







Relational learning module(CVPR2018)
文章
本文的基础的visual relationship detection框架还是iterative message passing那套,不过想办法加入了relationship的分布先验知识
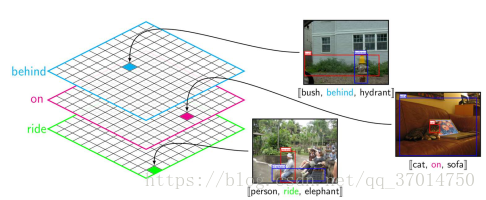
如果对整个数据集分析的话,假设一共有n类object,m类predicate,统计不同的sub-pre-obj,可以得到一个nxnxm的张量,这个张量可以看作m个nxn的矩阵堆叠的,每个矩阵对于一种predicate,假设第k个矩阵,其第(i,j)个元素则表示visual phrase (i-k-j)的出现次数。这个张量有一个特点就是很稀疏,而且不对称,因为有很多物体之间的某些关系在数据集出现很少甚至没有。事实上几乎只有约1%的可能关系被dataset包含了,也就是有很多数据缺失。
直接用上面这个稀疏的张量当做先验的话几没有太大用处,因为很多0,于是paper想办法先将其分解,然后重组。由于张量很稀疏,每个object都可以有r维的隐藏表示,于是可以将所有物体的表示设为A(nxr的矩阵),对于每个关系k,有一个关系因子矩阵R_k(rxr矩阵),至于为什么要这么做可以参看交替最小二乘法ALS,于是分解的模型可以写为:
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章

















 207
207

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









