







可解释机器学习
可解释机器学习
1. 引言
关于坦克问题: 在识别图片中真假坦克时,AI错误的利用天气信息作为识别坦克的标准。
结论:
- 训练集、测试集要来自一个分布
- 神经网络 -> "黑箱子“
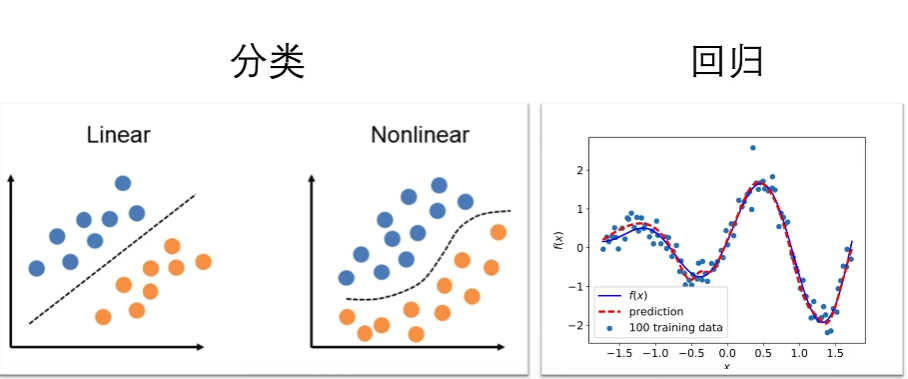
机器学习 大多数是 统计学习,即对数据的拟合。
在低维上,分类是用一条曲线将样本分开,回归是用一条曲线来拟合样本数据分布。在高维上,整个过程是个”黑箱子“。
2 .为什么要学习可解释机器学习

3. 可解释性好的机器学习算法
- KNN
- 逻辑回归
- 线性回归
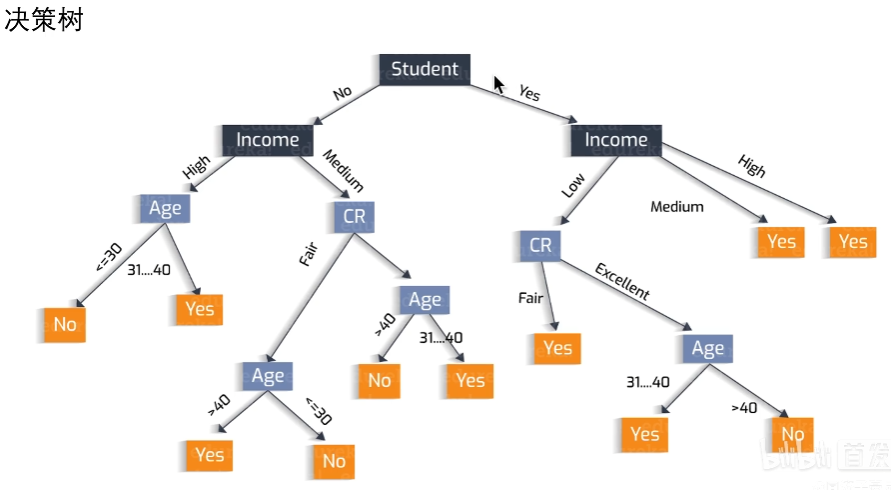
- 决策树
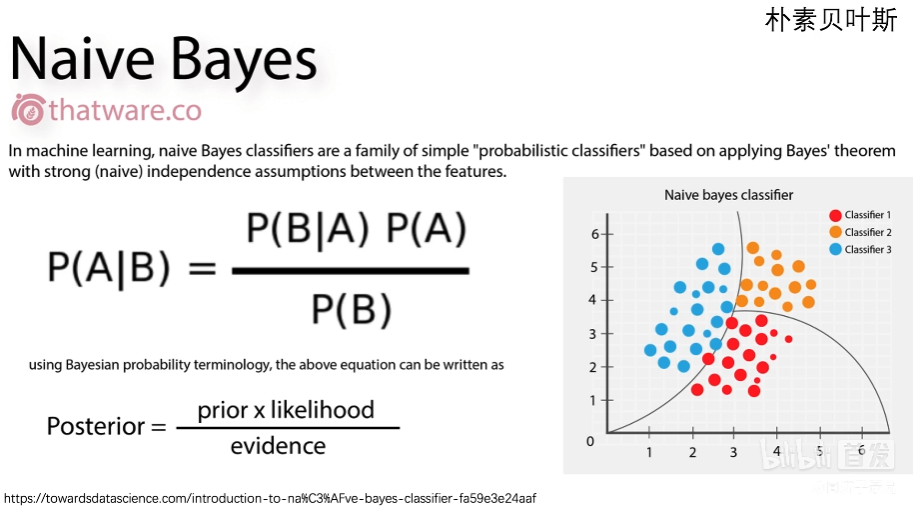
- 朴素贝叶斯
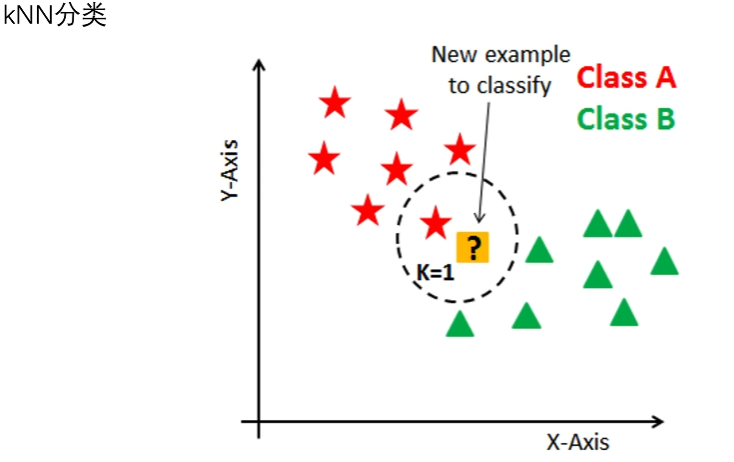
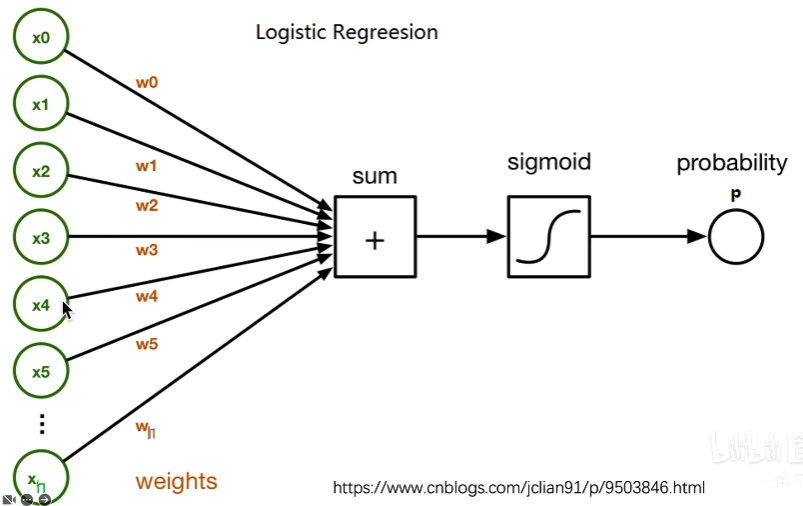
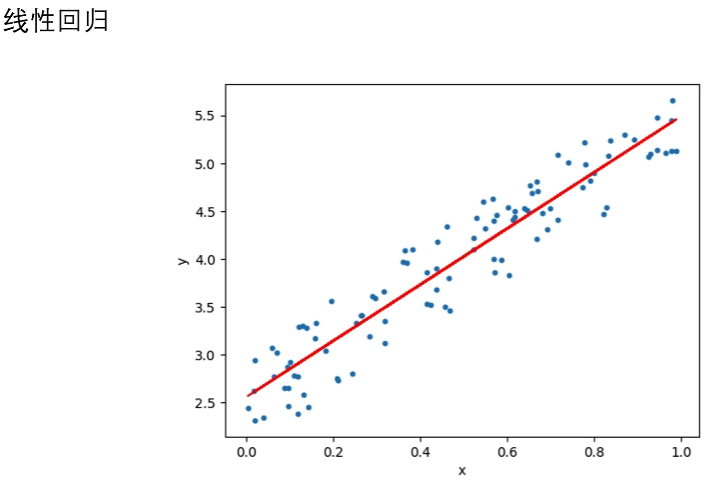
传统机器学习算法的可解释性分析
- 算法自带的可视化
- 算法自带的特征权重
- Permutation Importance 置换重要度 (判断特征打乱判断该特征是否重要)
- PDP 图、 ICE 图
- Shapley 值
- Lime
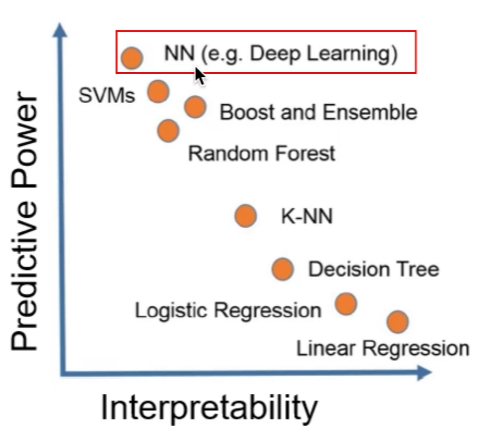
4. 深度学习的可解释性很差
卷积神经网络的可解释性分析
- 可视化卷积核、特征图
- 遮挡、缩放、平移、旋转
- 找到能使某个神经元激活的原图像素,或者小图
- 基于类激活热力图(CAM)的可视化
- 语义编码降维可视化
- 由语义编码倒推输入的原图
- 生成满足某些要求的图像(某类别预测概率最大)

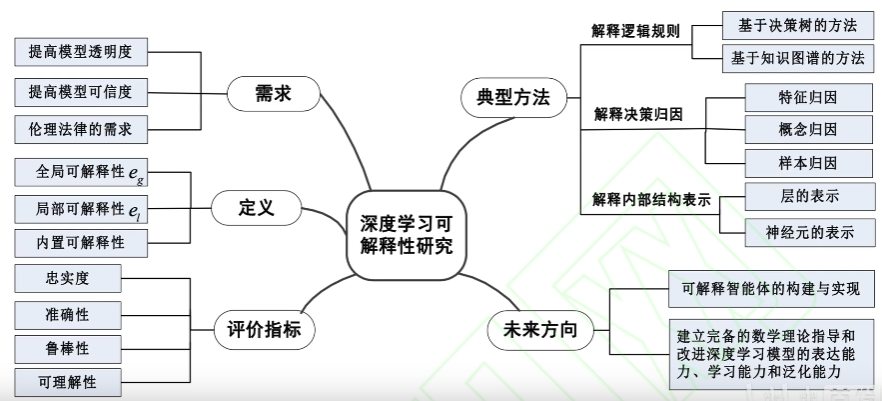
5. 总结

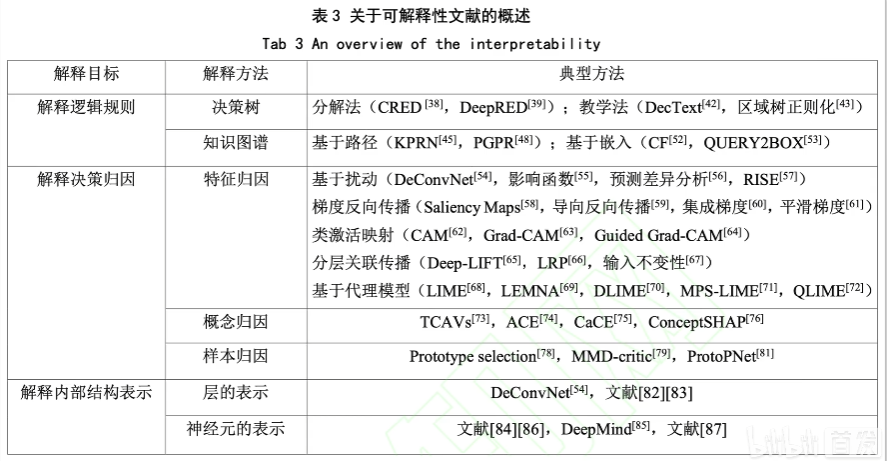
一些参考资料:
可解释分析、显著性分析代码实践
Pytorch-cnn-visualizations
总结论文


















 1174
1174

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









