







 B-Tree和B+Tree是为了解决大规模数据存储时的寻道时间问题,通过减少磁盘IO次数来提高磁盘读取效率。B-Tree每个节点同时存储索引和数据,而B+Tree只在叶子节点存储数据,内部节点只存储索引。B+Tree所有叶子节点通过链表连接,便于数据遍历,且查询效率更稳定。
B-Tree和B+Tree是为了解决大规模数据存储时的寻道时间问题,通过减少磁盘IO次数来提高磁盘读取效率。B-Tree每个节点同时存储索引和数据,而B+Tree只在叶子节点存储数据,内部节点只存储索引。B+Tree所有叶子节点通过链表连接,便于数据遍历,且查询效率更稳定。
1.B-Tree
磁盘中有两个机械运动的部分,分别是磁盘旋转和磁头移动。
将磁头移动到磁盘表面的正确位置,花费的时间叫寻道时间。磁盘IO处理的快慢很大程度上取决于磁盘的寻道时间。磁盘旋转是为了传输数据。当大规模数据存储到磁盘中的时候,显然定位是一个非常花费时间的过程,但是我们可以通过B树进行优化,提高磁盘读取时定位的效率。
为什么B-Tree可以进行优化呢?我们可以根据B-Tree的特点,构造一个多阶的B-Tree,然后在尽量多的在结点上存储相关的信息,保证层数尽量的少,以便后面我们可以更快的找到信息,磁盘的I/O操作也少一些,而且B-Tree是平衡树,每个结点到叶子结点的高度都是相同,这也保证了每个查询是稳定的。
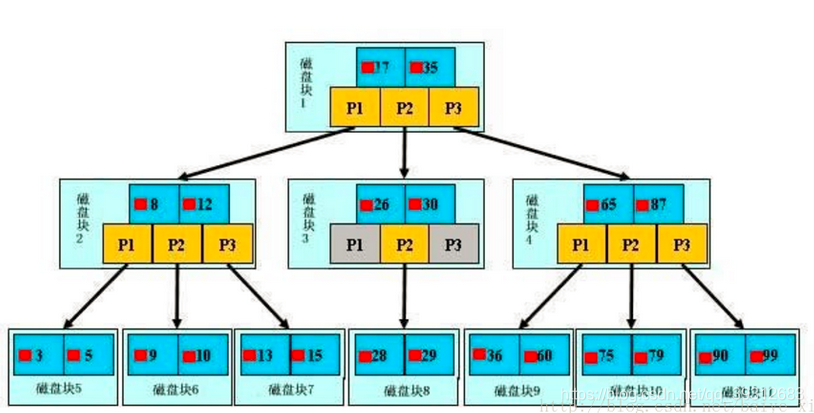
注:小红方块表示这个17文件内容在硬盘中的存储位置;p1表示指向17左子树的指针
1.每个节点中既要存索引信息,又要存其对应的数据,如果数据很大,那么当树的体量很大时,每次读到内存中的树的信息就会不太够。
2.B-Tree上大部分的操作所需要的磁盘IO次数和B-Tree的高度是成正比的,在B-Tree中一次磁盘IO可以检查多个子结点,由于在一棵树中检查任意一个结点都需要一次磁盘访问,所以B-Tree避免了大量的磁盘访问。
2.B+Tree
B+Tree相比B-Tree,本质上是一样的,区别在于:
1.B+Tree的所有根节点都不带有任何数据信息,只有索引信息,所有数据信息全部存储在叶子节点里,B+Tree的内部结点并没有指向关键字具体信息的指针。因此其内部结点相对B树更小。如果把所有同一内部结点的关键字存放在同一盘块中,那么盘块所能容纳的关键字数量也越多。一次性读入内存中的需要查找的关键字也就越多。相对来说IO读写次数也就降低了。
2.又由B树的性质可以得到,所有叶子节点都会在同一层,B+Tree会以一个链表的形式将所有叶子节点的信息全部串联起来,这样,想遍历所有数据信息只需要顺序遍历叶子节点就可以了,方便又高效。
3.B+Tree还有一个相应的优质特性,就是B+Tree的查询效率是非常稳定的,因为所有信息都存储在了叶子节点里面,从根节点到所有叶子节点的路径是相同的。


















 328
328

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









