







 本文详细介绍了Inception系列论文,包括Going Deeper with Convolutions和Rethinking the Inception Architecture for Computer Vision。文章指出,通过1x1卷积进行降维处理,可以解决网络深度与宽度增加带来的计算瓶颈和过拟合问题。Inception架构利用不同尺度的卷积处理视觉信息,确保网络能从多个尺度提取特征。此外,GoogLeNet中的辅助分类器在训练时增强梯度回传,提高了网络性能。
本文详细介绍了Inception系列论文,包括Going Deeper with Convolutions和Rethinking the Inception Architecture for Computer Vision。文章指出,通过1x1卷积进行降维处理,可以解决网络深度与宽度增加带来的计算瓶颈和过拟合问题。Inception架构利用不同尺度的卷积处理视觉信息,确保网络能从多个尺度提取特征。此外,GoogLeNet中的辅助分类器在训练时增强梯度回传,提高了网络性能。
1.Going deeper with convolutions
2.Related Work
NIN是一种提升神经网络特征表示能力的方法,将这种思想用在卷积网络中,这种方法可以看作是一个1x1的卷积层接一个ReLU激活函数构成。此外在我们的网络中1x1卷积核还有另一个作用:用作降维的模块,从而解决限制网络体量的计算瓶颈。这允许我们在不损失重要的性能表现的情况下使得网络更深且更宽。
3.Motivation and High Level Considerations
最直接的提升神经网络性能的方式就是增大其体量。从深度层面:增加其层数;从宽度层面:增加其每一层的单元数。但是这种方法主要有两个缺点。
首先是更大的网络会有更多的参数量,这意味着网络更容易过拟合,尤其是当训练数据集不够大的时候。
其次就是会使用更多的计算资源。
解决上述问题的方法是从全连接转为稀疏连接的结构,即便是在卷积层中。前人的主要结果表明,如果数据集的概率分布可以由一个大的、非常稀疏的深层神经网络表示,那么通过分析最后一层激活的相关统计和聚类高度相关的神经元的输出,可以逐层构造出最优的网络拓扑结构。这呼应了Hebbian principle,而Hebbian principle的精确表达就是如果两个神经元常常同时产生动作电位,或者说同时激动(fire),这两个神经元之间的连接就会变强,反之则变弱(neurons that fire together, wire together)
4.Architectural Details
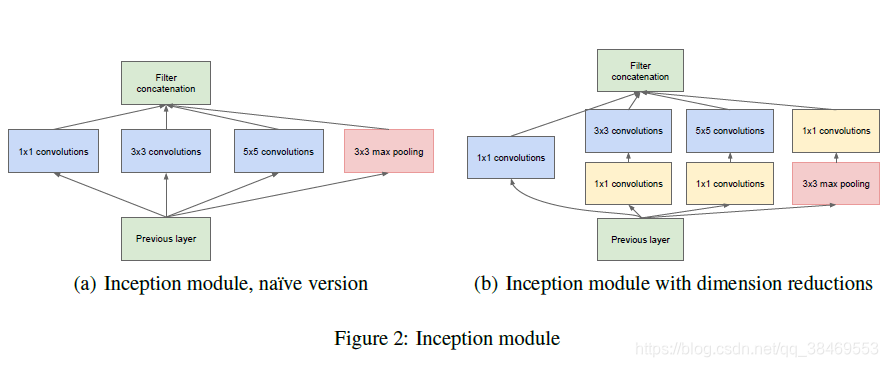
右图的1x1卷积用来做降维处理。这种方法基于已经成功的实现:即使低维度数也可能包含图片相关局部的大量的信息。
这种设计的另一个用处在于视觉信息在不同的尺度被处理之后再聚集起来,从而下一个stage能够同时从不同的尺度提取特征信息。
5.GoogLeNet
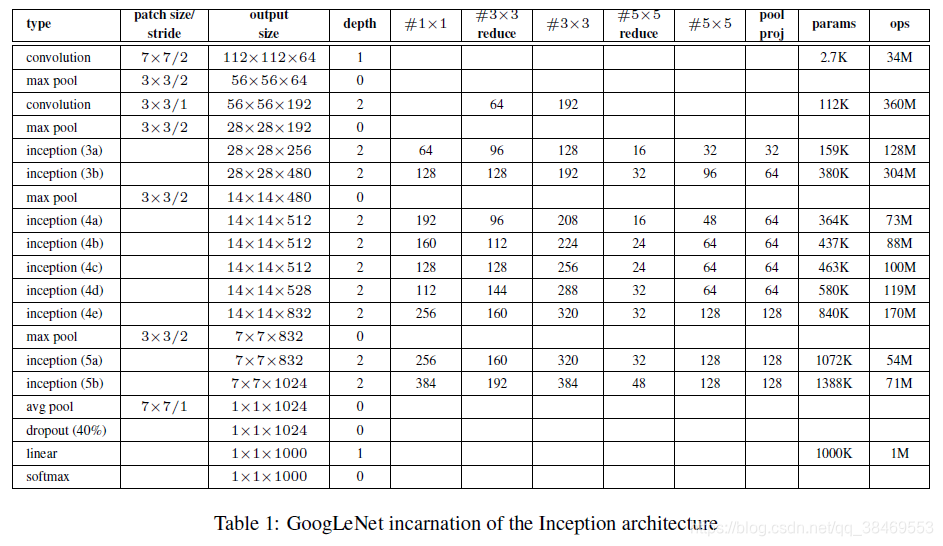
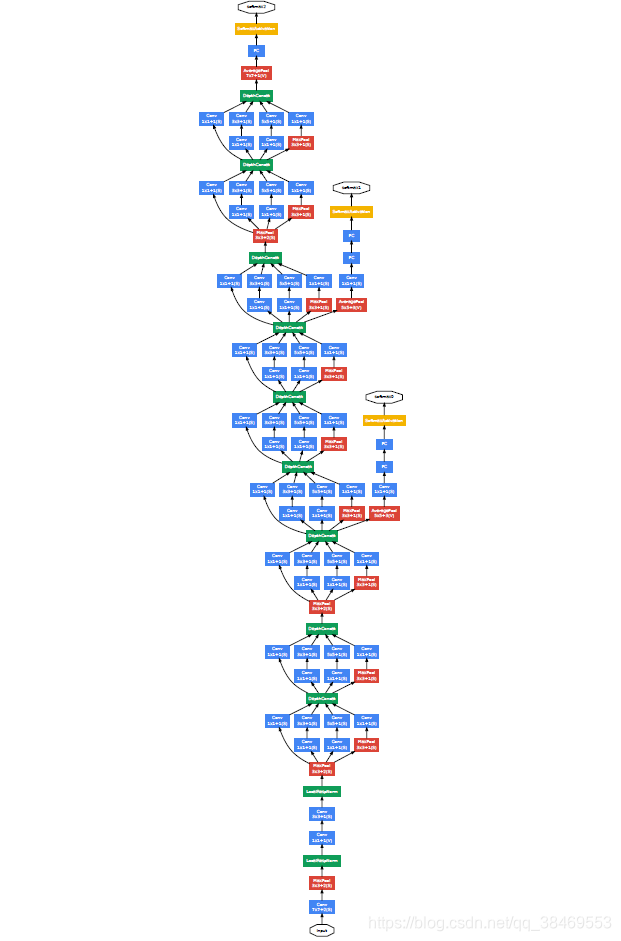
如果只计算包含参数的层,有22层。
对于较深的网络,梯度有效地回传很重要。研究表明网络中间层的特征具有很好的区分度。通过给这些中间层连接分类器,我们能在这些网络前几层的分类器中得到区分特性,增大梯度值并回传,从而提供了额外的约束。这样的分类器连接在网络的前部的 inception模块中(4a)(4b),在训练时这些分类器的loss以0.3的比例添加到总的loss中。在预测时这些辅助结构被丢弃。

















 3391
3391

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









