







概念
1.定义:
队列是一种 先进先出(FIFO) 的数据结构,但有些情况下,操作的数据可能带有优先级,一般出队列时,可能需要优先级高的元素先出队列,该中场景下,使用队列显然不合适,在这种情况下,我们的数据结构应该提供两个最基本的操作,一个是返回最高优先级对象,一个是添加新的对象。这种数据结构就是优先级队列(Priority Queue)。
2.特性:
Java集合框架中提供了PriorityQueue和PriorityBlockingQueue两种类型的优先级队列,PriorityQueue是线程不安全的,PriorityBlockingQueue是线程安全的,本文主要介绍PriorityQueue。关于PriorityQueue的使用要注意:
- 使用时必须导入PriorityQueue所在的包,即:
import java.util.PriorityQueue;
- PriorityQueue中放置的元素必须要能够比较大小,不能插入无法比较大小的对象,否则会抛出
ClassCastException异常。 - 不能插入null对象,否则会抛出NullPointerException。
- 没有容量限制,可以插入任意多个元素,其内部可以自动扩容。
- 插入和删除元素的时间复杂度为 O ( l o g 2 N ) O(log_2N) O(log2N)。
- PriorityQueue底层使用了堆数据结构。
注意:
堆(Heap),首先我们需要搞清楚的是,此处我们所讲的堆和JAVA中的堆(JVM持有内存中的一个内存区域)以及操作系统中的堆(每个进程所持有的一定内存空间里面的特定内存区域)是不相同的!!!
3.优先级队列的构造

static void TestPriorityQueue(){
// 创建一个空的优先级队列,底层默认容量是11
PriorityQueue<Integer> q1 = new PriorityQueue<>();
// 创建一个空的优先级队列,底层的容量为initialCapacity
PriorityQueue<Integer> q2 = new PriorityQueue<>(100);
ArrayList<Integer> list = new ArrayList<>();
list.add(4);
list.add(3);
list.add(2);
list.add(1);
// 用ArrayList对象来构造一个优先级队列的对象
// q3中已经包含了三个元素
PriorityQueue<Integer> q3 = new PriorityQueue<>(list);
System.out.println(q3.size());
System.out.println(q3.peek());
}
注意: 默认情况下,PriorityQueue队列底层默认容量是11。
4.优先级是如何判定的?
public class Test {
public static void main(String[] args) {
//定义一个优先队列,并且打印输出!
PriorityQueue<Integer> queue = new PriorityQueue<>();
int[] arr = {9,5,2,7,3,6,8};
for (int x: arr){
queue.offer(x);
}
System.out.print("优先队列输出结果:");
while (!queue.isEmpty()){
Integer x = queue.poll();
System.out.print(x+" ");
}
运行结果:
那这里就有一个疑问了:——>优先级队列中的元素的 “大小关系” 该如何制定???
再看一则代码示例:
import java.util.Comparator;
import java.util.PriorityQueue;
class Boy implements Comparable<Boy> {
public String name;
public int age;
public int money; // 有钱
public int face; // 有颜
public Boy(String name, int age, int money, int face) {
this.name = name;
this.age = age;
this.money = money;
this.face = face;
}
@Override
public int compareTo(Boy o) {
return o.money - this.money;
}
}
class BoyComparator implements Comparator<Boy> {
@Override
public int compare(Boy o1, Boy o2) {
return o1.money - o2.money;
}
}
public class Test {
public static void main(String[] args) {
Boy[] arr1 = {
new Boy("张三", 20, 10, 100),
new Boy("李四", 40, 100, 10),
new Boy("王五", 30, 50, 50),
new Boy("赵六", 50, 120, 5),
};
PriorityQueue<Boy> queue1 = new PriorityQueue<>();
for (Boy boy : arr1) {
queue1.offer(boy);
}
while (!queue1.isEmpty()) {
Boy cur = queue1.poll();
System.out.println(cur.name);
}
}
}
运行结果:
这里需要讲一下java.lang.Comparable这个包,它其实是标准库内置的一个接口,里面只有一个抽象方法compareTo(Object other),通过这个方法来指定对象自身和另一个对象之间的大小关系!用来定义"比较规则",除此之外,还有一个Comparator,也可以起到类似作用!两者不同之处在于:comparable接口,它是哪个类需要比较,就需要让这个类实现接口!Comparator接口,定义一个新类,实现该接口,里面compare方法的参数是两个,对应到要比较的类。
使用Comparable已经能解决大部分情况~少数情况下使用Comparator,如需要指定多重比较规则的时候!
5. 插入/删除/获取优先级最高的元素
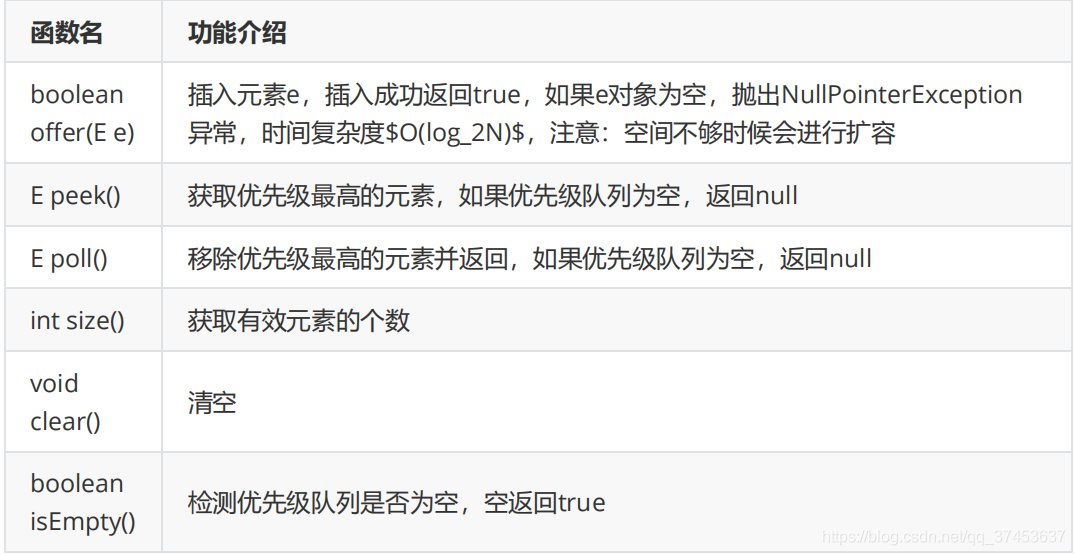
代码实现:
static void TestPriorityQueue2(){
int[] arr = {4,1,9,2,8,0,7,3,6,5};
// 一般在创建优先级队列对象时,如果知道元素个数,建议就直接将底层容量给好
// 否则在插入时需要不多的扩容
// 扩容机制:开辟更大的空间,拷贝元素,这样效率会比较低
PriorityQueue<Integer> q = new PriorityQueue<>(arr.length);
for (int e: arr) {
q.offer(e);
}
System.out.println("\n"+"打印优先级队列中有效元素个数:"+q.size());
System.out.println("\n"+"获取优先级最高的元素:"+q.peek());
System.out.println("\n"+"从优先级队列中删除两个元素之和,再次获取优先级最高的元素!!!");
q.poll();
q.poll();
System.out.println("\n"+"打印优先级队列中有效元素个数:"+q.size());
System.out.println("\n"+"获取优先级最高的元素:"+q.peek());
System.out.println("\n"+"入队一个元素“0”!!!");
q.offer(0);
System.out.println("\n"+"获取优先级最高的元素:"+q.peek());
System.out.println("\n"+"将优先级队列中的有效元素删除掉,检测其是否为空!!!");
q.clear();
if(q.isEmpty()){
System.out.println("优先级队列已经为空!!!");
}else{
System.out.println("优先级队列不为空");
}
}
}
运行结果: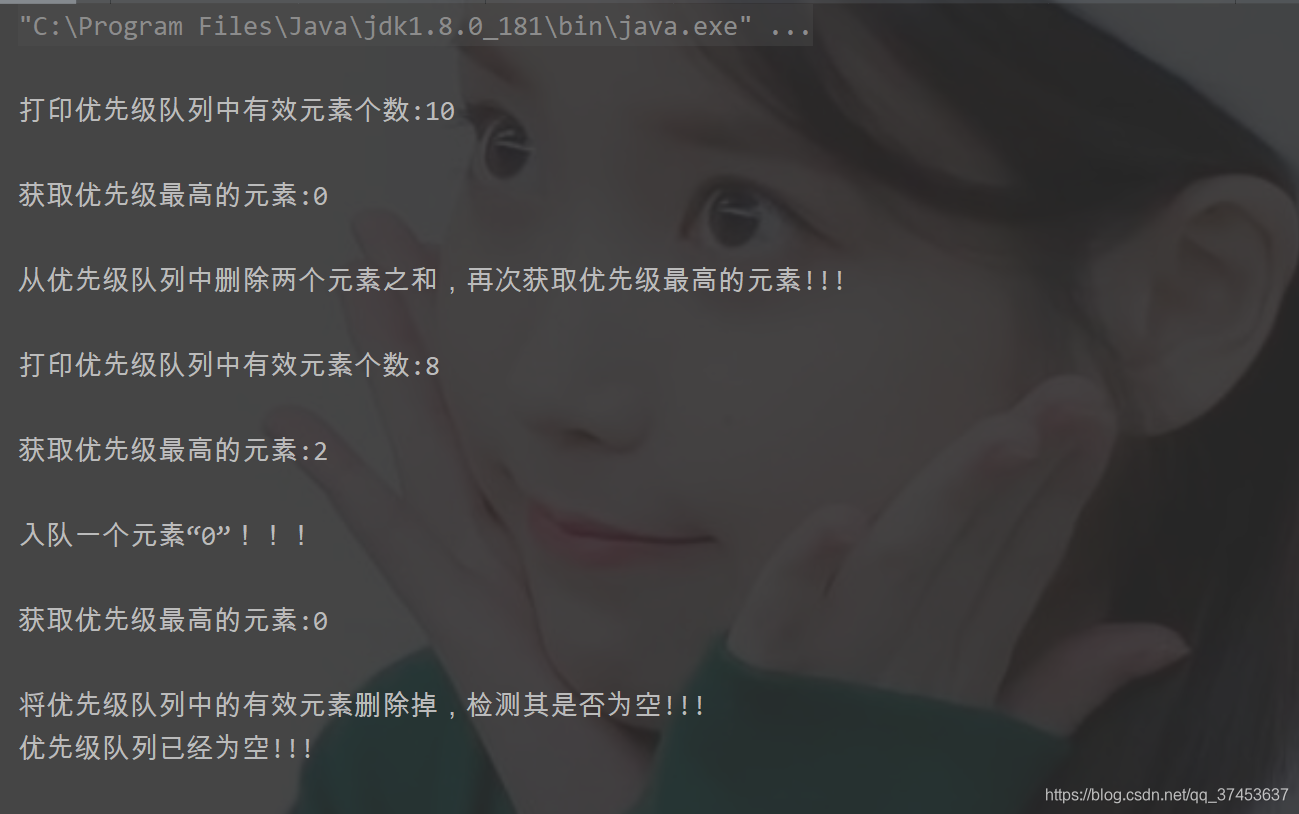
6.优先级队列的应用
在当前阶段,主要是有两个用途:
1.用来排序(堆排序)(下一篇博客涉及);
2.用来解决topK问题。
假设有1亿个数据(int),大约400M大小,想从其中找出前一千个最大的数字!(t这是一个topK问题)
方案一:直接针对这1亿个数据的数组进行建造大堆,接下来循环1000次,进行取堆顶元素/删除堆顶元素操作~这个方案得到的前一千个数据本身也是有序的!!!
方案二:创建一个大小为1000的小堆,遍历这1亿个数据,依次往堆里进行插入,如果堆没满,就直接插入,如果堆满了,此时小堆的堆顶就是这个堆里的最小值,就拿当前值和这个堆顶元素进行比较,如果当前值比这个堆顶元素还小,那就直接pass;如果当前值比堆顶元素大,就删除原来的堆顶元素,把新的这个元素插入堆中。最终遍历完1亿个元素后此时堆里剩下的元素就一定是前1000个元素~这个方案比较节省时间和空间消耗!!!
7.优先级队列的模拟实现
堆的定义:
如果有一个关键码的集合K = {k0,k1, k2,…,kn-1},把它的所有元素按完全二叉树的顺序存储方式存储,在一个一维数组中,并满足:Ki <= K2i+1 且 Ki<= K2i+2 (Ki >= K2i+1 且 Ki >= K2i+2) i = 0,1,2…,则称为小堆(或大堆)。将根节点最大的堆叫做最大堆或大根堆,根节点最小的堆叫做最小堆或小根堆。
图一:最大堆; 图二:最小堆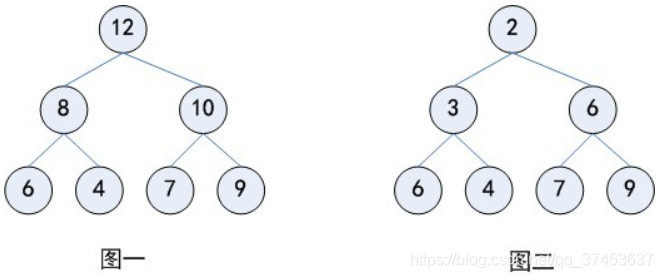
堆的性质:
1.堆中某个节点的值总是不大于或不小于其父节点的值;
2.堆总是一棵完全二叉树。
堆的存储方式:
从堆的概念可知,堆是一棵完全二叉树,因此可以层序的规则采用顺序的方式来高效存储!
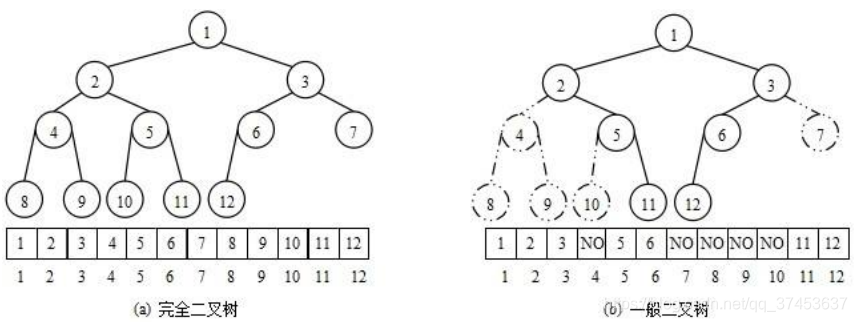
注意: 对于非完全二叉树,则不适合使用顺序方式进行存储,因为为了能够还原二叉树,空间中必须要存储空节点,就会导致空间利用率比较低。
性质:
如果 i 为 0,则 i 表示的节点为根节点,否则i节点的双亲节点为 (i - 1)/2;
如果2 * i + 1 小于节点个数,则节点 i 的左孩子下标为2 * i + 1,否则没有左孩子;
如果2 * i + 2 小于节点个数,则节点 i 的右孩子下标为2 * i + 2,否则没有右孩子。
堆的基本操作:
堆的创建:给定一个数组,整理成堆这样的结构(转成完全二叉树并且使用数组形式来存储,满足下标关系和堆的关系)。
堆的创建可以使用向上调整实现,也可以使用向下调整实现。
向下调整实现代码:
/*
向下调整是创建堆的一个核心操作
前提条件, 要求当前被调整节点的左右子树都已经是堆了!
方法参数给出了一个 size 表示当前数组的有效元素大小.
虽然可以通过 arr.length 取到大小, 这个大小是数组的总的大小
index 表示从这个位置开始进行向下调整,
还是按照大堆的方式来实现.
时间复杂度 O(logN)
如果数据是依次 (* 2 )(/ 2) 的方式变化的时候, 时间复杂度基本都和 logN 相关
*/
public static void shiftDown(int[] arr, int size, int index) {
int parent = index;
int child = 2 * parent + 1;//此处得到的是左子树
while (child < size) {
// 需要找到左右子树中较大的值
// 左右子树下标差 1,child+1得到的是右子树
if (child + 1 < size && arr[child + 1] > arr[child]) {
child = child + 1;
}
// 当上述条件执行完后, 就能保证 child 指向左右子树较大的元素。
// 拿父节点和刚才找出的这个较大的节点再去比较, 看是否符合大堆的要求!
if (arr[parent] < arr[child]) {
// 不满足大堆的要求, 交换两个元素。
int tmp = arr[parent];
arr[parent] = arr[child];
arr[child] = tmp;
} else {
// 调整完毕了, 已经把父元素放到了合适的位置上
break;
}
// 更新 parent 和 child 以备下次循环
parent = child;
child = 2 * parent + 1;
}
}
向上调整代码实现:
/*
向上调整只需要保证该节点比父节点大即可!!!
*/
public static void shiftUp(int[] arr, int size, int index) {
int child = index;
int parent = (child - 1) / 2;
// 如果 child 为 0, 说明已经调整到最上面了
while (child > 0) {
if (arr[parent] < arr[child]) {
// 不符合大堆的要求
// 交换两个元素
int tmp = arr[parent];
arr[parent] = arr[child];
arr[child] = tmp;
} else {
break;
}
child = parent;
parent = (child - 1) / 2;
}
}
堆的创建代码实现:
// 建堆操作
public static void createHeap(int[] array) {
/*
基于向下调整的建堆:
从后往前遍历数组, 针对每个下标都去进行向下调整即可~~
此处的循环不必从 length - 1 开始.从叶子节点往下进行查找是不合适的~~
从第一个非叶子节点开始进行向下调整,
实际向下调整的时候不一定非得从最后一个元素的下标开始.
可以从最后一个非叶子节点开始即可.就可以通过最后一个节点再找到父节点即可~~
直观上看, 建堆的时间复杂度 O(NlogN)
但是实际上, 不是, 实际上是 O(N) (数学推导出来的)
*/
for (int i = (array.length - 1 - 1) / 2; i >= 0; i--) {
shiftDown(array, array.length, i);
}
}
向对中插入元素代码实现:
// 往堆中插入元素
// 这就表示当前存储堆的数组
private int[] arr = new int[100];
private int size = 0;
public void offer(int val) {
if (size >= arr.length) {
// 插入失败, 已经满了.
// 也可以实现扩容逻辑.
return;
}
// 先是把这个元素给尾插到数组末尾
arr[size] = val;
size++;
// 把最后的这个元素进行向上调整
shiftUp(arr, size, size - 1);
}
获取堆顶元素代码实现:
// 获取堆顶元素
public Integer peek() {
if (size == 0) {
return null;
}
return arr[0];
}
删除堆顶元素代码实现:
// 删除操作(一定是删除堆顶的元素)
public Integer poll() {
if (size == 0) {
return null;
}
int result = arr[0];
// 交换 0 号元素和 size - 1 号元素
int tmp = arr[0];
arr[0] = arr[size - 1];
arr[size - 1] = tmp;
// size--, 把最后的元素干掉
size--;
// 从 0 号元素开始, 往下进行向下调整
shiftDown(arr, size, 0);
return result;
}

















 1106
1106

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









