




 这篇论文介绍了一种新的损失函数——自适应类抑制损失(ACSL),用于解决长尾分布数据集中的目标检测问题。ACSL克服了基于组方法的局限性,无需预先定义类别组,而是根据网络学习状态自适应调整抑制梯度,提高尾部类别的识别性能。在LVIS和Open Images数据集上的实验表明,ACSL能显著提升罕见类别的检测精度,整体性能优于现有方法。
这篇论文介绍了一种新的损失函数——自适应类抑制损失(ACSL),用于解决长尾分布数据集中的目标检测问题。ACSL克服了基于组方法的局限性,无需预先定义类别组,而是根据网络学习状态自适应调整抑制梯度,提高尾部类别的识别性能。在LVIS和Open Images数据集上的实验表明,ACSL能显著提升罕见类别的检测精度,整体性能优于现有方法。
这一篇也是关于解决对长尾条件下的目标检测。
我觉得与《Focal loss》相似,都是在交叉熵损失函数上进行了优化。
CVPR2021
链接: 论文链接.
代码:链接: 开源代码.
提出了一种新的动态类别抑制损失 ACSL
摘要
针对大词汇量目标检测任务的长尾分布问题,现有的方法通常将整个类别划分为若干组,并对每组采用不同的策略进行处理。这些方法带来了以下两个问题。一个是相似大小的相邻类别之间的训练不一致,另一个是学习模型缺乏对尾部类别的区分,尾部类别在语义上与头部类别相似。本文设计了一种新的自适应类抑制损失(Adaptive Class Suppression Loss, ACSL),有效地解决了上述问题,提高了尾类的检测性能。具体来说,我们引入了一个无统计的视角来分析长尾分布,打破了手工分组的限制。根据这一视角,我们的ACSL自适应调整每个类别的每个样本的抑制梯度,确保训练的一致性,提高了对罕见类别的识别。在长尾数据集LVIS和Open Images上的大量实验表明,我们的ACSL与ResNet50-FPN相比,分别实现了5.18%和5.2%的改进,达到了新的水平。代码和模型可以在上找到。
1. Introduction
随着深度卷积神经网络的出现,研究人员在目标检测任务上取得了重大进展。为了刷新PASCAL VOC[9]和MS COCO[21]等经典基准的记录,我们付出了很多努力。然而,这些基准通常只有有限数量的类,并且表现出相对均衡的类别分布。然而,在现实场景中,数据通常具有长尾分布。少量的头类(频繁类)贡献了大部分的训练样本,而大量的尾类(罕见类)在数据中没有得到充分的代表。这种极度不平衡的阶级分布给研究人员提出了新的挑战。
一种直观的解决方案是通过重采样技术重新平衡数据分布[12,7,28,23]。通过对尾部样本的过度采样或对头部样本的不足采样,可以人为地产生一个不那么不平衡的分布。然而,过采样通常会给尾部类带来不良的过拟合问题。而抽样不足可能会错过头班的宝贵信息。当数据集极度不平衡时,这种技术的有效性是有限的。为了提高尾类的性能,同时避免过拟合问题,Tan等人[29]设计了equal Loss,认为尾类性能差的原因是对头类样本的过度抑制。由于尾类只包含很少的样本,它们在训练过程中接收到的负梯度比正梯度多得多,因此在大部分的训练时间里,尾类始终处于被抑制的状态。为了防止尾部分类器被过度抑制,均衡损失提出忽略所有来自头部类的负梯度。balbalanced Group Softmax (BAGS)[18]将训练实例数量相近的类别放入同一组,分别按组计算Softmax交叉熵损失。BAGS在组内达到相对平衡,有效改善头类对尾类的支配。
上述方法可以有效地降低对尾部分类器的抑制。但是,他们需要先根据类别的频率将类别划分为几个组。这种头尾类划分困难带来了两个问题,即相邻类别的训练不一致,以及对少数类别缺乏区分能力。如图1所示,将实例统计量相似的两个类别分为两个不同的组时,它们的训练策略之间存在着巨大的差距。这种训练不一致可能会影响网络的性能。一般来说,用样本的绝对数目来区分头类和尾类是次优的。此外,对于类别词汇量大的数据集,经常会出现外观相似度高的两个类别所拥有的样本频率完全不同的情况。例如,“太阳镜”和“眼罩”分别属于头类和尾类。为防止尾分类器“眼罩”被过度抑制,“眼罩”分类器忽略“太阳镜”类的负梯度。然而,这也可以减少这些语义相似的情况在特征空间中的可区分性,“eye mask”分类器将样本“sunglasses”误分类为“eye mask”的概率很高。对于属于不同群体但外观相似度高的类别,网络很难学习具有区别性的特征表示。
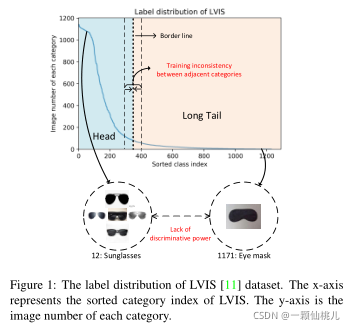
图1 L VIS[11]数据集的标签分布。x轴为L VIS已排序的类别索引,y轴为每个类别的图像编号。
因此,在本文中,我们提出了一种新的自适应类抑制损失(ACSL)来解决上述两个问题。设计理念简单明了:我们假设所有类别都来自“tail”组,并根据它们当前的学习状态自适应地生成每个类别的抑制梯度。具体来说,我们建议将所有对象类别视为稀缺类别,而不考虑每个类别实例的统计信息,从而消除手动定义头部和尾部的困境。此外,为了缓解学习和表示的不足,我们引入了自适应类抑制损失来自适应平衡不同类别之间的负梯度,有效地提高了尾部分类器的识别能力。一方面,该方法消除了数据分布的一些启发式和超参数。另一方面,它也避免了过度采样和欠采样造成的问题,并确保了所有类的训练一致性和对罕见或类似类别的充分学习。最后,它在大规模基准测试(如LVIS和Open Images)上的检测性能方面产生了可靠和显著的改进。综上所述,
本工作有以下三点贡献:
1.我们提出了一个新的无统计的观点来理解长尾分布,从而大大避免了手工难划分的困境。
2. 提出了一种新的自适应类抑制损失(adaptive class suppression loss, ACSL),可以有效地防止相邻类别的训练不一致,提高稀有类别的鉴别能力。
3. 我们对长尾目标检测数据集LVIS和Open Images进行
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 2200
2200

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









