









 本周的课程介绍了NLP中的词嵌入概念,包括skip-grams、word-embedding,以及在情感分析中的应用。通过词嵌入,相似或同类词汇在高维空间中的距离更近,可用于命名识别、文本解析等任务。同时讨论了词嵌入训练方法,如神经网络、word2vec的skip-grams模型和负采样,以及glove词向量模型。
本周的课程介绍了NLP中的词嵌入概念,包括skip-grams、word-embedding,以及在情感分析中的应用。通过词嵌入,相似或同类词汇在高维空间中的距离更近,可用于命名识别、文本解析等任务。同时讨论了词嵌入训练方法,如神经网络、word2vec的skip-grams模型和负采样,以及glove词向量模型。
上一周的课程主要讲解了一些经典的序列模型,例如RNN,GRU,LSTM等,这周的内容将包括NLP的一些概念讲解以及word embedding的内容,将NLP运用在序列模型中。
词汇表述
例如有一个词汇列表:V=[a,arron,…,zulu,< UNK >],假设当前词汇列表长度为10000,可用1-hot 表述词汇,若Man这个单词在词汇表中排第5391个,那么Man可用[0,0,0,…,1,…,0,0] (1的index=5391,向量为10000 * 1),这种表述方法有种缺点就是将每个词孤立起来,词语词之间的关系被割断,因此对相关词的泛化能力不强,这是因为用这种表述方式之后不同词的内积都是0。
那么就得考虑另一种表述方式:特征表示
用各种特征去衡量每个单词,这种表述更注重单词的词义,用-1~1之间的数去描述每个词与每个特征的相关性,
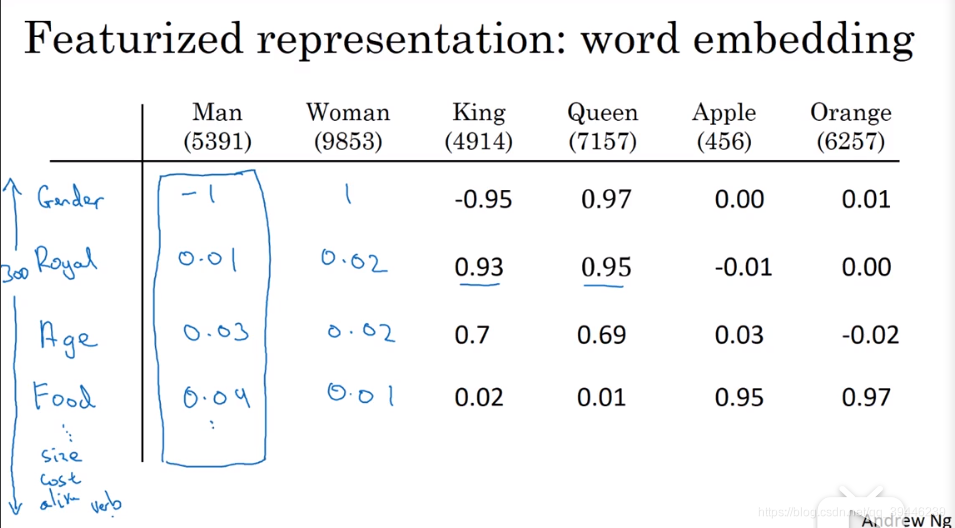
在实际中,特征含义可能没有上图表示的那么清晰,毕竟很多特征都是根据词汇生成的,但可以准确衡量苹果与橘子之间的相关性大于王后和橘子。
此外,我们会利用 t-SNE 方法将300维的特征向量映射到2维向量中,实现可视化。
详解词嵌入
词嵌入,顾名思义是通过一系列学习,将每个词 嵌入到一个高维的空间去,且与之有相似含义或同一类别的词汇在空间中的距离会更接近,而空间的维度则是表述这个单词的特征数目。词嵌入的训练样本通常很大,可能有1亿甚至100亿,所以需要用到迁移学习的方法,将从其他大文本中学到的词嵌入模型用在小文本中去embedding。

注:当样本量较大时,才做第三步的微调工作。
当训练的文本较小时,词嵌入的作用才最明显,所以它广泛用于命名识别、文本解析、文本摘要、指代消解中,而在机器翻译,语言模型中使用较少,
词嵌入特性–类比
如下问题: man-women 正比于 king - ?
算法做的事就是寻找一个vector使得: e_man - e_woman 近似等于 e_king - vector (其中e_xx 表示embedding向量),如下图所示

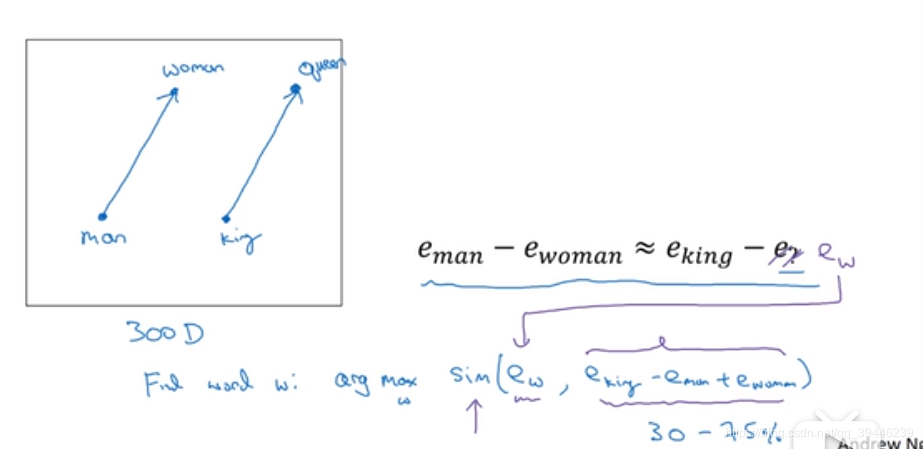
上面提到用t-SNE方法可将高维特征通过非线性变化转换到2维平面,我们希望得到这种二维平面后,能够通过寻找两条平行的向量去判断类比关系(这也是上述arg max sim(e_w,e_king - e_man + e_woman) 的几何特征)。但是由于映射是一个极复杂的非线性变换,最后是很难得到完美的两条平行线的,故对sim(similarity)的衡量修正为余弦距离(cosine similarity):
s
i
m
(
u
,
v
)
=
u
T
v
∣
∣
u
∣
∣
2
∣
∣
v
∣
∣
2
sim(u,v) = \dfrac {u^Tv}{||u||_2||v||_2}
sim(u,v)=∣∣u∣∣2∣∣v∣∣2uTv,余弦距离度量的是两个变量之间的角度,角度为0时,值为1,表明相似度最高。
embedding matrix
-
学习词嵌入矩阵的算法-- 神经网络:
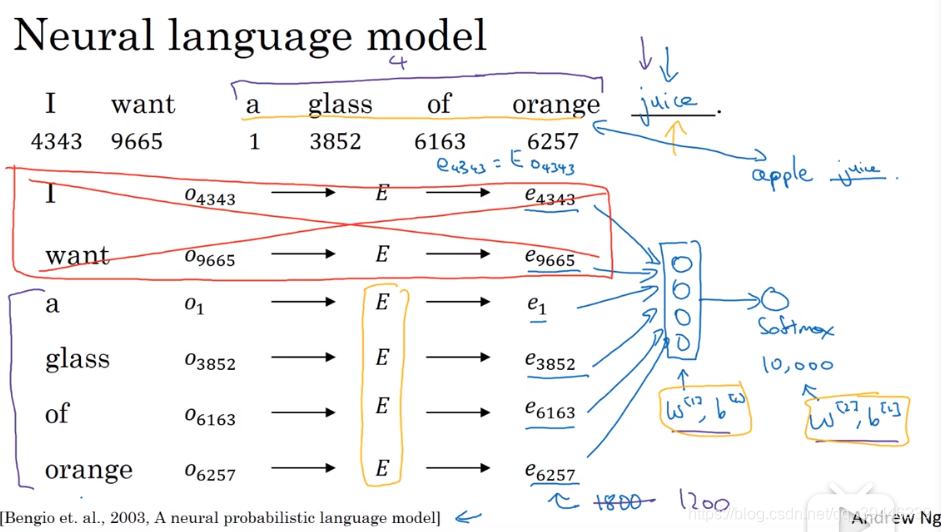
针对同一个词嵌入矩阵E,在固定特征维度(此处为300)以及词列表长度(此处为10000)的情况下,通过搭建一个浅层网络,不断输入各种预料文本,训练得到E matrix。这个模型的细节在于:从输入的文本中,对每个词摘取对应位置的E特征,例子中给定了6个word,将这6个词的E 向量作为输入传递给隐藏层,最后用一个softmax层得到预测,随后通过反向传播更新E(每次只更新对应输入的向量,例如这里是第9665,1,3852…6257这几列的值)以及网络层的参数。通过各种语料的训练,最后能得到E matrix。此外,在训练模型时也可以限制窗口,例如每次只输入四个(如上图所示,只输入后四个向量),这样可以训练任何长度的语料,下面这幅图介绍了一些选择输入的方法:

其中,如果想训练语言模型,可以用第一种选择文本的方法;如果想训练词嵌入,后面三种方法十分有效。 -
学习词嵌入矩阵的简易算法-- word2vec:
skip-grams模型
在文本中随机抽取上下文 (context) 和目标词 (object) 配对 来构造一个监督学习问题。随机选择一个词作为上下文词,在随机词的一定范围内选择目标词(范围可以是前后10个词等),利用context和object训练模型。这就类似于用中心词(这里的context)去预测中心词附近词,对于skip-gram更详细的介绍可见另一篇博客。对于上下文词汇的选择也不单单是通过均匀分布随机选取,这样会花费大量时间训练 to, the 等这些出现频率高的词,而在 orange,apple 等这些词的训练投入时间过少,所以设计一些方法来平衡common words 和 uncommon words。有关于监督学习的模型见下图:
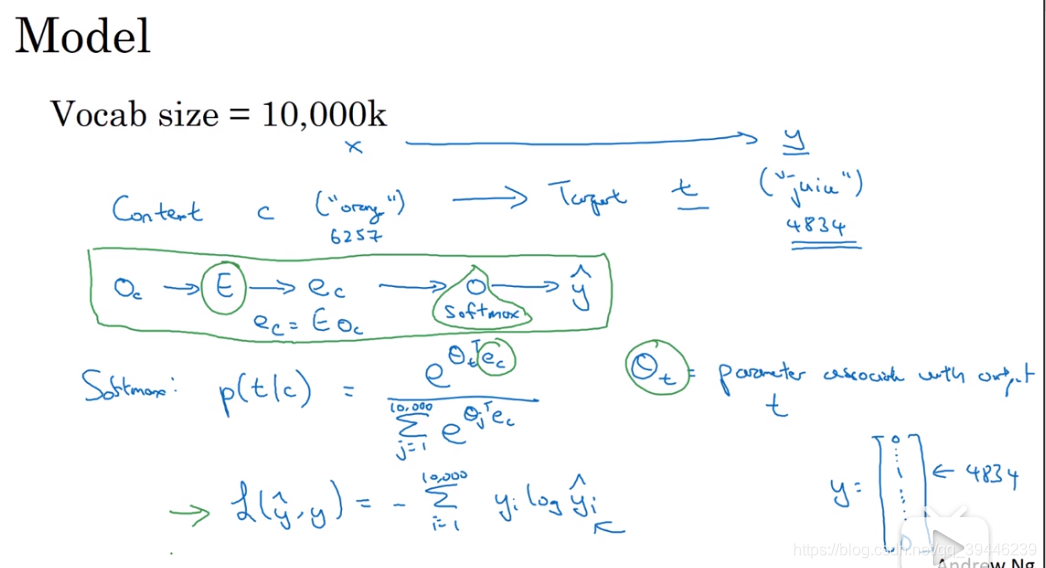
上图其实训练了一个softmax 层, θ t , E \theta _t,E θt,E为模型参数。
但这个问题存在一些问题,但其计算p(t|c)时的计算速度十分慢,改进的方法是利用分级softmax分类器 Hierarchical softmax classifier,该分类器将词汇分成一个二叉树结构,所以不再需要计算单词表内的每个单词,其计算成本与词汇表大小的对数log(vsize)成正比。在实际中,分级softmax分类器不会使用一颗完美平衡的分类树,而是将常用词至于顶部。
负采样
通过采样生成正负样本。首先从文本中随机抽取一个上下文词汇(context)并从其前后n个单词范围内抽取一个目标词(object)并将这组词定义为正样本;然后将选中的context 搭配其他词汇(从字典中选择任意词汇)作为负样本。如下图所示:
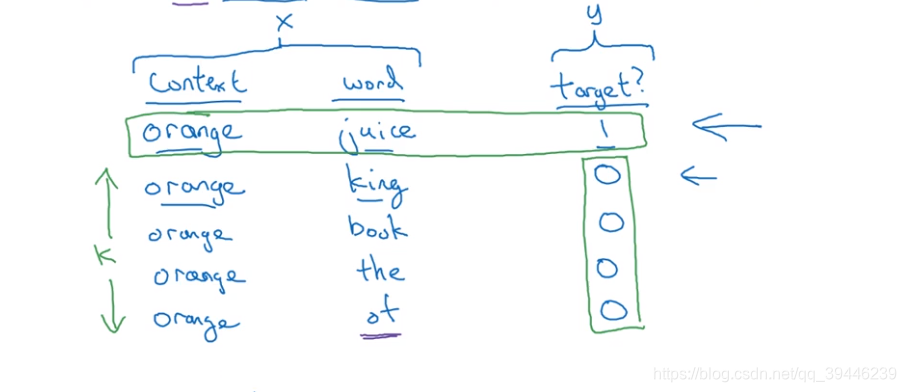
得到以上训练集之后,将配对词汇作为x,terget作为y 通过一个监督学习方法做训练。在小数据集中,负样本的个数k取值通常在5-20,而大数据集中,k的取值在2-5之间。
利用逻辑回归方法训练模型,主要是:构建与词汇表数目相等个数的二分类逻辑回归,每次迭代都随机抽取k个负样本,训练K+1个logistic模型(负样本内k个词汇对应的模型)。这种方法将10000维的 softmax 转换为10000个二分类问题,因此更加高效。
- 如何选择负样本?
两个极端情况是:根据字典内的词频、均匀分布;但两种方法都过于极端,andrew 提议的一种方法是以下图的方法对词频做一个调整以作为抽样频率
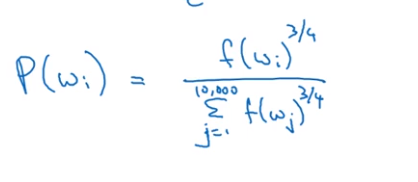
- 学习词嵌入矩阵的简易算法-- glove词向量
用 x i j x_{ij} xij表示单词i在单词j上下文出现的次数,i和j的功能类似于t和c,可以认为 x i j x_{ij} xij等价于 x t c x_{tc} xtc,可以遍历所有文本,计算i和j在不同上下文中出现的次数,此外,当上下文定义为前后5个词时, x i j = x j i x_{ij}=x_{ji} xij=xji,当定义为t为c前面的1个词时, x i j ! = x j i x_{ij}!=x_{ji} xij!=xji。
模型:KaTeX parse error: Expected group after '^' at position 63: …Te_j + b_i +b_j^̲' - \log x_{ij}…
其中 f ( x i j ) f(x_{ij}) f(xij)为词的权重,例如KaTeX parse error: Expected 'EOF', got '}' at position 6: x_[ij}̲为0时,对应的f也为0,并定义0log0=0,这样对最终的计算不产生影响,此外f的存在可以给停词和不常见的词一个更合理的权重。模型中的 θ i \theta_i θi和KaTeX parse error: Expected 'EOF', got '\e' at position 1: \̲e̲_j实际上是对称的,所以在计算单词w的embedding向量时,可用 e w ( f i n a l ) = e w + θ w 2 e_w^{(final)}=\dfrac{e_w+\theta_w}{2} ew(final)=2ew+θw计算。
需要注意:通过上述这些方法,例如skip-gram、负采样、glove,最终学习到的E矩阵的每个维度不一定是相互独立的也不一定可解释的。
情感分析
根据词汇表将句子中的每个单词转变成one-hot编码,分别乘E矩阵,得到语义向量,将语义向量平均后训练softmax分类器,将语句映射为1-5星。
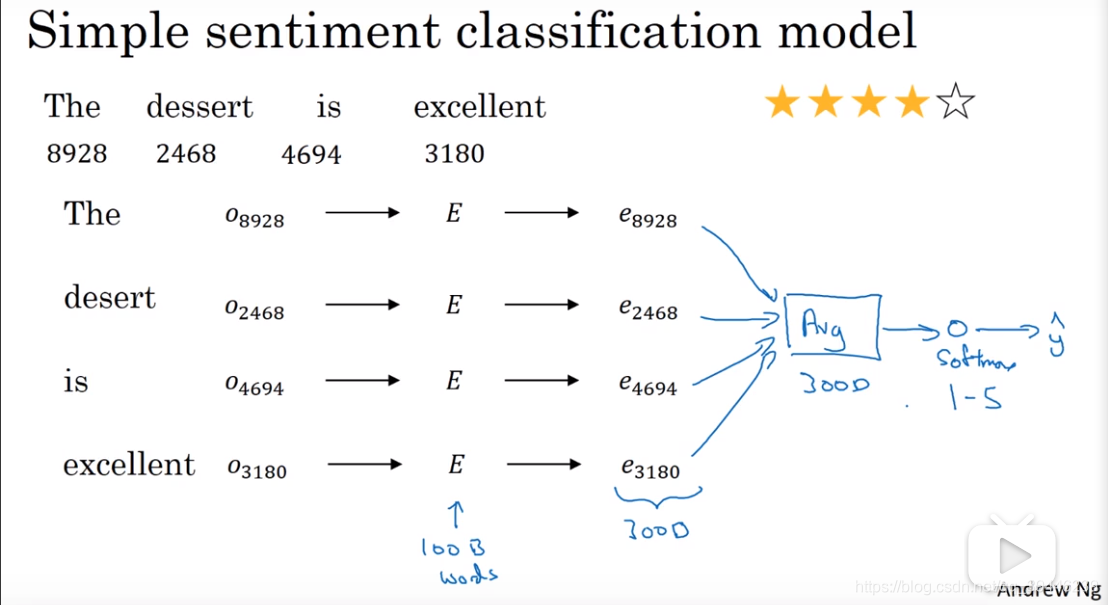
此算法的缺点是没有考虑到语序,例如:‘Completely lacking in good taste, good service, and good ambience.’该句多次出现good,用上述算法最终产生正向的评论,改进方法是利用RNN训练模型

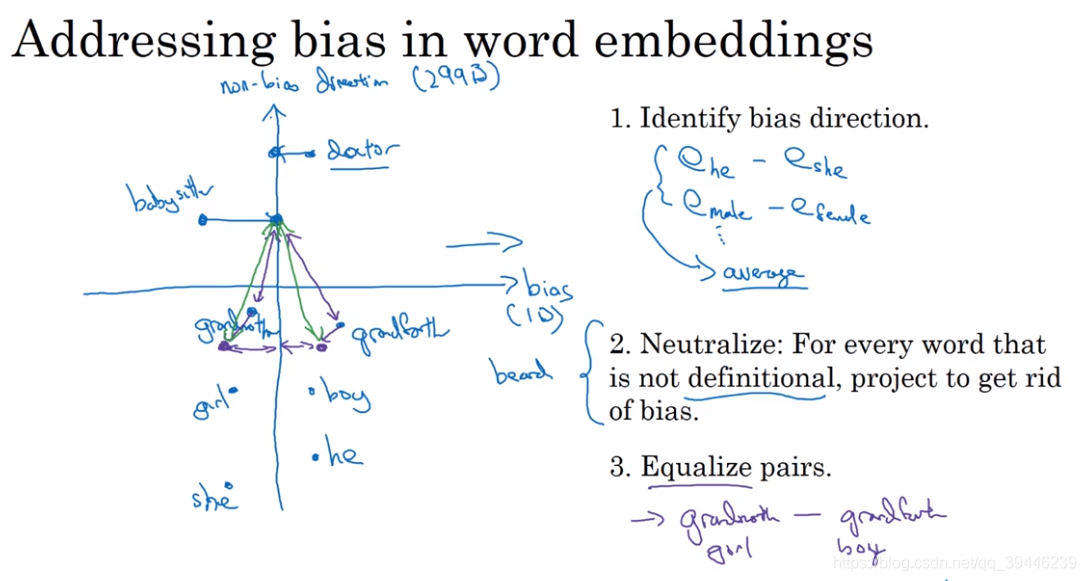
从文本学习的词嵌入可能会携带一些偏见,例如性别歧视、种族歧视等。
消除词嵌入中的偏见:
1.定义想消除的偏见方向(例如性别)
2.对中立词消除bias
3.均衡步(调整非中立词)

















 978
978

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









