







EM算法及其推广
9.1 EM算法
适用于无监督学习。训练数据只有输入没有对应的输出,可以认为无监督学习的训练数据是联合概率分布产生的数据。
应用场景:引自博主
如果我们要求解的是一个混合模型,只知道混合模型中各个类的分布模型(譬如都是高斯分布)和对应的采样数据,而不知道这些采样数据分别来源于哪一类(隐变量),那这时候就可以借鉴EM算法。EM算法可以用于解决数据缺失的参数估计问题(隐变量的存在实际上就是数据缺失问题,缺失了各个样本来源于哪一类的记录)
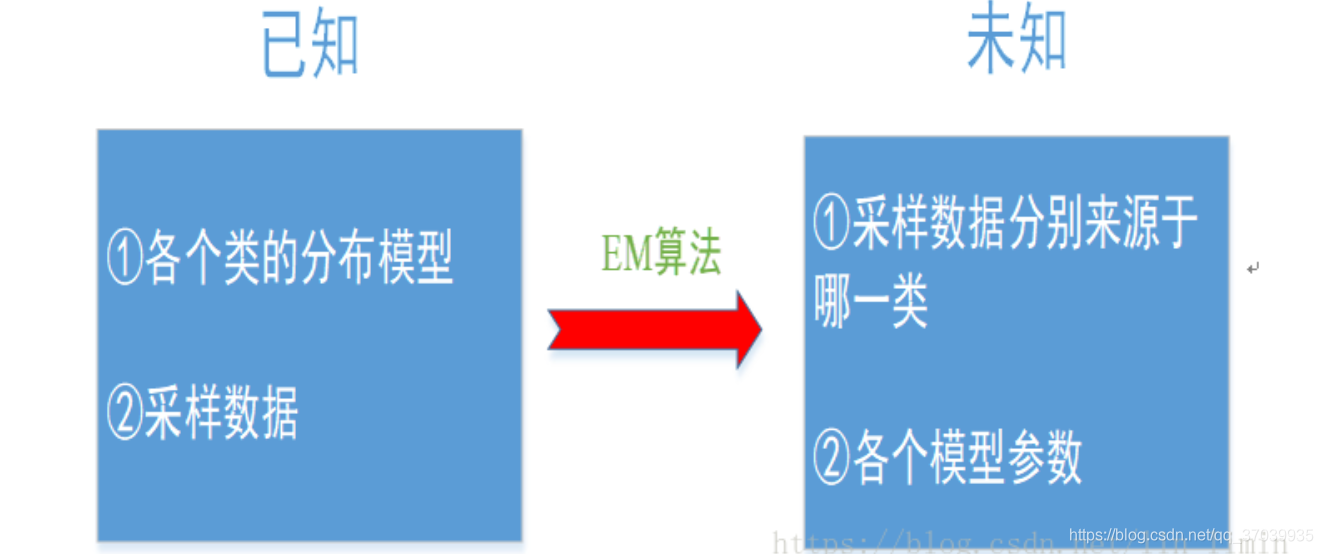
9.1.1 EM算法介绍
EM算法:含有隐变量的概率模型参数的极大似然估计法或极大后验概率估计法。每次迭代分为E步(极大期望)和M步(求极大)。
三硬币模型

在这个实例中,抛硬币A的结果(这里记为Z )是无法观测的,所以该结果称之为隐变量。
在该例子中,也可以称(Y,Z)为完全数据,Y为不完全数据
设随意变量Y为观测到的抛硬币的结果(即观测变量), θ = ( π , p , q ) \theta=(\pi,p,q) θ=(π,p,q)是模型参数,则可以得到模型的似然函数(因为这里是离散变量,所以是求和,连续变量则为求积分):
P ( Y ∣ θ ) = ∑ Z P ( Z ∣ θ ) P ( Y ∣ Z , θ ) = ∏ j = 1 n [ π p y j ( 1 − p ) 1 − y j + ( 1 − π ) q y j ( 1 − q ) 1 − y j ] P(Y|\theta)=\sum\limits_ZP(Z|\theta)P(Y|Z,\theta)\\ =\prod\limits_{j=1}^n\left [ \pi p^{y_j}(1-p)^{1-y_j}+(1-\pi)q^{y_j}(1-q)^{1-y_j} \right ] P(Y∣θ)=Z∑P(Z∣θ)P(Y∣Z,θ)=j=1∏n[πpyj(1−p)1−yj+(1−π)qyj(1−q)1−yj]
按照正常的求解过程,对参数 θ \theta θ进行极大似然估计,即:
θ = arg max θ log P ( Y ∣ θ ) \theta = \arg\max\limits_{\theta}\log P(Y|\theta) θ=argθmaxlogP(Y∣θ)
这个问题没有解析解,因为模型中既有未知变量Z也有模型变量 θ \theta θ。只能通过迭代计算参数的估计值。EM算法就是用于求解这种问题的迭代算法。
算法9.1 EM算法
输入:观测数据变量Y,隐变量数据Z,联合分布P(Y,Z| θ \theta θ),条件分布P(Z|Y, θ \theta θ)
输出:模型参数 θ \theta θ
(1)选择参数的初值 θ ( 0 ) \theta^{(0)} θ(0),开始迭代;
(2)E步:记 θ ( i ) \theta^{(i)} θ(i)为第i此迭代参数 θ \theta θ的估计值,在第i+1此迭代的E步,计算
Q ( θ , θ ( i ) ) = E Z [ log ( P ( Y , Z ∣ θ ) ∣ Y , θ ( i ) ] = ∑ Z log ( P ( Y , Z ∣ θ ) P ( Z ∣ Y , θ ( i ) ) Q(\theta,\theta^{(i)})=E_Z\left [ \log(P(Y,Z|\theta)|Y,\theta^{(i)} \right]\\ = \sum_Z\log(P(Y,Z|\theta)P(Z|Y,\theta^{(i)}) Q(θ,θ(i))=EZ[log(P(Y,Z∣θ)∣Y,θ(i)]=Z∑log(P(Y,Z∣θ)P(Z∣Y,θ(i))
上式子的思想主要为:由于Zi是隐变量,为了能够计算 θ \theta θ是排除其他可变量,所以通过利用固定值Z的期望代替变量Zi求近似极大化,即 Z i → E ( Z ) Z_i \rightarrow E(Z) Zi→E(Z) Q函数的意义为在给定观测数据Y和当前参数 θ ( i ) \theta^{(i)} θ(i)下对为观测数据Z的条件概率分布 P ( Z ∣ Y , θ ( i ) ) P(Z|Y,\theta^{(i)}) P(Z∣Y,θ(i))的期望。Q中的第一个变元表示要极大化的参数,第二个变元表示当前该参数的估计值。每次迭代的最终目的为求Q函数的极大。
(3)M步:求使得 Q ( θ , θ ( i ) ) Q(\theta,\theta^{(i)}) Q(θ,θ(i))极大化的 θ \theta θ,确定第i+1次的迭代的参数估计值 θ ( i + 1 ) \theta^{(i+1)} θ(i+1):
θ ( i + 1 ) = arg max θ Q ( θ , θ ( i ) ) \theta^{(i+1)} =\arg\max_\theta Q(\theta,\theta^{(i)}) θ(i+1)=argθmaxQ(θ,θ(i))
每一次迭代产生 θ ( i + 1 ) \theta^{(i+1)} θ(i+1),会使得似然函数增大或达到局部极值。
(4)重复(2)(3)直到收敛。(较小的正数 ε 1 , ε 2 \varepsilon_1,\varepsilon_2 ε1,ε2,若满足:
∣ ∣ θ ( i + 1 ) − θ ( i ) ∣ ∣ < ε 1 o r ∣ ∣ Q ( θ ( i + 1 ) , θ ( i ) ) − Q ( θ ( i ) , θ ( i ) ) ∣ ∣ < ε 2 ||\theta^{(i+1)}-\theta^{(i)}||<\varepsilon_1\\ or\\ ||Q(\theta^{(i+1)},\theta^{(i)})-Q(\theta^{(i)},\theta^{(i)})|| < \varepsilon_2 ∣∣θ(i+1)−θ(i)∣∣<ε1or∣∣Q(θ(i+1),θ(i))−Q(θ(i),θ(i))∣∣<ε2
则停止迭代。)
9.1.2 EM算法推导
模型目标:极大化观测数据Y关于参数 θ \theta θ的对数似然函数,即极大化:
L ( θ ) = log P ( Y ∣ θ ) = log ∑ Z P ( Y , Z ∣ θ ) = log ( ∑ Z P ( Y ∣ Z , θ ) P ( Z ∣ θ ) ) L(\theta)=\log P(Y|\theta)=\log\sum_Z P(Y,Z|\theta)\\ =\log(\sum_ZP(Y|Z,\theta)P(Z|\theta)) L(θ)=logP(Y∣θ)=logZ∑P(Y,Z∣θ)=log(Z∑P(Y∣Z,θ)P(Z∣θ))
在极大化的过程中,因为涉及到隐变量Z未知,所以极大化求解困难。
所以EM的主要思想是迭代逐步近似极大化 L ( θ ) L(\theta) L(θ)。
假设新估计值 θ \theta θ,上一次的估计值 θ ( i ) \theta^{(i)} θ(i),为了每次迭代能够使得极大值尽可能增加,所以这里考虑每次迭代对数似然函数的增加量:
L ( θ ) − L ( θ ( i ) ) = log ( ∑ Z P ( Y ∣ Z , θ ) P ( Z ∣ θ ) ) − log P ( Y ∣ θ ( i ) ) = log ( ∑ Z P ( Z ∣ Y , θ ( i ) ) P ( Y ∣ Z , θ ) P ( Z ∣ θ ) P ( Z ∣ Y , θ ( i ) ) ) − log P ( Y ∣ θ ( i ) ) L(\theta)-L(\theta^{(i)})=\log(\sum_ZP(Y|Z,\theta)P(Z|\theta))-\log P(Y|\theta^{(i)})\\ =\log(\sum_ZP(Z|Y,\theta^{(i)})\frac{P(Y|Z,\theta)P(Z|\theta)}{P(Z|Y,\theta^{(i)})})-\log P(Y|\theta^{(i)}) L(θ)−L(θ(i))=log(Z∑P(Y∣Z,θ)P(Z∣θ))−logP(Y∣θ(i))=log(Z∑P(Z∣Y,θ(i))P(Z∣Y,θ(i))P(Y∣Z,θ)P(Z∣θ))−logP(Y∣θ(i))
Jensen不等式:
log ∑ j λ j y j ⩾ ∑ j λ j log y i λ j ⩾ 0 a n d ∑ j λ j = 1 \log\sum_j\lambda_jy_j\geqslant\sum_j\lambda_j\log y_i \\ \lambda_j \geqslant 0 \ \ and \ \ \sum_j\lambda_j=1 logj∑λjyj⩾j∑λjlogyiλj⩾0 and j∑λj=1
利用以上不等式可以变形为
L ( θ ) − L ( θ ( i ) ) ⩾ ∑ Z P ( Z ∣ Y , θ ( i ) ) log P ( Y ∣ Z , θ ) P ( Z ∣ θ ) P ( Z ∣ Y , θ ( i ) ) − log P ( Y ∣ θ ( i ) ) = ∑ Z P ( Z ∣ Y , θ ( i ) ) log P ( Y ∣ Z , θ ) P ( Z ∣ θ ) P ( Z ∣ Y , θ ( i ) ) P ( Y ∣ θ ( i ) ) L(\theta)-L(\theta^{(i)}) \geqslant \sum_ZP(Z|Y,\theta^{(i)})\log\frac{P(Y|Z,\theta)P(Z|\theta)}{P(Z|Y,\theta^{(i)})}-\log P(Y|\theta^{(i)})\\ =\sum_ZP(Z|Y,\theta^{(i)})\log\frac{P(Y|Z,\theta)P(Z|\theta)}{P(Z|Y,\theta^{(i)})P(Y|\theta^{(i)})} L(θ)−L(θ(i))⩾Z∑P(Z∣Y,θ(i))logP(Z∣Y,θ(i))P(Y∣Z,θ)P(Z∣θ)−logP(Y∣θ(i))=Z∑P(Z∣Y,θ(i))logP(Z∣Y,θ(i))P(Y∣θ(i))P(Y∣Z,θ)P(Z∣θ)
把 L ( θ ( i ) ) L(\theta^{(i)}) L(θ(i))移向到等号右侧,令:
B ( θ , θ ( i ) ) = L ( θ ( i ) ) + ∑ Z P ( Z ∣ Y , θ ( i ) ) log P ( Y ∣ Z , θ ) P ( Z ∣ θ ) P ( Z ∣ Y , θ ( i ) ) P ( Y ∣ θ ( i ) ) B(\theta,\theta^{(i)}) = L(\theta^{(i)})\ + \ \sum_ZP(Z|Y,\theta^{(i)})\log\frac{P(Y|Z,\theta)P(Z|\theta)}{P(Z|Y,\theta^{(i)})P(Y|\theta^{(i)})} B(θ,θ(i))=L(θ(i)) + Z∑P(Z∣Y,θ(i))logP(Z∣Y,θ(i))P(Y∣θ(i))P(Y∣Z,θ)P(Z∣θ)
得到下界 L ( θ ) L(\theta) L(θ)的一个下界 B ( θ , θ ( i ) ) B(\theta,\theta^{(i)}) B(θ,θ(i)):
L ( θ ) ⩾ B ( θ , θ ( i ) ) L(\theta)\geqslant B(\theta,\theta^{(i)}) L(θ)⩾B(θ,θ(i))
因此,任意一个使得下界增大的 θ \theta θ,也可以使似然函数增大,所以为了似然函数尽可能大的增长,应选择 θ ( i + 1 ) \theta^{(i+1)} θ(i+1)使得下界达到极大:
θ ( i + 1 ) = arg max θ B ( θ , θ ( i ) ) \theta^{(i+1)} =\arg\max_\theta B(\theta,\theta^{(i)}) θ(i+1)=argθmaxB(θ,θ(i))
在求解该式子中,省去一些不包含 θ \theta θ变量得常数项,得:
θ ( i + 1 ) = arg max θ ( L ( θ ( i ) ) + ∑ Z P ( Z ∣ Y , θ ( i ) ) log P ( Y ∣ Z , θ ) P ( Z ∣ θ ) P ( Z ∣ Y , θ ( i ) ) P ( Y ∣ θ ( i ) ) ) = arg max θ ( ∑ Z P ( Z ∣ Y , θ ( i ) ) log P ( Y ∣ Z , θ ) P ( Z ∣ θ ) ) 保 留 了 P ( Z ∣ Y , θ ( i ) ) 该 常 数 项 = arg max θ ( ∑ Z P ( Z ∣ Y , θ ( i ) ) log ( P ( Y , Z ∣ θ ) ) = arg max θ Q ( θ , θ ( i ) ) \theta^{(i+1)} = \arg\max_\theta(L(\theta^{(i)})\ + \ \sum_ZP(Z|Y,\theta^{(i)})\log\frac{P(Y|Z,\theta)P(Z|\theta)}{P(Z|Y,\theta^{(i)})P(Y|\theta^{(i)})})\\ =\arg\max_\theta(\sum_ZP(Z|Y,\theta^{(i)})\log{P(Y|Z,\theta)P(Z|\theta)}) 保留了P(Z|Y,\theta^{(i)})该常数项\\ =\arg\max_\theta(\sum_ZP(Z|Y,\theta^{(i)})\log(P(Y,Z|\theta))\\ =\arg\max_\theta Q(\theta,\theta^{(i)}) θ(i+1)=argθmax(L(θ(i)) + Z∑P(Z∣Y,θ(i))logP(Z∣Y,θ(i))P(Y∣θ(i))P(Y∣Z,θ)P(Z∣θ))=argθmax
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 349
349

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









