



目录
相关论文阅读
基于视觉的机械臂控制算法,利用深度强化学习实现自主物体抓取
Vision-Based Robotic Arm Control Algorithm Using Deep Reinforcement Learning for Autonomous Objects Grasping
2021
本研究通过一个五自由度机械臂实现了该方法,该机械臂使用逆运动学方法到达目标物体。采用“You Only Look Once v5”算法进行物体检测,并使用反向投影法检测目标的三维位置。通过逆运动学计算出检测位置处的关节角度后,机器人手臂根据算法向目标物体的位置移动。我们的方法提供了一种神经逆运动学解决方案,可提高整体性能,其仿真结果也揭示了其相较于传统方法的优势。机器人末端抓取关节可以通过计算每个关节的角度,在可接受的误差范围内到达目标位置。同时,角度和姿态的精度也令人满意。
本文的主要贡献可以概括如下:
我们建议在检测物体后使用 YOLOv5 来获得更精确的物体位置;
我们使用向后投影来提取物体的3D位置;
我们应用 IK 来计算检测位置处的关节角度;
我们采用 DDPG 算法来教手臂自主到达想要的物体;
我们的方法优于最先进的方法,仅经过 400 次迭代就达到了目标95.5 %准确性。
强化学习DDPG部分:
我们知道,为了获得奖励,代理必须与环境进行交互,因此网络的重要组成部分是奖励函数 R。因此,构建一个完美的奖励函数至关重要。该函数应该能够正确响应机器人手臂的动作,以确保其参数能够有效解决机器人手臂的逆运动学问题。
为了到达目标物体,行动者网络将每个关节的 3D 位置以及关节与物体之间的距离作为输入,并输出关节角度。然后,评估者网络将根据找到的关节角度计算出的末端执行器 3D 位置,以及通过反向投影确定物体位置和末端执行器之间距离的物体 3D 位置作为输入,对最后一个行动者进行评估。距离越小,奖励越显著。因此,奖励函数表示如下:

机器学习在空间机器人抓取控制中的应用综述
Review of machine learning in robotic grasping control in space application
2024
表2 卷积神经网络在机器人抓取中用于物体定位的应用情况。该表突出展示了运用卷积神经网络进行物体精确定位的关键研究成果,而物体精确定位是实现高效机器人抓取的基础步骤。
| 研究 | 年份 | 主要聚焦 | 关键发现/贡献 | 涵盖的方法 |
|---|---|---|---|---|
| Rais等人[45] | 2023年 | 用于物体定位的卷积神经网络级联 | 提出一种新颖的方法,使用卷积神经网络(YOLOv5和EfficientNet)级联进行物体检测和旋转角度分类,实现了高精度和召回率。 | YOLOv5、EfficientNet、图像处理技术 |
| Farag等人[46] | 2019年 | 实时抓取与定位 | 使用基于Alexnet框架开发的卷积神经网络KSSnet模型,在物体检测和实时抓取方面展示了100%的精度,用于机器人抓取和放置操作。 | 深度卷积神经网络(KSSnet)、边缘检测、相机校准技术 |
| Jia等人[47] | 2018年 | 用于抓取的统一深度卷积神经网络 | 提出一种网络框架,可同时进行分类、定位和抓取检测,展示了在机器人机械臂上有效的实时抓取能力。 | 带有多任务损失的深度卷积神经网络、区域提议技术 |
| Trottier等人[48] | 2017年 | 基于残差网络的抓取定位 | 利用残差网络进行抓取定位,通过架构修改解决了去除空间相关性的挑战,达到了最先进的性能。 | 卷积残差网络、在线数据增强 |
表8 强化学习在物体定位方面的进展:增强机器人交互与效率。该表概述了强化学习在提升机器人物体定位能力应用中的关键进展,展示了强化学习方法如何在复杂环境中推进机器人的感知和交互能力。
| 研究 | 年份 | 主要关注点 | 关键发现/贡献 | 涵盖方法 |
|---|---|---|---|---|
| Chen等人[105] | 2023年 | 基于深度强化学习的机器人抓取 | 提出一种自学习方法,将用于物体检测的YOLO与用于机器人操纵器控制的软演员 - 评论家(SAC)算法相结合。利用仿真到现实的技术,成功实现对未知物体的抓取。 | YOLO、软演员 - 评论家算法、仿真到现实转换 |
| Pankert和Hutter[107] | 2023年 | 基于接触的状态估计 | 提出一种基于强化学习的探索策略,用于装配任务中的精确状态估计,在物体定位方面实现了高精度。 | 强化学习、状态估计 |
| Azulay等人[108] | 2022年 | 基于触觉的物体插入 | 探索了使用柔顺手进行触觉扫视以实现物体插入,提出一种在不确定性下进行精确控制的强化学习策略,并通过精确插入任务进行了验证。 | 触觉反馈、深度残差强化学习 |
| Kerzel和Wermter[106] | 2017年 | 自学习视觉运动技能 | 开发了一种端到端的深度卷积架构,通过与环境交互学习视觉运动技能,强调了物体抓取的快速自学习能力。 | 监督式端到端学习、深度卷积网络 |
| Weber等人[109] | 2003年 | 基于神经视觉的机器人对接 | 提出一种基于神经网络的机器人对接解决方案,将物体识别与强化学习相结合,以实现接近和抓取任务的高精度操作。 | 神经网络、强化学习 |
机器人抓取领域中,迁移学习的最新进展对拓展空间机器人技术的可实现边界起到了重要作用。表11至表13概括了这些进展,突出了在抓取的各个方面所取得的关键成果,包括目标定位、姿态估计和直接抓取检测。
| 研究 | 年份 | 主要关注点 | 关键发现/贡献 | 涵盖的方法 |
|---|---|---|---|---|
| Lu等人[124] | 2022年 | 用于姿态估计的关键点优化 | 提出一种用于机器人操纵器稳健视觉检测和定位的关键点优化方法。利用合成数据进行深度神经网络(DNN)训练,并通过域随机化实现仿真到现实的转换,显著提高了检测性能,并在各种机器人任务中得到应用。 | 关键点检测、仿真到现实转换、域随机化 |
| Fu等人[125] | 2019年 | 基于主动学习的抓取 | 开发了一种基于主动学习的抓取方法,将主动感知和操作集成用于工业应用。在无需相机参数先验知识和手动特征设计的情况下,实现了物体的高精度定位和操作,展示了在极少人工干预下适应新任务的能力。 | 主动学习、卷积神经网络(CNN)、交互式感知 |
| Sui等人[126] | 2019年 | 机器人感知模块的迁移 | 引入基于域对抗神经网络(DANN)和生成对抗网络(GAN)的两种方法,用于将机器人感知模块从模拟数据迁移到真实世界数据。展示了在实际应用中有效的域适应能力,且性能下降极小,强调了生成合成样本用于训练的重要性。 | 域对抗神经网络、生成对抗网络、域适应 |
| Farag等人[46] | 2019年 | 实时机器人抓取与定位 | 利用基于深度学习的物体检测技术KSSnet进行实时物体定位和机器人抓取。在物体检测和抓取精度上达到了100%的准确率,证明了结合CNN和边缘检测进行精确定位的有效性。 | 深度卷积神经网络(KSSnet)、边缘检测、选择性柔顺装配机器人手臂(SCARA Robot) |
| Wu等人[127] | 2018年 | 用于物体检测的RGB - D传感器 | 提出一种利用RGB - D信息融合进行物体检测的方法,以促进软机器人操作。利用ORB - SLAM2进行环境扫描,ICP进行物体定位,并结合Inception - v3和迁移学习进行识别。 | RGB - D融合、物体检测、Inception - v3 |
Gazebo:Gazebo 是一款功能强大、应用广泛的开源机器人模拟器,提供先进的模拟功能和丰富的特性。它支持在 3D 环境中模拟复杂的机器人系统,并具备逼真的物理、光照和纹理。Gazebo 尤其适用于在各种条件下测试机器人的抓取机制,能够集成传感器数据并操控虚拟对象。研究人员可以快速迭代设计和控制策略,并在各种模拟场景(包括模拟处理空间碎片或卫星维修)中观察结果。
MuJoCo: MuJoCo 是一款先进的物理引擎,它针对模拟涉及接触刚体动力学的复杂动态相互作用的速度和精度进行了优化。它因其处理高自由度机器人系统的能力以及高效、稳定的接触动力学模拟能力,在机器人和生物力学研究领域尤为受欢迎。这使得 MuJoCo 尤其适用于空间机器人,因为精确模拟机器人与各种物体之间的接触动力学对于机器人的成功运行至关重要。该引擎的 API 支持多种编程语言,便于将其集成到各种研究工作流程中。研究人员可以使用 MuJoCo 模拟机器人夹持器与不规则、可能移动的物体交互的行为,这是太空任务中常见的挑战。
V-REP (CoppeliaSim):V-REP(现为 CoppeliaSim)以其灵活性和可扩展性而闻名,是另一个全面的机器人仿真平台。它支持各种机器人、传感器和环境条件,有助于开发详细的机器人模型和控制算法,并支持使用 Lua 编写脚本。该平台能够模拟机器人的运动学和动力学特性,使其成为在实际应用之前测试和改进抓取技术的理想选择,包括模拟真空条件或太空应用中的极端温度条件。
ROS Gazebo 集成:机器人操作系统 (ROS) 与 Gazebo 的集成增强了模拟的真实感和实用性。ROS 提供了一个强大的机器人软件编写框架,并提供库和工具,帮助研究人员快速开发复杂可靠的机器人应用程序。与 Gazebo 结合使用时,ROS 可以在高度模拟真实物理和交互的环境中模拟机器人抓取动作,这对于在逼真且灵活的模拟环境中测试控制策略、传感器集成和操作算法至关重要。
PyBullet:PyBullet 是一个用于机器人、游戏和机器学习中物理模拟的 Python 模块,因其易用性和与基于 Python 的机器学习框架的集成而备受青睐。它提供精确的刚体模拟,并支持高级机器人功能,包括逆运动学和抓取力计算。PyBullet 特别适用于深度学习应用,允许快速原型设计和测试机器人抓取算法,并直接反馈性能指标。
Unity ML-Agents: Unity Technologies 的 ML-Agents 工具包支持在 Unity 游戏开发环境中训练和测试机器学习模型。该平台以其高质量的图形和物理模拟而闻名,为机器人抓取研究提供了视觉丰富且动态的场景。研究人员可以创建具有各种纹理、光照和对象属性的详细模拟场景,使其成为开发和改进基于视觉的抓取算法的强大工具。
基于视觉的机器人物体抓取——一种深度强化学习方法
Vision-Based Robotic Object Grasping—A Deep Reinforcement Learning Approach
2023.11
基于YOLO提供的检测/定位和分类结果,采用Soft Actor-Critic深度强化学习算法,为机器人操作器(即学习代理)提供理想的抓取姿态,以执行物体抓取。为了加快训练过程并降低训练数据收集成本,本文采用了Sim-to-Real技术,以降低训练过程中因操作不当而导致机器人操作器损坏的可能性。V-REP平台用于构建用于训练深度强化学习神经网络的仿真环境。已经进行了多次实验,实验结果表明,6 自由度工业机械手能够通过所提出的方法成功执行物体抓取,即使对于以前未见过的物体也是如此。

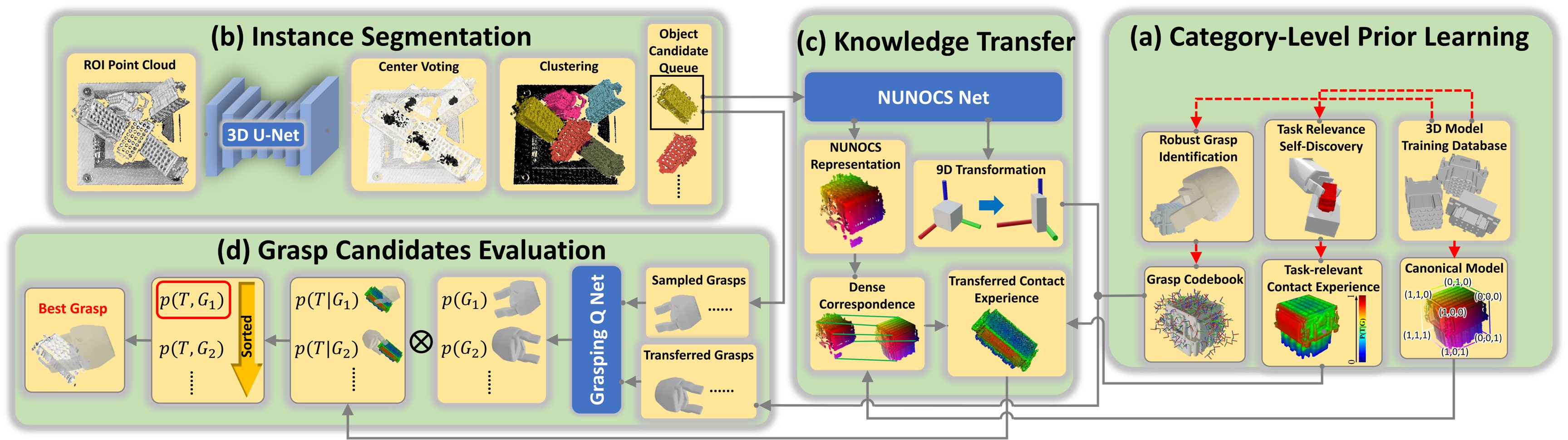
CaTGrasp:通过模拟学习杂乱环境中类别级任务相关的抓取
来源:ICRA 2022
本文的贡献如下:
- 一种学习类级别、任务相关的新框架, 能根绝下游的操作任务,从密集杂乱的物体堆中选择最佳抓取。据作者所知,这是第一个能针对密集杂乱的工业物体, 无需人工标注而学习任务相关的抓取姿态的工作
- 与以往的学习任务相关的稀疏关键点操作的方法不同,此工作在 3D空间对物体点云中逐点进行任务相关性的建模。为此,在模拟器中手和物体进行自监督的交互. 其中对接触点的交互经验用热力图做表征。这种稠密的3D表示避免了人工标注3D关键点的成本
算法流程:
- 问题陈述
我们考虑的是常见的工业场景: 相同类型的未曾见过的新型物体被收集到一个储物箱中,形成一个密集的杂乱堆。目标是计算与下游任务相关的6D 抓取姿势, 使得不仅能稳定抓取, 同时抓取后与下游的放置任务相容。下面列出了对框架的输入:
(1) 属于同一类别的3D 模型集用于离线训练。该模型集不包括任何 测试阶段的新颖物体.
(2) 对应于该类别的下游放置任务(如将螺母放到螺钉上),包括匹配的容器物体和对任务成功的评判标准
(3) 在测试时, 深度相机得到的深度图像
- 方法
离线阶段,给定同一类别的训练3D模型集,合成的数据集在模拟器中生成, 并用于训练NUNOCS Net, Grasping Q Net和3D U-Net。然后, 在模拟器中的自我交互试错提供了机械爪和物体的接触经验。该经验总结为任务相关性的热力图表征。统一的NUNOCS表征使得同一类的各个物体任务相关知识整合到一起。在现测试阶段,类级别的知识通过NUNOCS得到的稠密匹配和9D类级别姿态从统一的NUNOCS空间转换到新颖的测试物体点云空间,实现带语义的任务相关抓取
code


















 1113
1113

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









