









怎么对词编码进行可视化:Embedding Projector
https://projector.tensorflow.org/
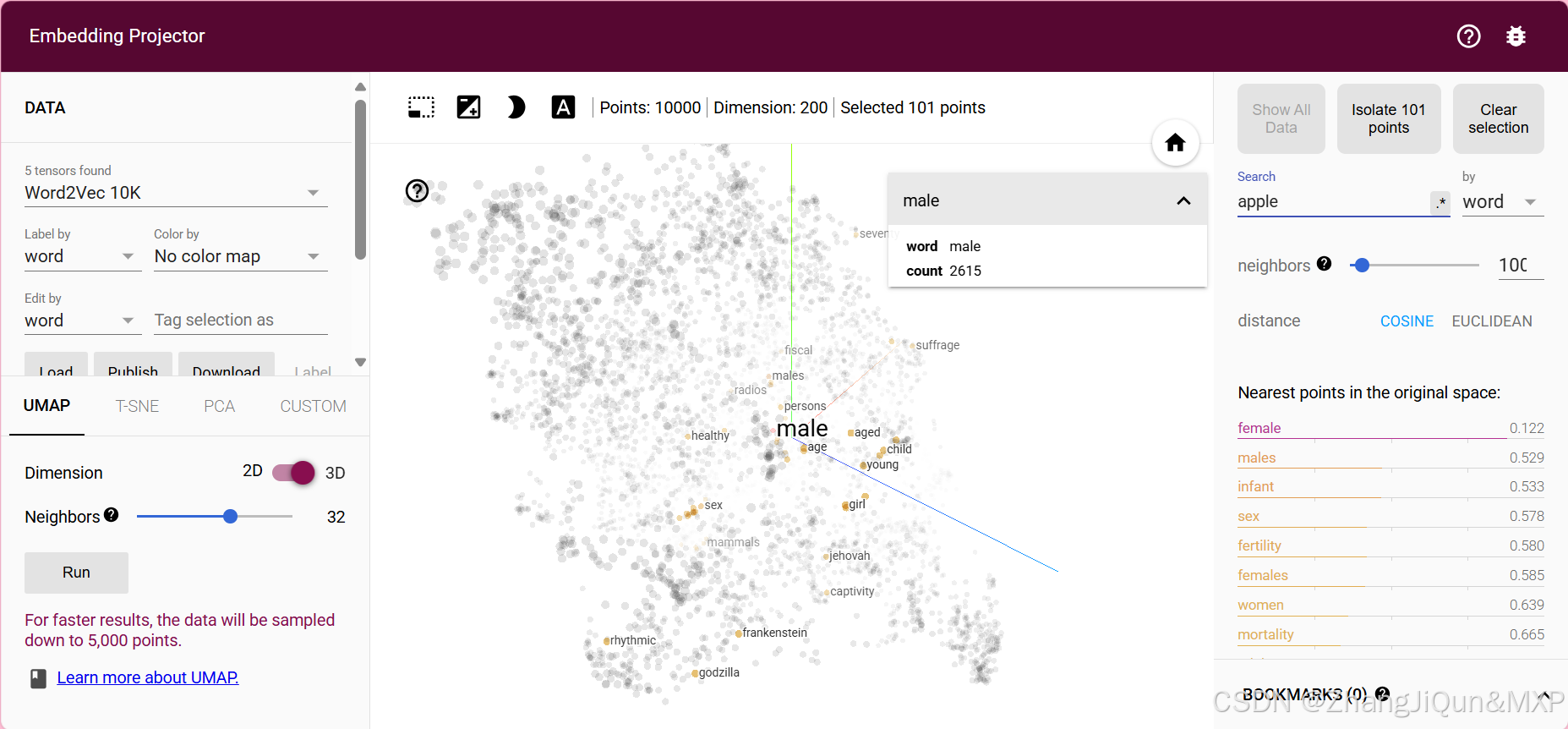
Embedding Projector是用于可视化高维向量嵌入(如词向量、图像特征向量等 )的工具,能帮你理解向量间的关系,下面以词向量分析和**简单自定义数据(比如特征向量)**为例,教你怎么用:
一、词向量分析场景(以图中Word2Vec数据为例)
1. 加载数据与基础查看
- 图里已加载Word2Vec 10K的词向量数据,界面左侧能选不同的降维算法(UMAP、T - SNE、PCA ),先选UMAP,维度选2D或3D,设置好“Neighbors”(邻居数,影响聚类效果 ),点“Run”,就能把高维词向量降维到二维/三维空间展示,这些点就代表一个个词的向量。
- 比如图中选中“male”这个词,右侧能看到它在原始空间里的最近邻词(像“female”“males”等 ),通过距离(如余弦距离、欧氏距离 )判断语义关联,“female”距离近,说明语义上和“male”很相关,符合我们对“男性、女性”语义关联的认知。

 订阅专栏 解锁全文
订阅专栏 解锁全文



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











