









llama3 的词汇表有多少词汇
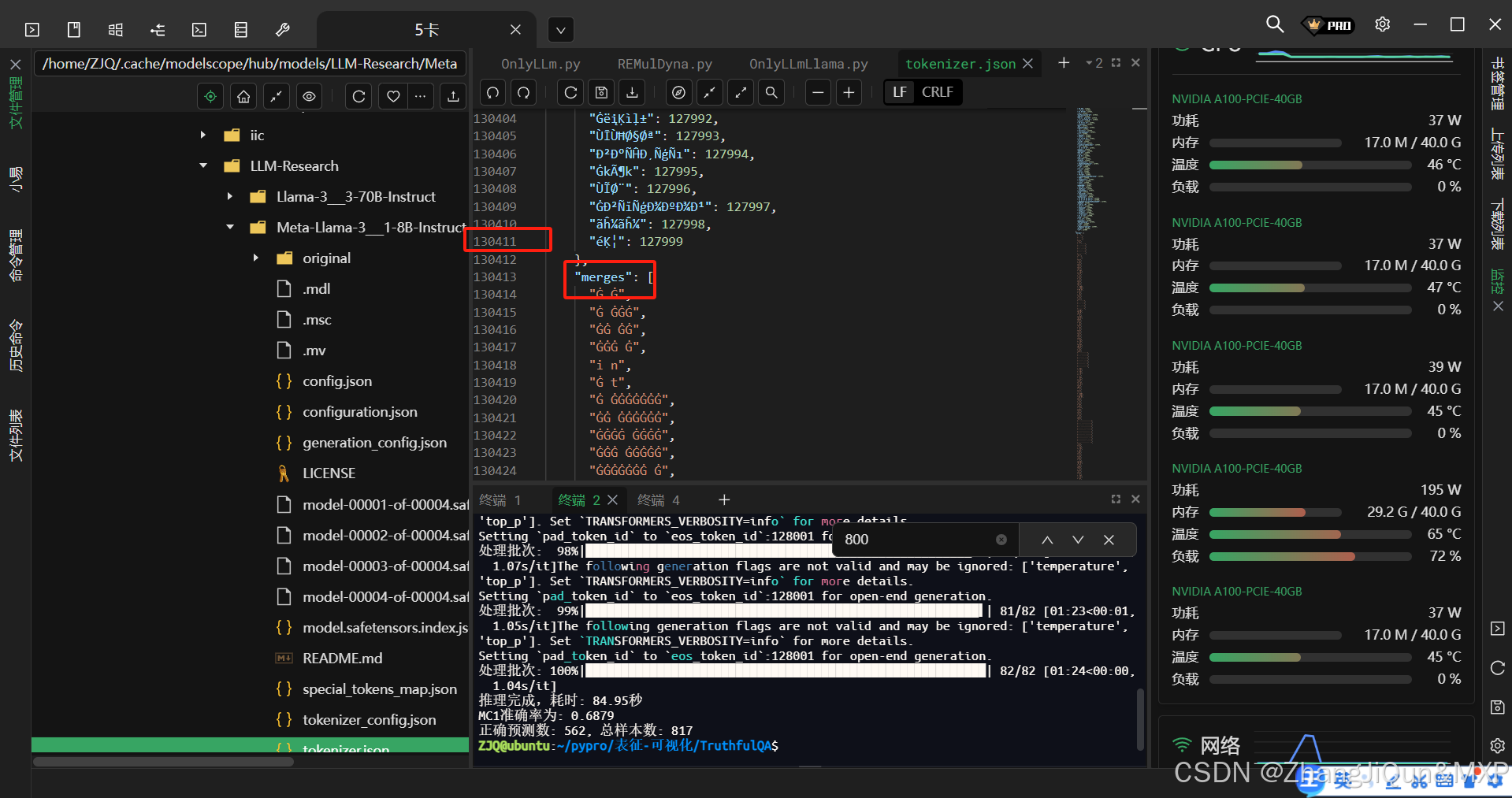
Meta发布的Llama 3模型的词汇表(token词汇量)大小为128,000个token。
这一词汇量相比Llama 2的32,000 token有显著扩展,主要是为了更好地支持多语言处理、覆盖更多专业术语、特殊符号及新兴词汇,从而提升模型在复杂场景下的表现。更大的词汇表有助于减少文本分词后的token数量,提高处理效率和上下文理解能力。
需要注意的是,这一词汇量包含了基础词汇、子词单元(subword units)、多语言字符及特殊标记(如分隔符、控制符等),是模型进行文本编码的基础。
llama 3 词汇表中的 vocab merges 是什么意思
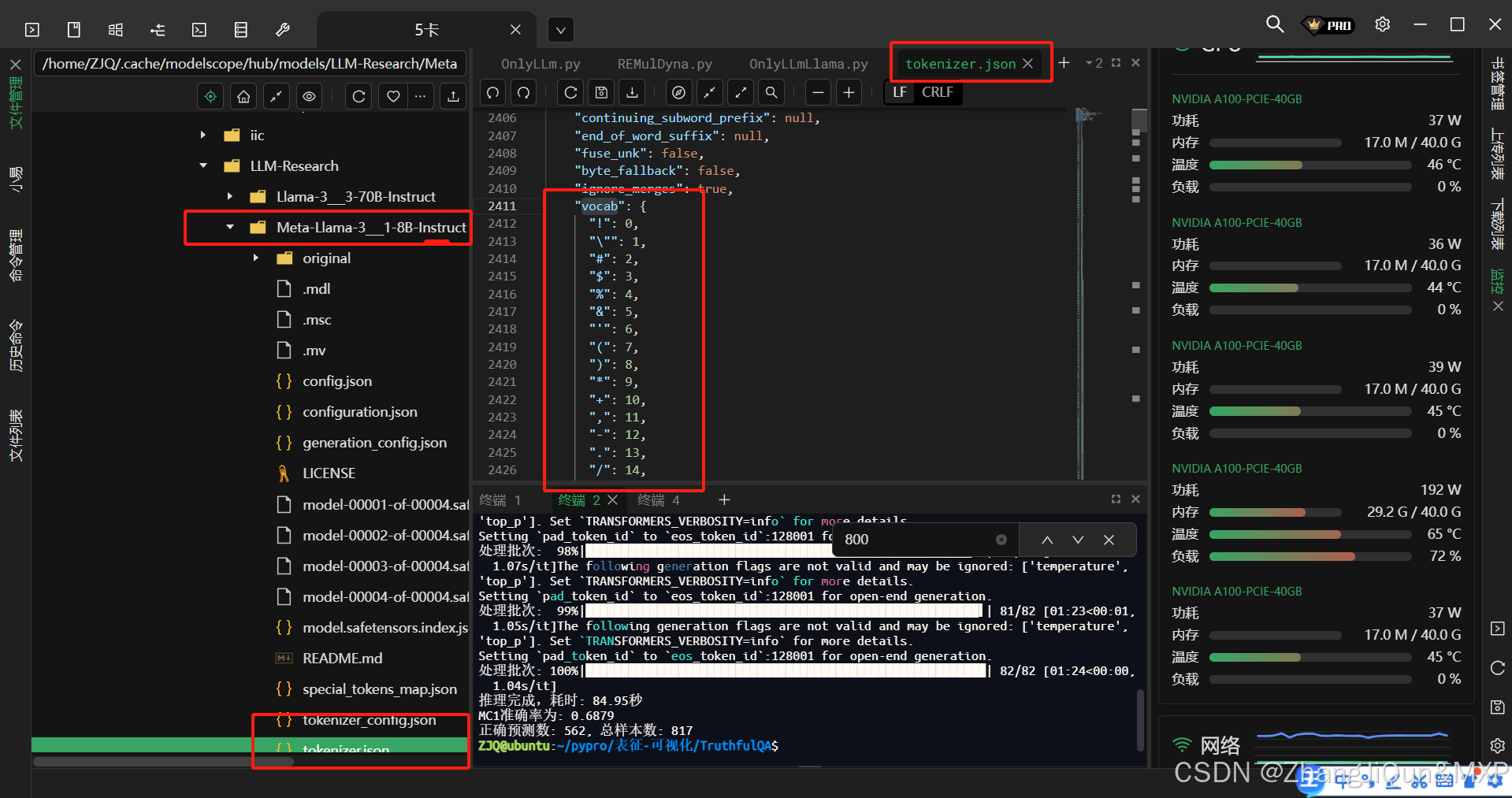
在LLM(如Llama 3)的分词器(tokenizer)中,vocab

 订阅专栏 解锁全文
订阅专栏 解锁全文


















 2074
2074

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











