






一、什么是微调(fine-tuning)
1.为什么要微调(fine-tuning)
微调可以强化预训练模型在特定任务上的能力
-
特定领域能力增强:微调可以强化预训练模型在特定任务上的表现,例如情感分类,尽管预训练模型已有一定能力,但微调可进一步优化其效果。
-
学习新信息:微调可以让模型学习特定领域的新知识,如自我认知类问题(如“你是谁?”“你是谁创造的?”),确保其回答符合预期。
微调可以提高模型性能
-
减少幻觉:微调可降低模型生成虚假或不相关信息的概率,提高回答的可靠性。
-
提高一致性:尽管每次生成的内容不同,微调可确保输出质量稳定,避免结果参差不齐。
-
避免输出不必要信息:微调可使模型在敏感问题上适当拒答,增强安全性和合规性。
-
降低延迟:通过优化和使用较小参数模型,减少响应时间,提高运行效率。
微调自有模型可避免数据泄漏
-
本地或私有云部署:可在本地或虚拟私有云运行模型,增强自主控制。
-
防止数据泄漏:保护核心数据资产,避免外泄,保障企业竞争力。
-
安全风险可控:可自行设置高安全级别的微调与运行环境,而非依赖第三方服务。
使用微调模型,可降低成本
2.区分SFT和RLHF
后面有时间要来补回来
二、微调的原理
1.原理
微调是基于一个已经训练好的神经网络模型,通过对其参数进行细微调整,使其更好地适应特定的任务或数据。通过在新的小规模数据集上继续训练模型的部分或全部层,模型能够在保留原有知识的基础上,针对新任务进行优化,从而提升在特定领域的表现。
2.微调分类
1.全参微调:
-
从零训练成本高:大模型训练昂贵,但基于开源模型微调可降低门槛并取得良好效果。
-
降低请求成本:微调模型通常参数更少,能以更低成本实现相同性能。
-
更大控制权:可自主调整参数规模与资源分配,优化性能、耗时和成本。
更新所有的参数。
适用场景:适用于目标任务与预训练任务差异较大或需要最大化模型性能的场景
优点:能获得最佳性能
不足:
- 需要大量计算资源和存储空间
- 在数据较少的情况下容易导致过拟合
3.部分微调
仅更新模型的部分参数,其他参数保持冻结。
适用场景: 适合数据较少的任务
优点:
- 减少了计算和存储成本
- 降低了过拟合的风险
缺点:在任务复杂度较高时可能无法充分发挥模型的潜力
但是,由于现在的大模型的参数量都超级大,所以,就算微调也需要很大的计算资源,为了解决这个问题,提出了一个新的方法:参数高效微调(Parameter-Efficient Fine-Tuning, PEFT),参数高效微调,通过引入额外的低秩矩阵,如:LoRA或着是适配层如:Adpters。这样可以减少计算资源。下面讲解一下LoRA
4.LoRA
1.LoRA原理
LoRA:通过引入一个低秩矩阵来减少微调过程中需要更新的参数数量,来减少计算资源
LoRA的一个重要的特点:重用性,LoRA不改变模型原本的参数,只是学习到低秩矩阵,对不同的任务,我们可以训练得到不同的低秩矩阵,然后用低秩矩阵和我们的基座模型一起,来实现在特定任务上的好的表现。所以,我们可以重用我们的基座模型,就不用,为每个任务都单独复制一份基座模型,来去改变参数,这样可以减少资源的占用。
2.LoRA原理分析
我们的一个模型,通过在大量的数据上进行训练学习,然后能学到很多的东西和技能,但是在现实中有的情况下,我们不需要一些技能,而是只需要,其中的某些技能,所以,我们就想,那我们是不是在微调的时候,不调整和我们的任务需求不相关的参数,那么是不是就能减少计算资源。也就是说,我们只调整对我们需要的技能有影响的参数就行。
上面说了,LoRA的特点就是重用性,为了实现重用,就是我们单独拿一个矩阵和基座模型的参数矩阵相加,来实现对参数的改变,我们使用数学公式描述:(这个矩阵就是低秩矩阵)
![]()
进行图示:
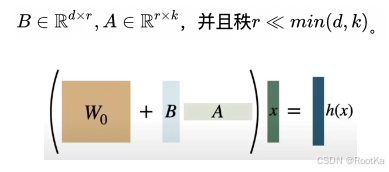
为什么是低秩矩阵,你想,如果,我们在拿一个和W0一样维度的矩阵的话,反而没有减少参数量,而是大大增加了参数量,LoRA就将这个矩阵表示低秩分解,如上面公式中的BA,那么,在后面学习更新参数的时候,只更新B和A矩阵的参数,这样看的话,要更新的参数明细少了很多。
低秩矩阵:是指秩较低的矩阵,即其线性独立行或列的数量较少。矩阵的秩表示该矩阵中最大线性独立行或列的个数。低秩矩阵通常具有一些压缩或简化的特性,能够用于数据降维、特征提取等任务。在许多应用中,通过将高秩矩阵近似为低秩矩阵,可以有效减少计算和存储的需求。
秩:如果矩阵的秩为
r,则矩阵最多只有r个线性独立的行或列。
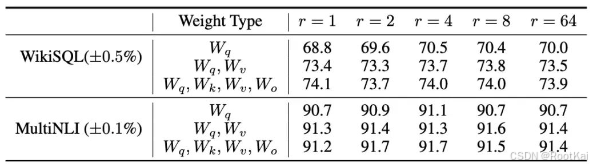
秩的选择:实际微调时很多情况使用的值就是4
适配 Wq 和 Wv时,只有1的秩就足够了,而仅训练Wq则需要更大的r
5.微调过程
1.准备数据:收集与目标任务相关的标注数据,将数据分为训练集、验证集,进行T
2.微调参数设:配置LoRA参数、微调参数如学习率,确保模型收敛。
3.微调模型:在训练集上训练模型,并调整超参数以防止过拟合。
4.评估模型:在验证集上评估模型性能。
特别注意的就是微调过程中使用的数据:
高质量:数据质量至关重要,低质量数据会导致低质量输出。
多样性:数据应覆盖多种场景,确保模型泛化能力强。
人工生成:尽量使用人工生成的文本,避免语言模型的固有模式。
数量适中:数据量不宜过少,100条开始见效,1000条效果更佳。
数据量:建议是从 50 条开始,有明显效果逐步增加数量。
6.案例分析:
使用LoRA微调代码:
目的:使用 LoRA 微调了一个 67M 的 Bert的蒸馏模型,实现对电影的评论进行分类的功能,用于是正面还是负面的评论
数据:数据的结构为:一段评论 正负面的标签(0,1)
代码实现:
基本包引入
from datasets import load_dataset, DatasetDict, Dataset
from transformers import (
AutoTokenizer,
AutoConfig,
AutoModelForSequenceClassification,
DataCollatorWithPadding,
TrainingArguments,
Trainer)
from peft import PeftModel, PeftConfig, get_peft_model, LoraConfig
import evaluate
import torch
import numpy as np微调数据构造
这一步的目的就是从数据集中加载数据,并构造出我们需要的数据组成格式
#加载 IMDB 数据集
imdb_dataset = load_dataset("stanfordnlp/imdb")
#生成随机索引,抽取 1000 条样本
N = 1000
rand_idx = np.random.randint(25000, size=N)
"""
N = 1000:定义抽样数量(1000)。
np.random.randint(24999, size=N):随机生成 1000 个在 [0, 24999] 之间的整数索引,用于从数据集中抽取样本。
"""
#使用随机索引提取训练和测试数据
x_train = imdb_dataset['train'][rand_idx]['text']
y_train = imdb_dataset['train'][rand_idx]['label']
x_test = imdb_dataset['test'][rand_idx]['text']
y_test = imdb_dataset['test'][rand_idx]['label']
"""
这个数据集包含了训练和测试集
"""
#创建新的数据集
dataset = DatasetDict({
'train': Dataset.from_dict({'label': y_train, 'text': x_train}),
'validation': Dataset.from_dict({'label': y_test, 'text': x_test})
})
"""
通过 DatasetDict 创建新的数据集:
train:包含 1000 条随机抽样的训练数据(文本和标签)。
validation:包含 1000 条随机抽样的测试数据(文本和标签)。
"""
# 计算训练集中正样本的比例
np.array(dataset['train']['label']).sum() / len(dataset['train']['label'])
"""
dataset['train']['label'] 提取所有训练样本的标签(0 或 1)。
np.array(...).sum() 计算 1 的数量(即正样本数量)。
除以 len(dataset['train']['label']) 计算 正样本占比。
"""
加载初始模型
#加载模型
model = AutoModelForSequenceClassification.from_pretrained(
model_checkpoint, num_labels=2, id2label=id2label, label2id=label2id
)
"""
model_checkpoint 指定要加载的模型(如 distilbert-base-uncased)。
num_labels=2 指定该任务有 两个类别(0=负面,1=正面)。
id2label=id2label 和 label2id=label2id 设置类别名称映射,方便模型输出可读的结果。
"""tokenize 与 pad 预处理
# 加载分词器
tokenizer = AutoTokenizer.from_pretrained(model_checkpoint, add_prefix_space=True)
# 如果没有 pad_token(填充字符),则添加
if tokenizer.pad_token is None:
tokenizer.add_special_tokens({'pad_token': '[PAD]'})
# 定义 tokenization 函数
def tokenize_function(examples):
text = examples["text"]
tokenizer.truncation_side = "left"
tokenized_inputs = tokenizer(
text,
return_tensors=None,
truncation=True,
max_length=512,
padding="max_length",
)
return tokenized_inputs
"""
examples["text"] 提取数据集中 "text" 字段的文本数据。
tokenizer.truncation_side = "left" 设置截断方向为左侧(默认是右侧截断)。
tokenizer(...) 进行分词:
return_tensors=None 让返回值是 Python 字典,而不是 Tensor。
truncation=True 开启截断,防止超出 max_length。
max_length=512 限制最大 token 长度(BERT 的最大输入长度)。
padding="max_length" 让所有样本填充到 512 长度,确保 batch 统一。
"""
#对数据集进行 Tokenization
tokenized_dataset = dataset.map(tokenize_function, batched=True)
"""
dataset.map(...) 逐条应用 tokenize_function,将原始文本转换为 token ID。
batched=True 表示批量处理,加速数据处理。
"""
#创建数据整理器(Data Collator)
data_collator = DataCollatorWithPadding(tokenizer=tokenizer)
"""
DataCollatorWithPadding 是 Hugging Face 提供的数据整理器,会自动对 batch 内的数据进行动态填充,使它们具有相同长度,避免 padding="max_length" 带来的不必要计算开销。
"""
#最终 tokenized_dataset
"""
tokenized_dataset 是一个已经分词后的 Hugging Face Dataset,它的每个样本包含:
input_ids: 词的 ID 序列。
attention_mask: 用于指示 padding 部分(0 表示 padding,1 表示真实 token)。
token_type_ids(如果 BERT 需要): 句子分隔信息。
"""说明:
数字化表示,与模型对齐:语言模型无法直接理解原始的文本数据。这些模型处理的对象是数字化的表示形式,Tokenize 的过程将文本转化为模型可以处理的整数序列,这些整数对应于词汇表中的特定单词或子词。不同模型使用不同的 Tokenize 方式,这也要求微调的时候,需要与模型中的一致。
2.减少词汇量:Tokenize 过程根据词汇表将文本切分为模型可识别的最小单位(如单词、子词、字符)。这不仅减少了词汇量,降低了模型的复杂性,还提高了模型处理罕见词或新词的能力。
3.并行计算需要:通过 tokenization,可以将输入文本统一为模型预期的固定长度。对于较长的文本,Tokenize 过程可以将其截断;对于较短的文本,可以通过填充(padding)来补足长度。这样模型输入具有一致性,便于并行计算。
微调配置
#评估(Evaluation)
import evaluate # 导入 evaluate 模块
"""
evaluate 是 Hugging Face 提供的评估工具库,用于加载不同的评价指标,如 accuracy、F1-score、BLEU 等。
"""
# 加载 accuracy 评估指标
accuracy = evaluate.load("accuracy")
"""
evaluate.load("accuracy") 加载准确率(Accuracy) 评估指标。
之后可以使用 accuracy.compute() 来计算准确率。
"""
#定义 compute_metrics 评估函数
def compute_metrics(p):
predictions, labels = p
predictions = np.argmax(predictions, axis=1)
return {"accuracy": accuracy.compute(predictions=predictions, references=labels)}
"""
这个函数用于计算模型预测的准确率,通常在 Hugging Face 的 Trainer 训练过程中使用。
参数 p:包含两个值:
predictions:模型的输出 logits(即未经 softmax 归一化的分数)。
labels:真实标签。
处理步骤:
np.argmax(predictions, axis=1):获取 predictions 的最大值索引(即预测的类别)。
accuracy.compute(predictions=predictions, references=labels) 计算准确率,返回 {"accuracy": 计算结果}。
"""LoRA(Low-Rank Adaptation)配置
from peft import LoraConfig, get_peft_model # 导入 PEFT 相关函数
"""
peft(Parameter-Efficient Fine-Tuning)是 Hugging Face 提供的高效参数微调工具,适用于大语言模型(LLM)。
LoraConfig 用于配置 LoRA 训练超参数。
get_peft_model 用于将 LoRA 配置应用到已有的预训练模型。
"""
peft_config = LoraConfig(
task_type="SEQ_CLS", # 任务类型:序列分类(Sequence Classification)
r=1, # 降维秩(rank),通常 8~64,越大表示 LoRA 需要的参数越多
lora_alpha=32, # LoRA scaling factor,调整学习率放大系数
lora_dropout=0.01, # LoRA dropout,防止过拟合
target_modules=['q_lin'] # 指定微调的 Transformer 模块
)
"""
task_type="SEQ_CLS":表示这个 LoRA 配置用于 序列分类任务(如情感分类、文本分类)。
r=1:
r 表示 LoRA 分解矩阵的秩(rank)。
r=1 表示降维程度很大,只需要少量可训练参数。
一般建议 r=8 或 r=16,r=1 可能效果不佳。
lora_alpha=32:
这个参数控制 LoRA 模块的缩放因子(scaling factor)。
LoRA 的实际学习率 ≈ base_lr * (lora_alpha / r),即 lora_alpha 越大,相当于放大了 LoRA 层的学习率。
lora_dropout=0.01:
防止过拟合,0.01 表示 1% 的神经元会被随机丢弃。
target_modules=['q_lin']:
指定 LoRA 适用的 Transformer 层,例如 query 线性层(q_lin)。
LoRA 只会对 target_modules 中指定的层进行微调,其余层保持冻结状态。
在 BERT 类模型中,target_modules 可能包括:
query(q_lin)
key(k_lin)
value(v_lin)
"""使用 Hugging Face
transformers库 配合 Trainer API 来进行模型训练。它配置了训练参数并创建了训练过程,最后开始训练模型。
#定义超参数(Hyperparameters)
lr = 1e-3 # 学习率(learning rate)
batch_size = 4 # 批次大小(batch size)
num_epochs = 10 # 训练轮数(number of epochs)
"""
lr = 1e-3:学习率设置为 0.001,控制模型在每次更新时步伐的大小。
batch_size = 4:每次训练时使用 4 个样本。
num_epochs = 10:训练模型 10 个轮次(遍历整个训练数据集 10 次)。
"""
#定义训练参数(Training Arguments)
from transformers import TrainingArguments # 导入 TrainingArguments
training_args = TrainingArguments(
output_dir=model_checkpoint + "-lora-text-classification", # 输出目录,用于保存模型和日志
learning_rate=lr, # 设置学习率
per_device_train_batch_size=batch_size, # 每个设备上的训练批次大小
per_device_eval_batch_size=batch_size, # 每个设备上的验证批次大小
num_train_epochs=num_epochs, # 训练轮数
weight_decay=0.01, # 权重衰减,用于防止过拟合
evaluation_strategy="epoch", # 每个轮次结束时进行评估
save_strategy="epoch", # 每个轮次结束时保存模型
load_best_model_at_end=True, # 训练结束后加载最好的模型(基于评估指标)
)
"""
output_dir:训练过程中的输出目录,这里将模型保存为以 model_checkpoint + "-lora-text-classification" 为目录名。
learning_rate:设置学习率。
per_device_train_batch_size 和 per_device_eval_batch_size:分别设置训练和验证时的批次大小。
num_train_epochs:设置训练的总轮数(epochs)。
weight_decay:用于正则化的权重衰减项(0.01),它有助于防止模型过拟合。
evaluation_strategy="epoch":每轮结束后进行一次评估。
save_strategy="epoch":每轮结束时保存一次模型。
load_best_model_at_end=True:训练结束后,自动加载在验证集上表现最好的模型。
"""
创建 Trainer 对象
from transformers import Trainer # 导入 Trainer
# 创建 Trainer 对象
trainer = Trainer(
model=model, # 预训练模型或微调后的模型
args=training_args, # 训练参数
train_dataset=tokenized_dataset["train"], # 训练数据集
eval_dataset=tokenized_dataset["validation"], # 验证数据集
tokenizer=tokenizer, # 分词器
data_collator=data_collator, # 数据整理器(用于批量动态填充)
compute_metrics=compute_metrics, # 用于计算评估指标的函数
)
"""
model:模型是经过 LoRA 微调后的模型,通常是一个从 Hugging Face 预训练模型加载的文本分类模型。
args=training_args:使用之前定义的训练参数。
train_dataset 和 eval_dataset:训练集和验证集,分别来自 tokenized_dataset["train"] 和 tokenized_dataset["validation"]。
tokenizer:用来处理输入文本并将其转换为模型可以理解的格式。
data_collator:数据整理器,用于动态填充每个批次中的样本到相同的长度。这对于变长的序列很重要。
compute_metrics:评估函数,用于计算模型的评估指标(如准确率 accuracy)。
"""

















 215
215

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









