_ID_CONFIG, groupId);
kafkaParams.put(ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class);
kafkaParams.put(ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class);
// Create direct kafka stream with brokers and topics
JavaInputDStream<ConsumerRecord<String, String>> messages = KafkaUtils.createDirectStream(
jssc,
LocationStrategies.PreferConsistent(),
ConsumerStrategies.Subscribe(topicsSet, kafkaParams));
// Get the lines, split them into words, count the words and print
JavaDStream<String> lines = messages.map(ConsumerRecord::value);
JavaDStream<String> words = lines.flatMap(x -> Arrays.asList(SPACE.split(x)).iterator());
JavaPairDStream<String, Integer> wordCounts = words.mapToPair(s -> new Tuple2<>(s, 1))
.reduceByKey((i1, i2) -> i1 + i2);
// wordCounts.print();
wordCounts.foreachRDD(record -> {
List<Tuple2<String, Integer>> collect = record.collect();
if (collect.size() > 0) {
System.out.println(collect.toString());
}
});
// Start the computation
jssc.start();
jssc.awaitTermination();
}
}
ES集成
pom.xml
<properties>
<project.build.sourceEncoding>UTF-8</project.build.sourceEncoding>
<maven.compiler.source>1.8</maven.compiler.source>
<maven.compiler.target>1.8</maven.compiler.target>
<java.version>1.8</java.version>
<spark.version>2.3.0</spark.version>
<elasticsearch.version>7.9.0</elasticsearch.version>
</properties>
<dependencies>
<!-- spark start -->
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-core_2.11</artifactId>
<version>${spark.version}</version>
</dependency>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-streaming_2.11</artifactId>
<version>${spark.version}</version>
</dependency>
<dependency>
<groupId>org.elasticsearch</groupId>
<artifactId>elasticsearch-spark-20_2.11</artifactId>
<version>${elasticsearch.version}</version>
</dependency>
</dependencies>EsSparkTest
import com.google.common.collect.ImmutableList;
import com.google.common.collect.ImmutableMap;
import org.apache.spark.SparkConf;
import org.apache.spark.api.java.JavaRDD;
import org.apache.spark.api.java.JavaSparkContext;
import org.apache.spark.sql.SparkSession;
import org.elasticsearch.spark.rdd.api.java.JavaEsSpark;
import java.util.Map;
/**
* @author Moses
* @date 2020/12/29
*/
public class EsSparkTest {
String ELASTIC_SEARCH_IP = "192.168.31.102:9200";
public void writeEs() {
String elasticIndex = "spark/docs";
//https://www.elastic.co/guide/en/elasticsearch/hadoop/current/spark.html#spark-native
SparkConf sparkConf = new SparkConf().setAppName("writeEs").setMaster("local[*]").set("es.index.auto.create", "true")
.set("es.nodes", ELASTIC_SEARCH_IP).set("es.port", "9200").set("es.nodes.wan.only", "true");
SparkSession sparkSession = SparkSession.builder().config(sparkConf).getOrCreate();
JavaSparkContext jsc = new JavaSparkContext(sparkSession.sparkContext());//adapter
Map<String, ?> numbers = ImmutableMap.of("one", 1, "two", 2);
Map<String, ?> airports = ImmutableMap.of("OTP", "Otopeni", "SFO", "San Fran");
JavaRDD<Map<String, ?>> javaRDD = jsc.parallelize(ImmutableList.of(numbers, airports));
JavaEsSpark.saveToEs(javaRDD, elasticIndex);
}
public void readEs() {
SparkConf sparkConf = new SparkConf().setAppName("writeEs").setMaster("local[*]").set("es.index.auto.create", "true")
.set("es.nodes", ELASTIC_SEARCH_IP).set("es.port", "9200").set("es.nodes.wan.only", "true")
.set("es.index.read.missing.as.empty", "yes");
SparkSession sparkSession = SparkSession.builder().config(sparkConf).getOrCreate();
JavaSparkContext jsc = new JavaSparkContext(sparkSession.sparkContext());//adapter
JavaRDD<Map<String, Object>> searchRdd = JavaEsSpark.esRDD(jsc, "spark/docs", "?q=Otopeni").values();
for (Map<String, Object> item : searchRdd.collect()) {
item.forEach((key, value) -> {
System.out.println("search key:" + key + ", search value:" + value);
});
}
sparkSession.stop();
}
public static void main(String[] args) {
new EsSparkTest().writeEs();
// new EsSparkTest().readEs();
}
}写ES
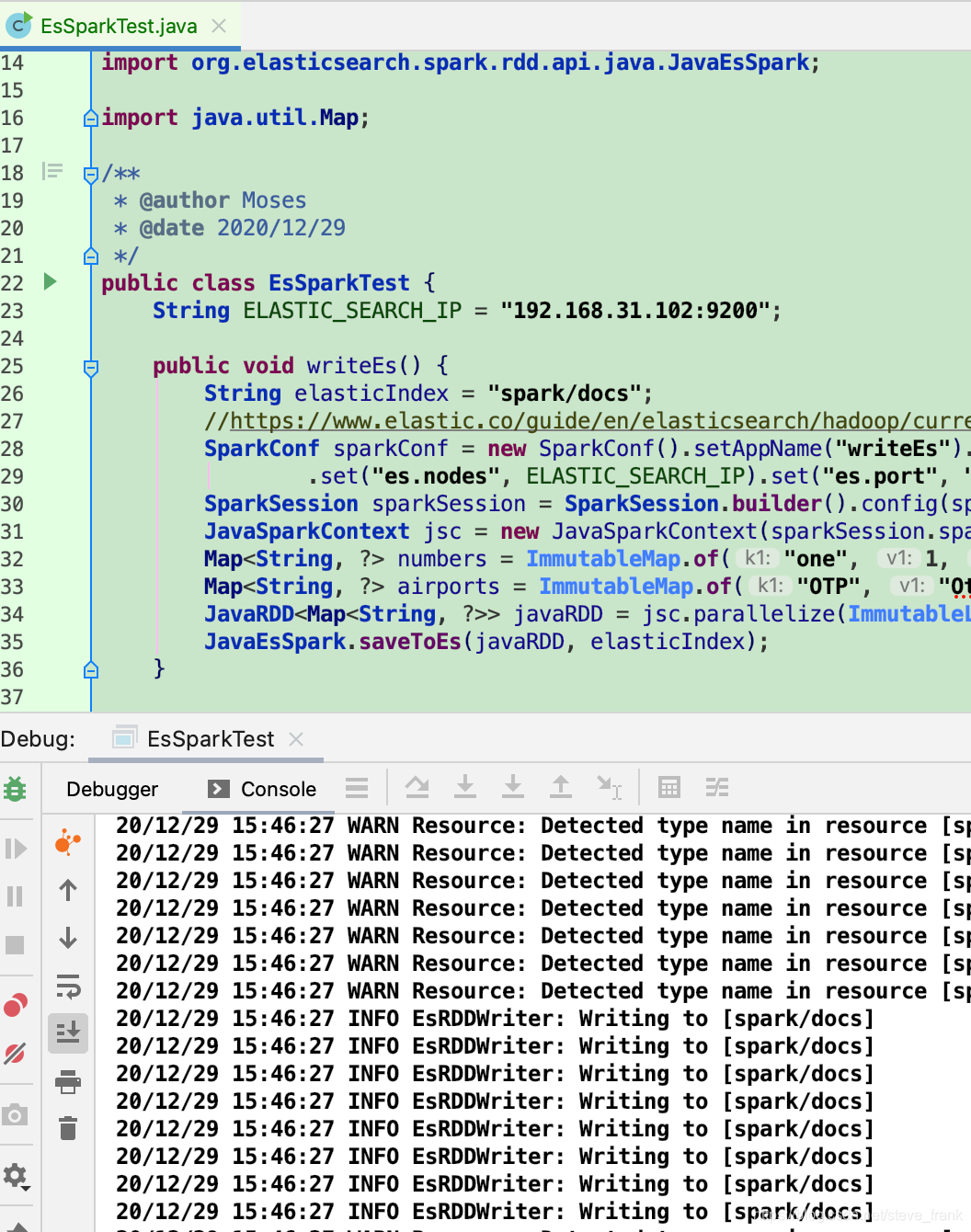
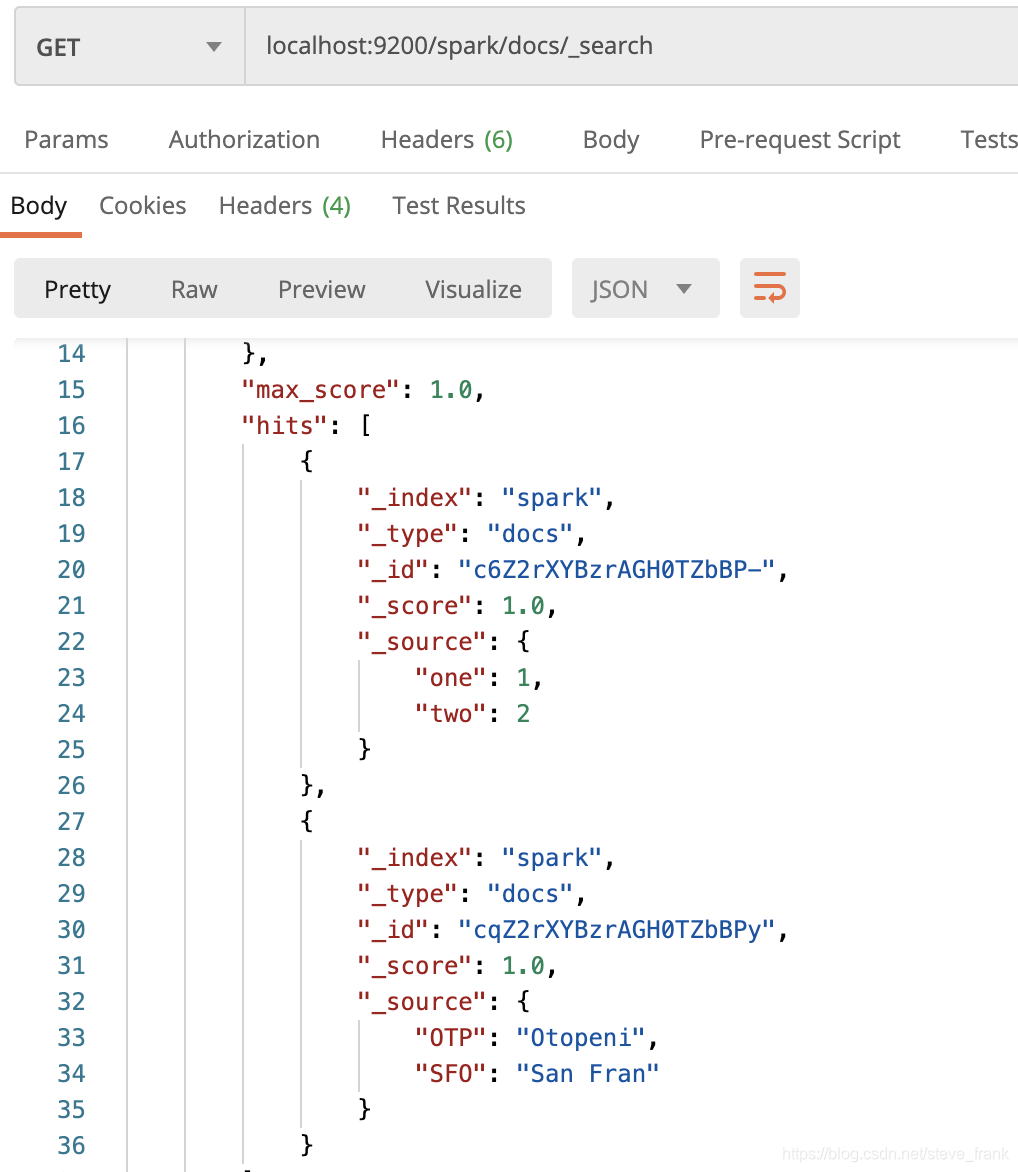
读ES
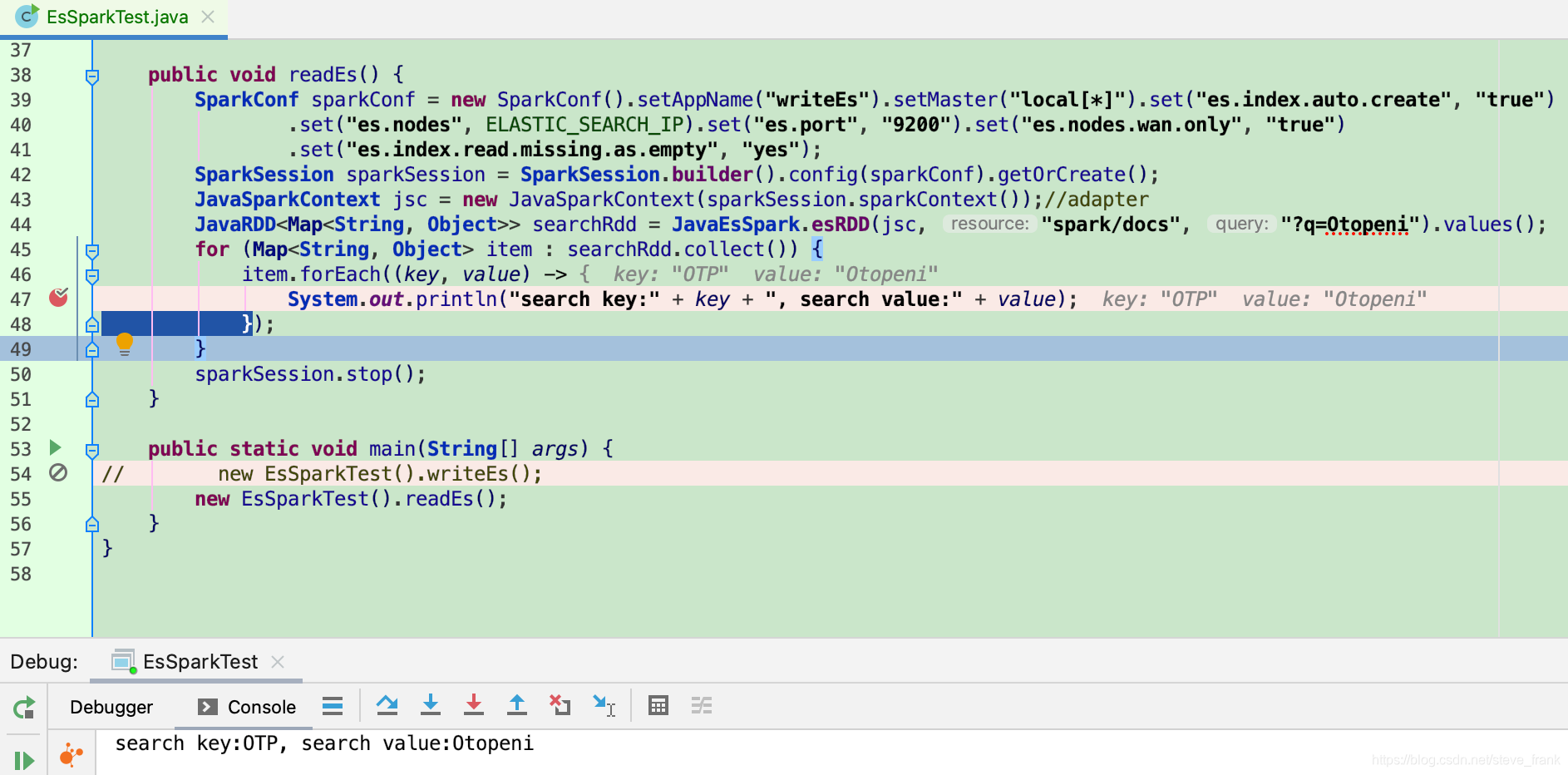

















 492
492

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









