




 深度长尾学习关注的是从长尾分布的图像数据中训练深度模型,解决真实世界中类不平衡的问题。文章对深度长尾学习的最新进展进行了全面调查,将方法分为类再平衡、信息增强和模块改进三大类,并通过相对准确度评估其性能。文章最后讨论了应用和未来研究方向。
深度长尾学习关注的是从长尾分布的图像数据中训练深度模型,解决真实世界中类不平衡的问题。文章对深度长尾学习的最新进展进行了全面调查,将方法分为类再平衡、信息增强和模块改进三大类,并通过相对准确度评估其性能。文章最后讨论了应用和未来研究方向。
Deep Long-Tailed Learning: A Survey
深度长尾学习是视觉识别中最具挑战性的问题之一,旨在从大量遵循长尾类分布的图像中训练出表现良好的深度模型。在过去的十年中,深度学习已经成为学习高质量图像表征的强大识别模型,并在通用视觉识别方面取得了显著的突破。
然而,长尾类不平衡是实际视觉识别任务中的一个常见问题,它往往限制了基于深度网络的识别模型在实际应用中的实用性,因为它们很容易偏向优势类,而在尾部类上表现不佳。
为了解决这个问题,近年来进行了大量的研究,在深度长尾学习领域取得了可喜的进展。
考虑到这一领域的快速发展,本文旨在对深度长尾学习的最新进展做一个全面的调查。具体来说,我们将现有的深度长尾学习研究分为三大类(即 类的再平衡、信息增强和模块改进),并按照这一分类法对这些方法进行了详细的回顾。
之后,我们对几种最先进的方法进行了实证分析,通过新提出的评价指标,即相对准确度,评估它们在多大程度上解决了类不平衡的问题。
在调查的最后,我们强调了深度长尾学习的重要应用,并确定了未来研究的几个有希望的方向。
1 INTRODUCTION
深度学习允许由多个处理层组成的计算模型学习具有多层次抽象的数据表示[1], [2],并在计算机视觉方面取得了令人难以置信的进展[3], [4], [5], [6], [7], [8]。深度学习的关键推动因素是大规模数据集的可用性,GPU的出现,以及深度网络架构的进步[9]。得益于学习高质量数据表征的强大能力,深度神经网络已被成功应用于许多视觉判别任务,包括图像分类[6]、[10]、物体检测[7]、[11]和语义分割[8]、[12]。
在现实世界的应用中,训练样本通常表现为长尾类分布,其中一小部分类有大量的样本点,但其他类只与少数样本相关[13], [14], [15], [16]。然而,这种训练样本数的类不平衡,使得基于深度网络的识别模型的训练非常具有挑战性。如图1所示,训练后的模型很容易偏向于有大量训练数据的头部类,导致在数据有限的尾部类上的模型表现不佳[17], [18], [19]。因此,通过经验风险最小化[20]的普遍做法训练的深度模型不能处理具有长尾类不平衡的现实世界应用,例如,人脸识别[21],[22],物种分类[23],[24],医学图像诊断[25],城市场景理解[26]和无人驾驶飞行器检测[27]。
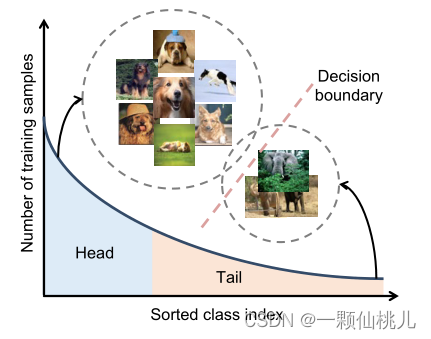
图1. 长尾数据集的标签分布(如iNaturalist物种数据集[23],有8,000多个类)。在这些取样上学习到的头类特征空间往往比尾类大,而决策边界通常偏向于优势类。
为了解决长尾类
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 807
807

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









