




 本文详细介绍了Inception网络系列的发展,从Inception-v1(GoogLeNet)到Inception-v4,重点讨论了每个版本的核心改进,如批量归一化(BN)、残差连接等。Inception-v1通过1x1卷积减少计算量,v2引入BN加速训练,v3优化了卷积结构,v4则结合了ResNet的残差块。每个版本都在提高网络性能的同时,努力降低计算成本和参数量。
本文详细介绍了Inception网络系列的发展,从Inception-v1(GoogLeNet)到Inception-v4,重点讨论了每个版本的核心改进,如批量归一化(BN)、残差连接等。Inception-v1通过1x1卷积减少计算量,v2引入BN加速训练,v3优化了卷积结构,v4则结合了ResNet的残差块。每个版本都在提高网络性能的同时,努力降低计算成本和参数量。
Inception系列
Paper
- v1: Going deeper with convolutions
- v2: Batch Normalization: Accelerating Deep Network Training by Reducing Internal Covariate Shift
- v3: Rethinking the Inception Architecture for Computer Vision
- v4: Inception-v4, Inception-ResNet and the Impact of Residual Connections on Learning
万字长文,建议收藏!
Inception-v1-2014
又名GoogLeNet,是一个22层的网络,取得了2014年ILSVRC比赛的冠军。
1、其设计初衷是可以在其基础上扩展宽度和深度。
2、其设计动机来自于提高深度网络的性能一般可以通过提高网络的大小和提高数据集的大小来提高,但同时会造成网络很容易过拟合和参数量过大、计算资源的低效率以及高质量数据集的制作是昂贵的问题。
3、其设计理念是将全连接改为稀疏架构,并尝试在卷积内部改为稀疏架构。
4、其主要的思想是设计了一个inception模块,并通过不断复制这些inception模块来提高网络的深度和宽度,不过GooLeNet主要还是在深度上扩展这些inception模块。
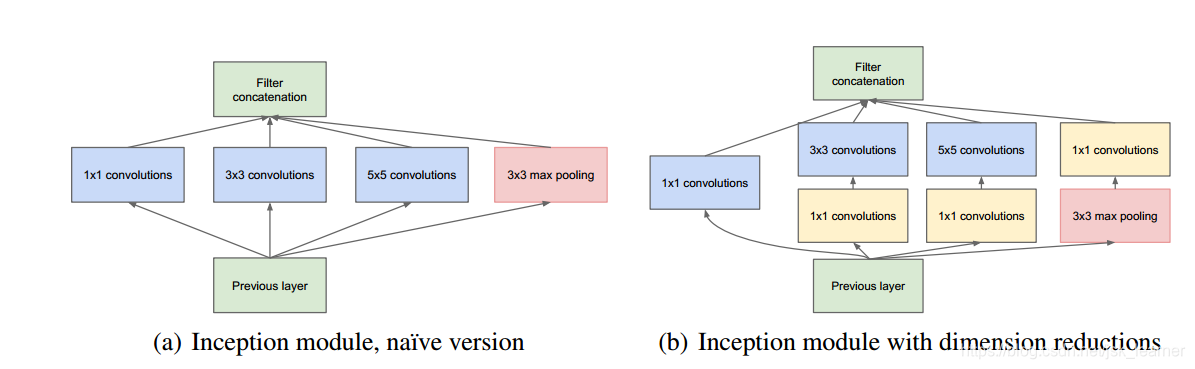
每一个inception模块中有四个并行通道,并在通道结束时进行concat。
1x1 conv在文章中主要是用来进行维度的降低以避免计算瓶颈。
其还在前面的网络层一些分支上加入了额外的softmax loss以避免梯度消失问题。
四个并行通道:
- 1x1的conv:借鉴了【Network in Network】,可以进行输入feature map的降维升维而不会太过损失输入的空间信息;
- 1x1conv followed by 3x3 conv:3x3 conv增大feature map的感受野,并通过1x1conv进行维度的更改;
- 1x1 conv followed by 5x5 conv:5x5 conv进一步增大feature map 的感受野,并通过1x1 conv进行维度的更改;
- 3x3 max pooling followed by 1x1 conv:作者认为pooling层虽然会损失空间信息,但是因为其已经有效的应用在很多领域,这证明了其有效性,所以加了一个并行通道,并同时通过1x1 conv来更改其输出维度。
接下来是对论文主要内容的简单翻译:
- Abstarct
本文提出了一个命名为Inception的深度卷积网络架构, 其成为2014年ILSVRC分类和检测比赛中最先进的方法。网络架构的主要特点是最大化利用网络内部的计算力。在保持计算负载稳定的前提下,通过精心的设计允许对网络的深度和宽度进行提升。为了最优化性能,网络架构是基于Hebbian原则,并且进行了多尺度处理。在2014ILSVRC中使用的是一个22层的网络,被命名为GooLeNet。
- Introduction
在过去三年里,由于深度学习的发展,更具体的卷积网络被提出,促进了图像分类和检测。一个值得振奋人心的消息是,大多数的进展不仅仅是更强大的硬件算力、更大的数据集、更大的模型的结果,而且是由于一些新的想法、算法以及在网络架构上的创新。我们的GooLeNet模型实际上用了比两年前AlexNet 12倍更少的参数,然而性能却更好。
对于大多数的实验,模型被设计在推理阶段来保持一个15亿的multiply-adds。
在这篇文章中,我们关注一个对计算机视觉更有效的深度神经网络架构,其被命名为Inception,名字源于Network in network这篇文章,并结合了“we need to go deeper”网络用语。在我们的情况下,deep有两种含义,首先是我们介绍了一种Inception module新的组织形式,而且可以直接的提升网络深度。
- Related work
LeNet-5开创了CNN的标准结构,在全连接层之前堆积的卷积层,可选择的一些标准化层和池化层。这种基础的设计和架构已经在MINIST和CIFAR中取得了显著的效果,甚至在ImageNet上都有很好地表现。但是对于Imagenet这种更大的数据集,趋势倾向于提升网络层的数量和其大小,同时使用dropout来避免过拟合的问题。
尽管最大池化会造成一些精细空间信息的损失,这种网络架构已经可以成功的应用在定位、目标检测以及人体姿态识别上。
本文在网络中使用1x1的卷积层主要有以下目的,它们被用来进行维度降低以避免计算瓶颈,而这种瓶颈往往会限制模型的大小。这不仅允许深度提升,而且允许在不损失性能的前提下去提升宽度。
当前在目标检测最显著的模型是R-CNN,其将检测问题分为两个阶段问题:充分利用低级特征,例如颜色以及针对类别的超像素一致性,同时用CNN分类器去进行这些位置的分类。
- Motivation and High Level Considerations
提高网络的性能的两种方式:
提升深度神经网络性能最直接的方法就是提升它们的大小。这包括深度,即层级的数量以及他们的宽度即每一层级单元的大小。
还有一个比较容易和安全的方式是提升训练数据的大小。
然而这两种方法都会造成两个弊端。
更大的模型意味着更多的参数量,这会使得网络更容易过拟合,特别是当训练数据集中的标签样本数量被限制的情况。
同时因为高质量训练集制作是棘手的和昂贵的,特别是当一些人类专家去分的时候也有很大的错误率。如下图。

另外一个短板是,统一提升网络的大小是会提升计算资源使用、例如,在一个深度网络中,如果两个卷积是链式的,对于其卷积核任何统一的提升都会造成需求资源二次方的增加。如果增加的能力是低效率的,例如如果大多数的权值是以0作为结束,那么很多计算资源是被浪费的。但因为计算资源实际上总是有限的,一个有效的计算分布总是倾向于不加选择的去提升模型大小,甚至主要的客观目标是提升结果的性能。
来解决这两个问题的基础方法是在最后将全连接网络改成稀疏架构,甚至是在卷积内部。
- Architectural Details
Inception架构的主要创新点是关注如何在一个卷积网络中寻找一个稀疏的架构来和一个稠密的架构相匹配和对等。平移不变性意味着我们将需要从一个卷积模块中去构建网络。我们需要的是发现最优局部架构并且去重复这种架构。
GooLeNet网络层的细节如下表所示:
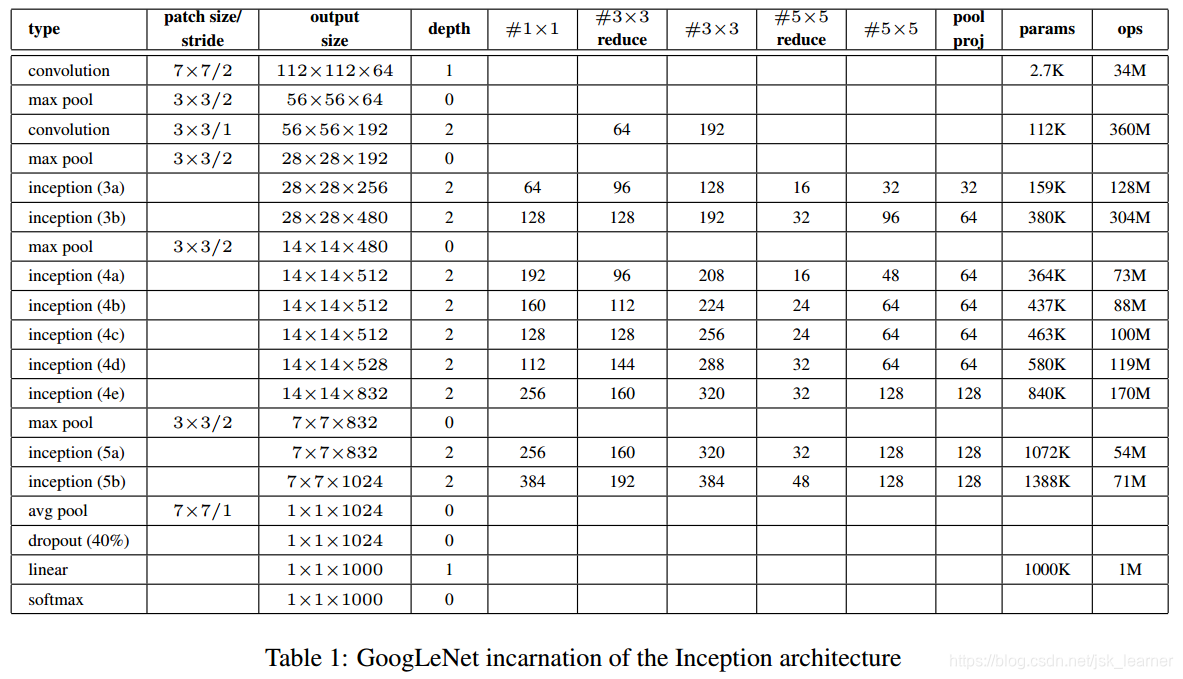
其在前面的一些分支上加入了一些softmax层去减轻深度网络的梯度消失问题。



总结:
- 128个1x1的卷积核用来维度降低和修正线性激活单元;
- 一个1024个单元的全连接层和修正线性激活单元;
- 一个以70%概率丢掉神经元连接的dropout层;
- 一个以softmax损失作为分类的线性层
- 预测1000个类别,但是在推理阶段被去除
- Training Methodology
动量设置为0.9,学习率设置为每8个epoch降低4%。
训练了7个模型,为了使问题更精细,一些模型在小的crop上训练,一些则在大的crop上训练。
使模型训练好的因素包括:
图像各种尺寸patch的采样,大小平均分布在8%到100%,长宽比例在3/4到4/3之间。
光照变化对于避免过拟合有作用
后期使用随机插值进行图像的resize。
- ILSVRC 2014 Classification Challenge Setup and Results
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 633
633




 到【灌水乐园】发言
到【灌水乐园】发言







