







- 保存和加载模型、优化器、随机数生成器和 GradScaler
- 使用
save_state()将上述所有内容保存到一个文件夹位置 - 使用
load_state()加载之前通过save_state()保存的状态
- 使用
- 通过使用
register_for_checkpointing(),可以注册自定义对象以便自动从前两个函数中存储或加载- 只要对象具有
state_dict和load_state_dict功能即可 - 这可以包括诸如学习率调度器之类的对象。
- 只要对象具有
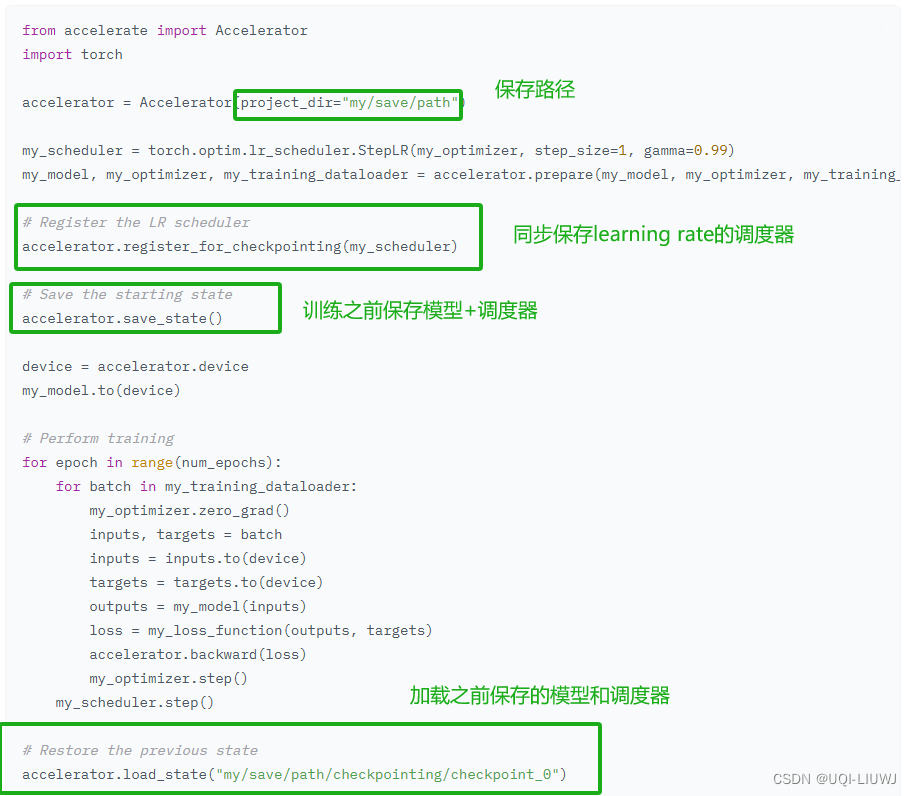
【经过实践结果,save_state需要传入一个参数,output_dir=】
2 保存模型的state_dict
- 在保存模型的 state_dict 时,通常只在主进程上保存一个文件:
if accelerator.is_main_process:
model = accelerator.unwrap_model(model)
torch.save(model.state_dict(), "weights.pth")
unwrap见:huggingface笔记:使用accelerate加速_huggingface accelerate-优快云博客


















 5886
5886

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











