






1、由于实现了暂态程序中电压初始化的求解,想看看占用板卡资源就尝试综合了以下程序,于是看到了报表后一头雾水。
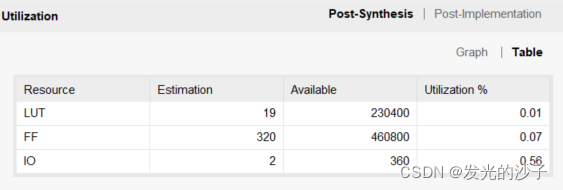
LUT指的是查找表,FF指的是触发器(可以存储1bit的数据)。看了上图我们知道FF占用很多,但实际的资源也很大(但是将来可能需要解决两块板子的级联问题)。
相关属于请参考这篇文章,写的很是详细:
Vivado HLS 三:基本概念(lut、latch、ff、RAM、ROM、FIFO等)_不缺席的阳光的博客-优快云博客_vivado中lut
2、元旦一过,VHLS惊现逆天BUG,不能生成IP核了!于是我去了社区一搜发现,是程序的时间计数器溢出了.....最简单的解决方案是:在生成IP之前,修改系统时间,比如修改到2021年。。。再点击生成就好了。
 https://support.xilinx.com/s/question/0D52E00006uzEJMSA2/vivado-hls20183%E5%AF%BC%E5%87%BArtl%E9%94%99%E8%AF%AF%E9%94%99%E8%AF%AF%E4%BB%A3%E7%A0%81impl-21328?language=zh_CN
https://support.xilinx.com/s/question/0D52E00006uzEJMSA2/vivado-hls20183%E5%AF%BC%E5%87%BArtl%E9%94%99%E8%AF%AF%E9%94%99%E8%AF%AF%E4%BB%A3%E7%A0%81impl-21328?language=zh_CN3、Verilog矩阵求解 (全网唯一浮点数矩阵并行计算)
实验任务:实现A=3*3,B=3*1的全单精度浮点数矩阵计算
实验软硬件:ZCU106、Vivado 2019.1
实验过程:
①建立项目,并添加乘法与加法IP核,如下:
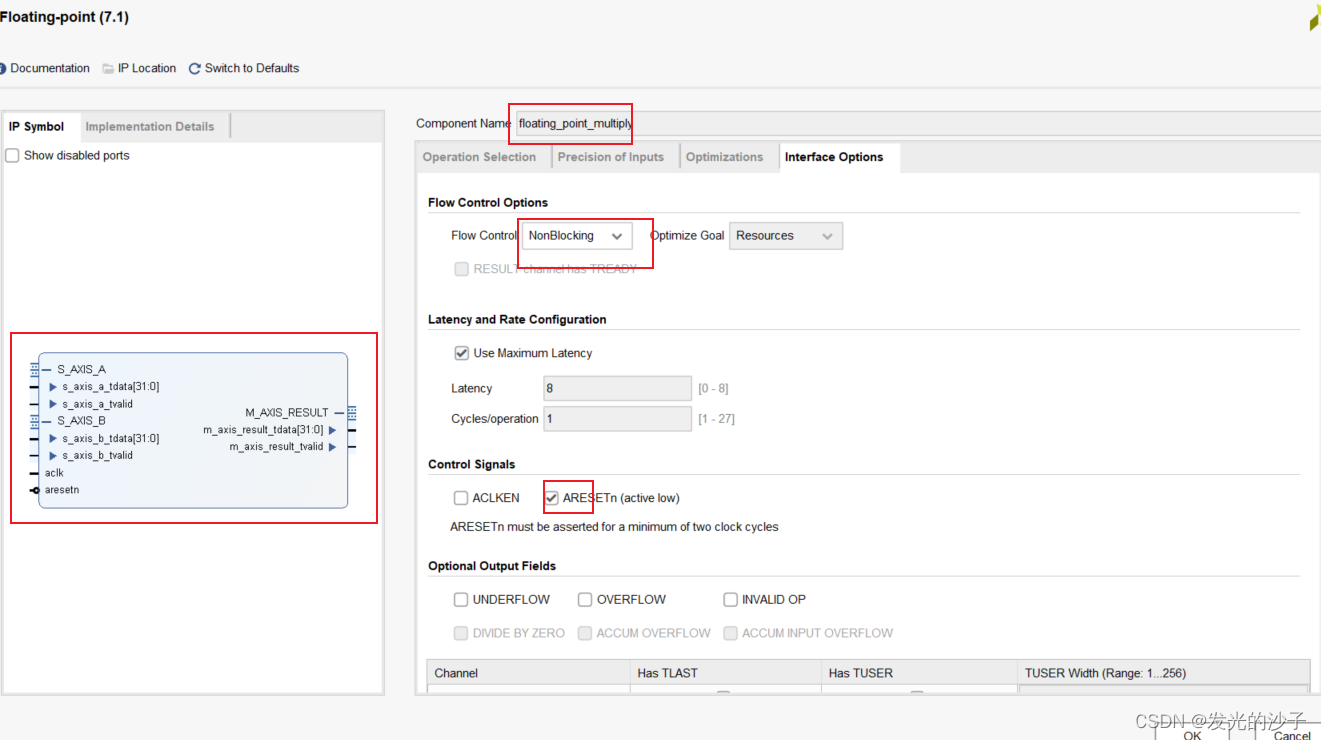
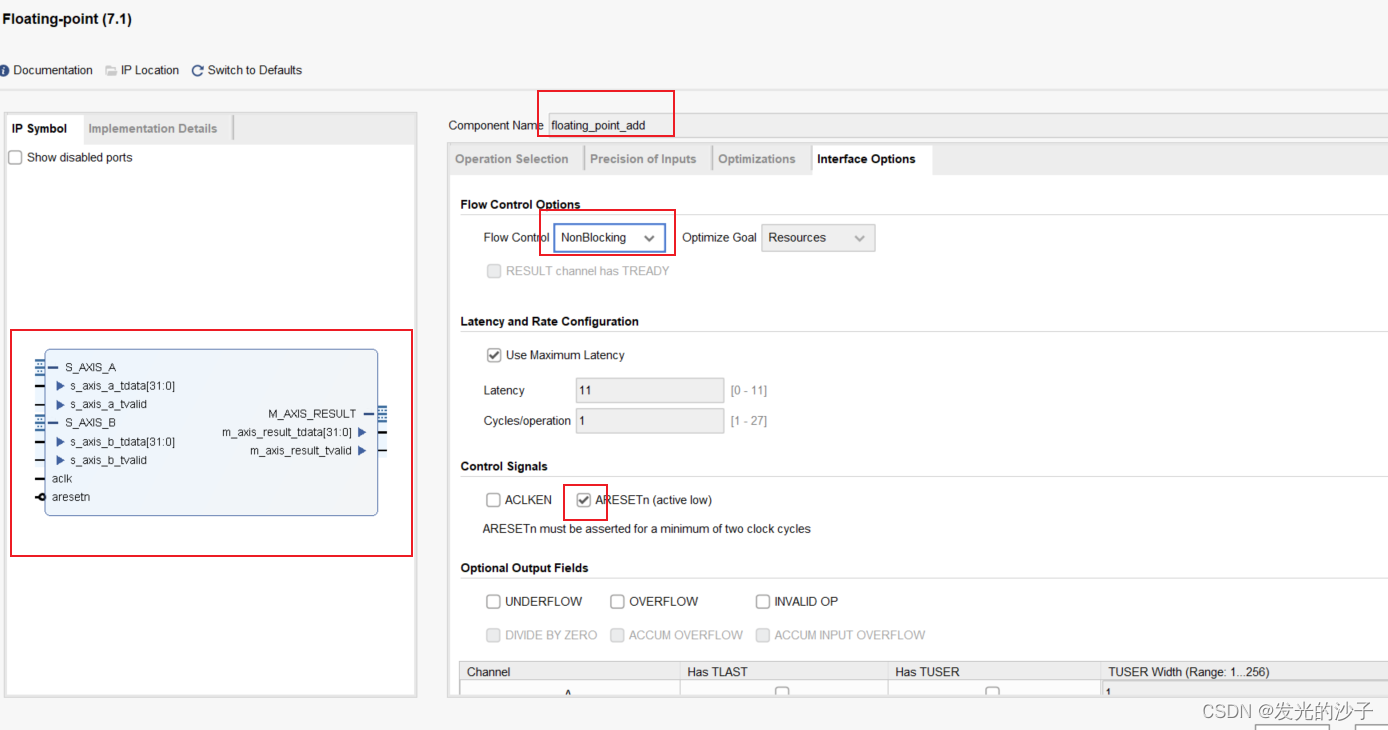
②新建top.v文件,并复制如下代码
`timescale 1ns / 1ps
//
// Company: 东北电力大学
// Engineer: Yang Zheng
//
// Create Date: 2022/01/04 21:29:15
// Design Name:
// Module Name: matrix_multiply_33_31
// Project Name:
// Target Devices:
// Tool Versions:
// Description:
// Floating-matrix-multiply,matrix dim 3*3_3*1=3*1
// needs 63 clk
// Dependencies:
//
// Revision:
// Revision 0.01 - File Created
// Additional Comments:
//
//
module matrix_multiply_33_31
#(parameter M = 3,// matrix dimension M x N, also vector dimension
N = 3,// matrix dimension M x N, also vector dimension
DW = 32
)
(
input [(DW * N * M) - 1 : 0] matrix_input,
input [(DW * M) - 1 : 0] vector_input,
output [(DW * N * M) - 1 : 0] vector_output,
input clk,
input rst,
input matrix_input_valid,
output vector_output_valid,
output vector_en_valid
);
reg matrix_reshape = 1'b0;
reg [31:0] A[2:0][2:0];
reg [31:0] B[2:0];
reg [31:0] C[2:0];
reg vector_output_valid_r = 1'b0;
reg vector_en_valid_r = 1'b1;
assign vector_output_valid = vector_output_valid_r;
assign vector_output = {C[0],C[1],C[2]};
assign vector_en_valid = vector_en_valid_r;
always @(posedge clk or negedge rst) begin
if (!rst) begin
//复位
matrix_reshape <= 1'b0;
{A[0][0],A[0][1],A[0][2],
A[1][0],A[1][1],A[1][2],
A[2][0],A[2][1],A[2][2]} <= 'd0;
{B[0],
B[1],
B[2]} <= 'd0;
{C[0],
C[1],
C[2]} <= 'd0;
end
else begin
if (matrix_reshape == 1'b0 && matrix_input_valid == 1'b1) begin
{A[0][0],A[0][1],A[0][2],
A[1][0],A[1][1],A[1][2],
A[2][0],A[2][1],A[2][2]} <= matrix_input;
{B[0],
B[1],
B[2]} <= vector_input;
{C[0],
C[1],
C[2]} <= 'd0;
matrix_reshape <= 1'b1;
end
end
end
reg s_axis_a_tvalid_0_0 = 1'b0;
reg s_axis_b_tvalid_0_0 = 1'b0;
reg [31:0] s_axis_a_tdata_0_0 = 32'b0;
reg [31:0] s_axis_b_tdata_0_0 = 32'b0;
wire [31:0] m_axis_result_tdata_0_0;
reg aresetn_multiply = 1'b0;
always @(negedge rst) begin
if (!rst) begin
aresetn_multiply <= 1'b1;
end
end
floating_point_multiply uut_floating_point_multiply_0_0(
.aclk(clk),
.aresetn(aresetn_multiply),//低电平复位
.s_axis_a_tvalid(s_axis_a_tvalid_0_0),
.s_axis_a_tdata(s_axis_a_tdata_0_0),
.s_axis_b_tvalid(s_axis_b_tvalid_0_0),
.s_axis_b_tdata(s_axis_b_tdata_0_0),
.m_axis_result_tvalid(m_axis_result_tvalid_0_0),
.m_axis_result_tdata(m_axis_result_tdata_0_0)
);
reg s_axis_a_tvalid_0_1 = 1'b0;
reg s_axis_b_tvalid_0_1 = 1'b0;
reg [31:0] s_axis_a_tdata_0_1 = 32'b0;
reg [31:0] s_axis_b_tdata_0_1 = 32'b0;
wire [31:0] m_axis_result_tdata_0_1;
floating_point_multiply uut_floating_point_multiply_0_1(
.aclk(clk),
.aresetn(aresetn_multiply),
.s_axis_a_tvalid(s_axis_a_tvalid_0_1),
.s_axis_a_tdata(s_axis_a_tdata_0_1),
.s_axis_b_tvalid(s_axis_b_tvalid_0_1),
.s_axis_b_tdata(s_axis_b_tdata_0_1),
.m_axis_result_tvalid(m_axis_result_tvalid_0_1),
.m_axis_result_tdata(m_axis_result_tdata_0_1)
);
reg s_axis_a_tvalid_1_0 = 1'b0;
reg s_axis_b_tvalid_1_0 = 1'b0;
reg [31:0] s_axis_a_tdata_1_0 = 32'b0;
reg [31:0] s_axis_b_tdata_1_0 = 32'b0;
wire [31:0] m_axis_result_tdata_1_0;
floating_point_multiply uut_floating_point_multiply_1_0(
.aclk(clk),
.aresetn(aresetn_multiply),
.s_axis_a_tvalid(s_axis_a_tvalid_1_0),
.s_axis_a_tdata(s_axis_a_tdata_1_0),
.s_axis_b_tvalid(s_axis_b_tvalid_1_0),
.s_axis_b_tdata(s_axis_b_tdata_1_0),
.m_axis_result_tvalid(m_axis_result_tvalid_1_0),
.m_axis_result_tdata(m_axis_result_tdata_1_0)
);
reg s_axis_a_tvalid_1_1 = 1'b0;
reg s_axis_b_tvalid_1_1 = 1'b0;
reg [31:0] s_axis_a_tdata_1_1 = 32'b0;
reg [31:0] s_axis_b_tdata_1_1 = 32'b0;
wire [31:0] m_axis_result_tdata_1_1;
floating_point_multiply uut_floating_point_multiply_1_1(
.aclk(clk),
.aresetn(aresetn_multiply),
.s_axis_a_tvalid(s_axis_a_tvalid_1_1),
.s_axis_a_tdata(s_axis_a_tdata_1_1),
.s_axis_b_tvalid(s_axis_b_tvalid_1_1),
.s_axis_b_tdata(s_axis_b_tdata_1_1),
.m_axis_result_tvalid(m_axis_result_tvalid_1_1),
.m_axis_result_tdata(m_axis_result_tdata_1_1)
);
reg s_axis_a_tvalid_2_0 = 1'b0;
reg s_axis_b_tvalid_2_0 = 1'b0;
reg [31:0] s_axis_a_tdata_2_0 = 32'b0;
reg [31:0] s_axis_b_tdata_2_0 = 32'b0;
wire [31:0] m_axis_result_tdata_2_0;
floating_point_multiply uut_floating_point_multiply_2_0(
.aclk(clk),
.aresetn(aresetn_multiply),
.s_axis_a_tvalid(s_axis_a_tvalid_2_0),
.s_axis_a_tdata(s_axis_a_tdata_2_0),
.s_axis_b_tvalid(s_axis_b_tvalid_2_0),
.s_axis_b_tdata(s_axis_b_tdata_2_0),
.m_axis_result_tvalid(m_axis_result_tvalid_2_0),
.m_axis_result_tdata(m_axis_result_tdata_2_0)
);
reg s_axis_a_tvalid_2_1 = 1'b0;
reg s_axis_b_tvalid_2_1 = 1'b0;
reg [31:0] s_axis_a_tdata_2_1 = 32'b0;
reg [31:0] s_axis_b_tdata_2_1 = 32'b0;
wire [31:0] m_axis_result_tdata_2_1;
floating_point_multiply uut_floating_point_multiply_2_1(
.aclk(clk),
.aresetn(aresetn_multiply),
.s_axis_a_tvalid(s_axis_a_tvalid_2_1),
.s_axis_a_tdata(s_axis_a_tdata_2_1),
.s_axis_b_tvalid(s_axis_b_tvalid_2_1),
.s_axis_b_tdata(s_axis_b_tdata_2_1),
.m_axis_result_tvalid(m_axis_result_tvalid_2_1),
.m_axis_result_tdata(m_axis_result_tdata_2_1)
);
reg aresetn_add = 1'b0;
always @(negedge rst) begin
if (!rst) begin
aresetn_add <= 1'b1;
end
end
reg s_axis_a_tvalid_add_0 = 1'b0;
reg s_axis_b_tvalid_add_0 = 1'b0;
reg [31:0] s_axis_a_tdata_add_0 = 32'b0;
reg [31:0] s_axis_b_tdata_add_0 = 32'b0;
wire [31:0] m_axis_result_tdata_add_0;
reg [31:0] m_axis_result_tdata_add_0_r = 32'b0;
floating_point_add uut_floating_point_add_0(
.aclk(clk),
.aresetn(aresetn_add),
.s_axis_a_tvalid(s_axis_a_tvalid_add_0),
.s_axis_a_tdata(s_axis_a_tdata_add_0),
.s_axis_b_tvalid(s_axis_b_tvalid_add_0),
.s_axis_b_tdata(s_axis_b_tdata_add_0),
.m_axis_result_tvalid(m_axis_result_tvalid_add_0),
.m_axis_result_tdata(m_axis_result_tdata_add_0)
);
reg s_axis_a_tvalid_add_1 = 1'b0;
reg s_axis_b_tvalid_add_1 = 1'b0;
reg [31:0] s_axis_a_tdata_add_1 = 32'b0;
reg [31:0] s_axis_b_tdata_add_1 = 32'b0;
wire [31:0] m_axis_result_tdata_add_1;
reg [31:0] m_axis_result_tdata_add_1_r = 32'b0;
floating_point_add uut_floating_point_add_1(
.aclk(clk),
.aresetn(aresetn_add),
.s_axis_a_tvalid(s_axis_a_tvalid_add_1),
.s_axis_a_tdata(s_axis_a_tdata_add_1),
.s_axis_b_tvalid(s_axis_b_tvalid_add_1),
.s_axis_b_tdata(s_axis_b_tdata_add_1),
.m_axis_result_tvalid(m_axis_result_tvalid_add_1),
.m_axis_result_tdata(m_axis_result_tdata_add_1)
);
reg s_axis_a_tvalid_add_2 = 1'b0;
reg s_axis_b_tvalid_add_2 = 1'b0;
reg [31:0] s_axis_a_tdata_add_2 = 32'b0;
reg [31:0] s_axis_b_tdata_add_2 = 32'b0;
wire [31:0] m_axis_result_tdata_add_2;
reg [31:0] m_axis_result_tdata_add_2_r = 32'b0;
floating_point_add uut_floating_point_add_2(
.aclk(clk),
.aresetn(aresetn_add),
.s_axis_a_tvalid(s_axis_a_tvalid_add_2),
.s_axis_a_tdata(s_axis_a_tdata_add_2),
.s_axis_b_tvalid(s_axis_b_tvalid_add_2),
.s_axis_b_tdata(s_axis_b_tdata_add_2),
.m_axis_result_tvalid(m_axis_result_tvalid_add_2),
.m_axis_result_tdata(m_axis_result_tdata_add_2)
);
//状态机
parameter IDLE = 3'd0;
parameter ST1 = 3'd1;
parameter ST2 = 3'd2;
parameter ST3 = 3'd3;
reg [1:0] st_next = 'd0;
reg [1:0] st_cur = 'd0;
always @(posedge clk or negedge rst) begin
if (!clk) begin
//复位
st_cur <= 'd0;
end
else begin
if (matrix_input_valid) begin
st_cur <= st_next;
end
end
end
reg ST1_valid = 1'b0;
reg ST2_valid = 1'b0;
reg ST3_valid = 1'b0;
reg [2:0] aresetn_count = 3'b0;
always @(posedge clk) begin
case (st_cur)
IDLE:
if (matrix_input_valid) begin
st_next <= ST1;
vector_en_valid_r <= 1'b0;
end
ST1:
if (ST1_valid) begin
/*对乘法器复位*/
aresetn_multiply <= 1'b0;
aresetn_count <= aresetn_count + 1'b1;
if (aresetn_count == 'd3) begin
aresetn_count <= 1'b0;
st_next <= ST2;
aresetn_multiply <= 1'b1;
ST1_valid <= 1'b0;
end
end
ST2:
if (ST2_valid) begin
/*对加法器复位*/
aresetn_add <= 1'b0;
aresetn_count <= aresetn_count + 1'b1;
if (aresetn_count == 'd3) begin
aresetn_count <= 1'b0;
st_next <= ST3;
aresetn_add <= 1'b1;
ST2_valid <= 1'b0;
end
end
ST3:
if (ST3_valid) begin
s_axis_a_tvalid_add_0 <= 1'b0;
s_axis_b_tvalid_add_0 <= 1'b0;
s_axis_a_tvalid_add_1 <= 1'b0;
s_axis_b_tvalid_add_1 <= 1'b0;
s_axis_a_tvalid_add_2 <= 1'b0;
s_axis_b_tvalid_add_2 <= 1'b0;
C[0] <= m_axis_result_tdata_add_0;
C[1] <= m_axis_result_tdata_add_1;
C[2] <= m_axis_result_tdata_add_2;
vector_output_valid_r <= 1'b1;
/*对加法器复位*/
aresetn_add <= 1'b0;
aresetn_count <= aresetn_count + 1'b1;
if (aresetn_count == 'd3) begin
aresetn_count <= 1'b0;
st_next <= IDLE;
aresetn_add <= 1'b1;
ST3_valid <= 1'b0;
vector_en_valid_r <= 1'b1;
end
end
default: st_next <= IDLE;
endcase
end
always @(posedge clk or negedge rst) begin
if (!rst) begin
//复位
end
else begin
if (st_cur == ST1) begin
//第一行
s_axis_a_tvalid_0_0 <= 1'b1;
s_axis_b_tvalid_0_0 <= 1'b1;
s_axis_a_tdata_0_0 <= A[0][0];
s_axis_b_tdata_0_0 <= B[0];
s_axis_a_tvalid_0_1 <= 1'b1;
s_axis_b_tvalid_0_1 <= 1'b1;
s_axis_a_tdata_0_1 <= A[0][1];
s_axis_b_tdata_0_1 <= B[1];
//第二行
s_axis_a_tvalid_1_0 <= 1'b1;
s_axis_b_tvalid_1_0 <= 1'b1;
s_axis_a_tdata_1_0 <= A[1][0];
s_axis_b_tdata_1_0 <= B[0];
s_axis_a_tvalid_1_1 <= 1'b1;
s_axis_b_tvalid_1_1 <= 1'b1;
s_axis_a_tdata_1_1 <= A[1][1];
s_axis_b_tdata_1_1 <= B[1];
//第三行
s_axis_a_tvalid_2_0 <= 1'b1;
s_axis_b_tvalid_2_0 <= 1'b1;
s_axis_a_tdata_2_0 <= A[2][0];
s_axis_b_tdata_2_0 <= B[0];
s_axis_a_tvalid_2_1 <= 1'b1;
s_axis_b_tvalid_2_1 <= 1'b1;
s_axis_a_tdata_2_1 <= A[2][1];
s_axis_b_tdata_2_1 <= B[1];
end
else if(st_cur == ST2) begin
s_axis_a_tvalid_0_0 <= 1'b0;
s_axis_b_tvalid_0_0 <= 1'b0;
s_axis_a_tdata_0_1 <= A[0][2];
s_axis_b_tdata_0_1 <= B[2];
s_axis_a_tvalid_1_0 <= 1'b0;
s_axis_b_tvalid_1_0 <= 1'b0;
s_axis_a_tdata_1_1 <= A[1][2];
s_axis_b_tdata_1_1 <= B[2];
s_axis_a_tvalid_2_0 <= 1'b0;
s_axis_b_tvalid_2_0 <= 1'b0;
s_axis_a_tdata_2_1 <= A[2][2];
s_axis_b_tdata_2_1 <= B[2];
//因为是非阻塞赋值,所以可以利用输出计算加法
s_axis_a_tvalid_add_0 <= 1'b1;
s_axis_b_tvalid_add_0 <= 1'b1;
s_axis_a_tvalid_add_1 <= 1'b1;
s_axis_b_tvalid_add_1 <= 1'b1;
s_axis_a_tvalid_add_2 <= 1'b1;
s_axis_b_tvalid_add_2 <= 1'b1;
s_axis_a_tdata_add_0 <= m_axis_result_tdata_0_0;
s_axis_b_tdata_add_0 <= m_axis_result_tdata_0_1;
s_axis_a_tdata_add_1 <= m_axis_result_tdata_1_0;
s_axis_b_tdata_add_1 <= m_axis_result_tdata_1_1;
s_axis_a_tdata_add_2 <= m_axis_result_tdata_2_0;
s_axis_b_tdata_add_2 <= m_axis_result_tdata_2_1;
end
else if(st_cur == ST3) begin
s_axis_a_tvalid_0_1 <= 1'b0;
s_axis_b_tvalid_0_1 <= 1'b0;
s_axis_a_tvalid_1_1 <= 1'b0;
s_axis_b_tvalid_1_1 <= 1'b0;
s_axis_a_tvalid_2_1 <= 1'b0;
s_axis_b_tvalid_2_1 <= 1'b0;
//计算加法
s_axis_a_tdata_add_0 <= m_axis_result_tdata_add_0_r;
s_axis_b_tdata_add_0 <= m_axis_result_tdata_0_1;
s_axis_a_tdata_add_1 <= m_axis_result_tdata_add_1_r;
s_axis_b_tdata_add_1 <= m_axis_result_tdata_1_1;
s_axis_a_tdata_add_2 <= m_axis_result_tdata_add_2_r;
s_axis_b_tdata_add_2 <= m_axis_result_tdata_2_1;
end
end
end
//状态机输出
always @(posedge clk or negedge rst) begin
if (!rst) begin
//复位
end
else begin
if (st_cur == ST1 && m_axis_result_tvalid_0_0 == 1'b1&& m_axis_result_tvalid_0_1 == 1'b1
&& m_axis_result_tvalid_1_0 == 1'b1 && m_axis_result_tvalid_1_1 == 1'b1
&& m_axis_result_tvalid_2_0 == 1'b1 && m_axis_result_tvalid_2_1 == 1'b1
) begin
ST1_valid <= 1'b1;
end
else if(st_cur == ST2 && m_axis_result_tvalid_0_1 == 1'b1 && m_axis_result_tvalid_add_0 == 1'b1
&& m_axis_result_tvalid_1_1 == 1'b1 && m_axis_result_tvalid_add_1 == 1'b1
&& m_axis_result_tvalid_2_1 == 1'b1 && m_axis_result_tvalid_add_2 == 1'b1
) begin
m_axis_result_tdata_add_0_r <= m_axis_result_tdata_add_0;
m_axis_result_tdata_add_1_r <= m_axis_result_tdata_add_1;
m_axis_result_tdata_add_2_r <= m_axis_result_tdata_add_2;
ST2_valid <= 1'b1;
end
else if(st_cur == ST3 && m_axis_result_tvalid_add_0 == 1'b1
&& m_axis_result_tvalid_add_1 == 1'b1
&& m_axis_result_tvalid_add_2 == 1'b1 ) begin
ST3_valid <= 1'b1;
end
end
end
//vector_output_valid_r 产生2个周期的高电平信号
reg [1:0] vector_output_valid_r_count = 2'b0;
always @(posedge clk or negedge rst) begin
if (!rst) begin
vector_output_valid_r_count <= 2'b0;
end
else begin
if (vector_output_valid_r) begin
vector_output_valid_r_count <= vector_output_valid_r_count + 1'b1;
if (vector_output_valid_r_count == 'd2) begin
vector_output_valid_r <= 1'b0;
vector_output_valid_r_count <= 2'b0;
end
end
end
end
endmodule
③testbench就不给出了,学到现在还不会就别学了,回去再好好复习一下。下面只给出调用代码:
if (vector_en_valid) begin
matrix_input_valid <= 1'b1;
matrix_input <= {32'h3F800000,32'h40000000,32'h40400000,
32'h40800000,32'h40A00000,32'h40C00000,
32'h40E00000,32'h41000000,32'h41100000};
//vector_input <= {m_axis_result_tdata_a,m_axis_result_tdata_b,m_axis_result_tdata_c};
vector_input <= {32'h3F800000,32'h40000000,32'h40400000};
end这个实现的是
④调用结果:
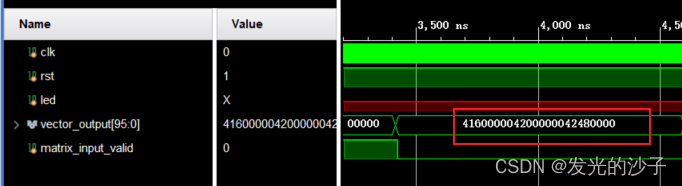
96位拆分为3个数后分别对应:4160_0000=14,4200_0000=32,4248_0000 =50



















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











