







神经网络基础
2.1 二分分类
1、二分分类(Binary Classification)例子
cat vs no cat
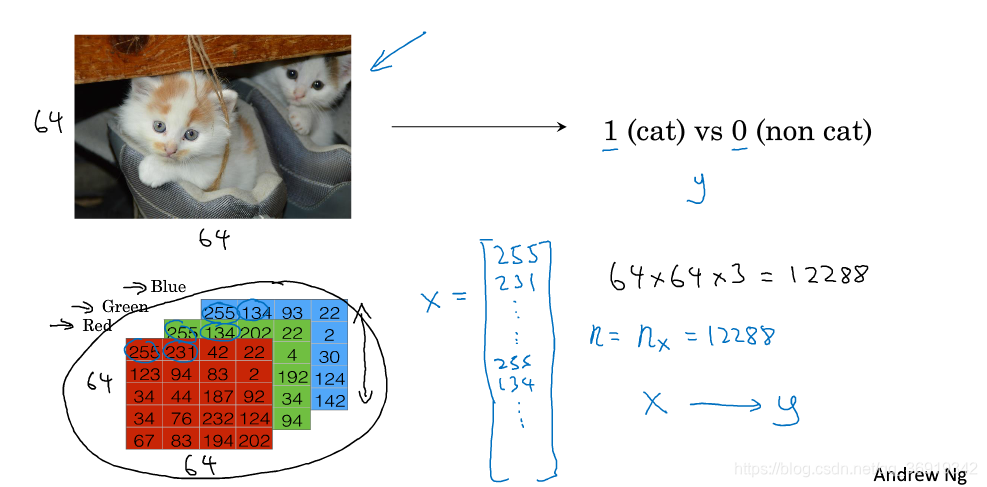
输入一张图片,这张图片可以由一个特征向量x表示,并预测该图片中是否有猫,输出y,y为0时则表示没有猫,为1则表示有猫。
假设该图片分辨率为6464,其在电脑中的表示方式为三个6464的矩阵,这三个矩阵分别表示红、黄、蓝三个RGB颜色通道亮度。特征向量x的构建即是把三个矩阵数据依次放入到向量中,如下图所示:
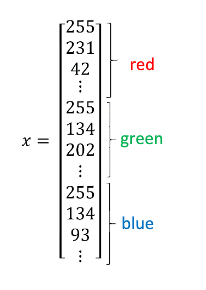
所以特征向量x的维度nx=64 * 64 * 3=12288。
基本术语解释
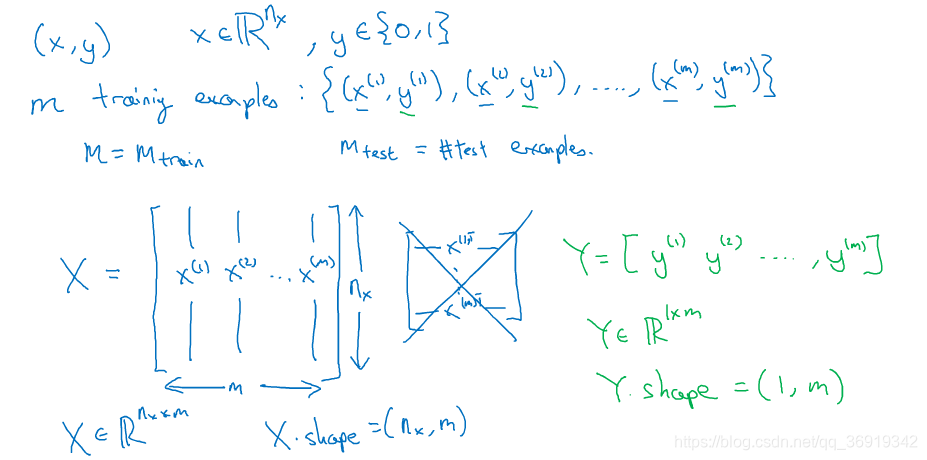
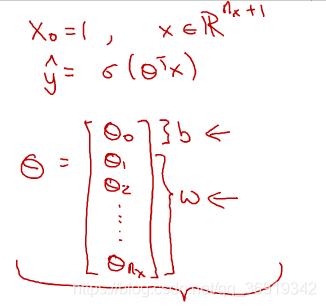
用一对(x,y)来表示一对样本,x是nx维特征向量,y为标签,值为0或1;倘若有m个训练集,那么(x^ (1),y^(1))表示样本一, (x^ (2),y^(2)) 表示样本二,……,(x^ (m),y^(m))表示样本m。所以合起来就是一个m的训练集。
m表示训练集大小,有时会在m下标处加上train表示训练集,下标为test表示测试集。
X是一个nx * m矩阵,用于整合特征向量x。
Y是一个1 * m矩阵,用于整合标签y。
2.2 logistic 回归
上例说到的输入x给出y,但是更好的一个结果是y’,即图片中有猫的概率,当图片中100%有猫时则y’为1。
x是一个nx维向量,logistic回归参数w为nx维向量,b为实数,那么如何得出y’?
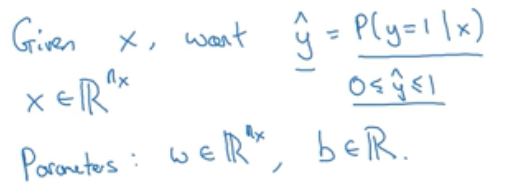
一般而言使用如下公式:
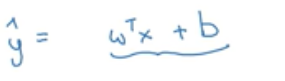
(w转置x加b)
但这样没多大作用,因为y’是一个概率的话应该是介于0到1之间,而用上面公式计算出来的y’可能大于1也有可能为负数,这样的概率没有意义。
所以要让y’等于sigmoid函数作用到这个量上,如下所示:
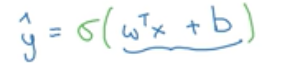
sigmoid(z)函数如下图所示:
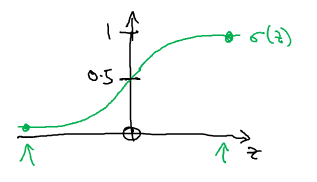
是从0到1的光滑函数。公式如下:
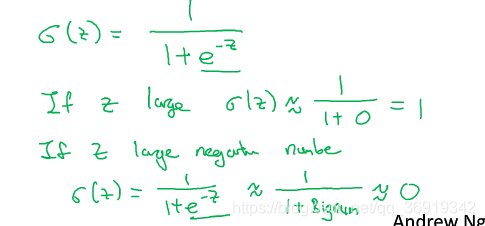
如果z趋向于正无穷大那么e^ -z就接近0,如果z趋向于负无穷大那么e^ -z趋向于正无穷大,所以w^ Tx+b可以由z代替,y’表示一个0到1的数。
其他表示形式
2.3 logistic 回归损失函数
符号约定:使用上标(i)来指明数据x、y、y’和第i个样本数据集有关。
1、损失函数
损失函数L往往用来衡量算法的运行情况,公式如下:
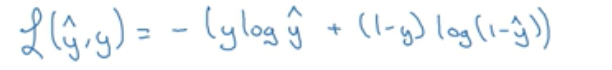
为什么这个函数可以衡量误差
如果y = 1,那么L(y’,y) = -log(y’),所以要求误差足够小,那么则要求log(y’)足够大,而y’是sigmoid函数,则y’是无限接近1的。
如果y = 0,那么L(y’,y) = -log(1-y’),所以要求误差足够小,那么则要求log(1-y’)足够大,则要求y’无限趋向于0,

这里要注意,损失函数L衡量了算法在单个训练样本上的表现。
2、成本函数
用来衡量全体训练样本上的表现,公式如下:
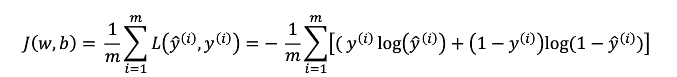
所以要找准参数w,b是的成本函数可能小。
2.4 梯度下降法
1、J(w,b)图像
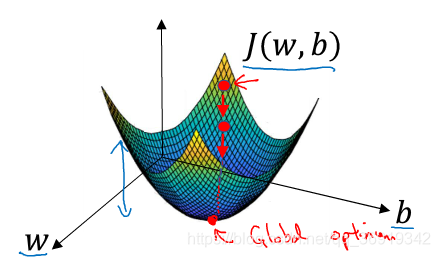
由于J(w,b)是一个一个凸面的,所以可以使用梯度下降法寻找最优解。
所谓梯度下降法,就是从初始点开始沿着坡度最陡的一个方向下降一步,直到接近全局最优解。
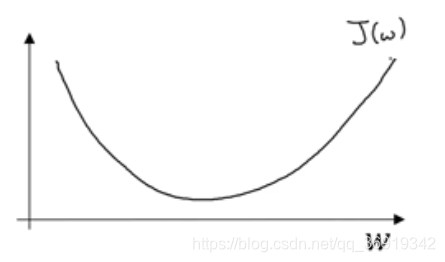
2、J(w)寻找最优w
J(w)图像如图所示,先忽略b:
重复执行以下操作;
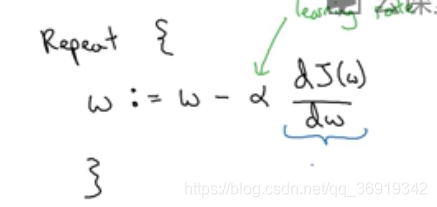
:=表示更新w值,α表示学习效率,dJ(w)/dw是表示函数J(w)对w求导。在编码中也常常使用dw表示导数。
w的更新算法是有意义的。假设w在上坡处,这时dJ(w)/dw是正数,则下一个w等于当前w减去学习率乘上一个正数,取在当前w左边位置。

所以初始化位置无论是左边还是右边,梯度下降法会朝着全局最小值方向移动。
所以对于J(w,b),w和b的更新公式为:
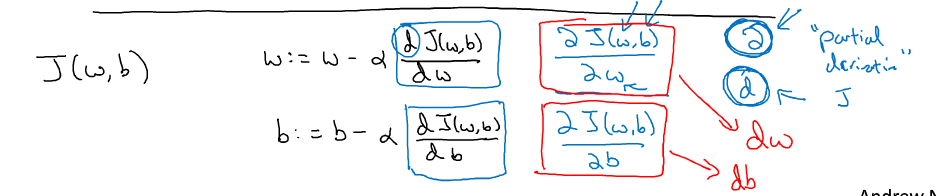
其中dJ(w,b)/dw,表示函数J在w方向上的倒数,在微积分中的含义就是J(w,b)对w的偏导数(如图中红色框所示)。dJ(w,b)/db同理。
2.5 计算图
1、一个小栗子
假设J是三个变量a,b,c的函数,这个函数是3*(a+b*c),令U = bc,V = a+u,J = 3v。把如上三步画成一个流程图:
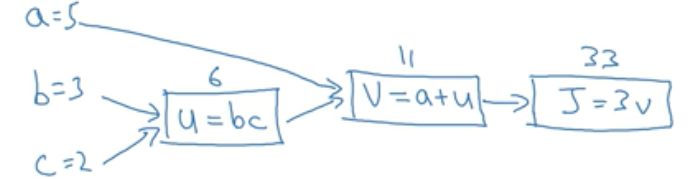
所谓流程图就是上图蓝色箭头画出来的从左到右的计算。
2.6 计算图的导数计算
继续上一小节流程图:
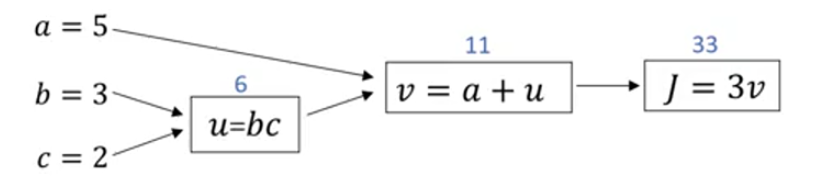
现在要求计算dJ/dv(J对v的导数):
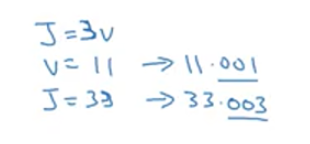
所以,J对v的导数为3,因为对于任何v的增量,J都会有三倍增量。所以J对v求导的过程相当于完成了一次反向传播。
再来看另一个例子——要求计算dJ/da:
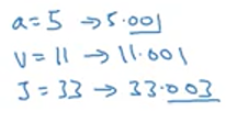
如图所示,所以J的增量是3倍乘以a的增量,意外着dJ/da=3。通过增加a来增加v,然后v的变化也改变了J。在微积分中这是一个链式法则,a通过改变v从而改变J,符合如下等式:
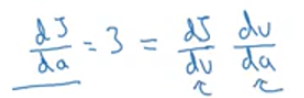
在这里,a增长0.001,v也增长0.001,所以dv/da=1,dJ/dv=3,所以dJ/da=3。所以这是另一步反向传播计算。
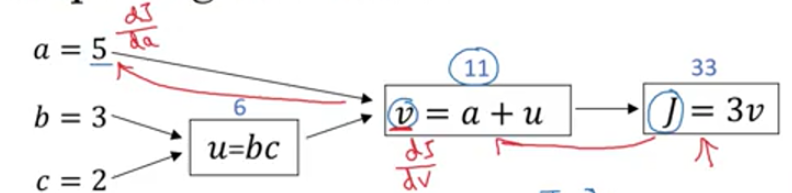
这里再介绍一个新的符号规定,当编程实现反向传播时,通常会有一个最终输出值你是最关心的,在上面流程图中,最关心输出就是J,所以有许多计算尝试计算输出变量的导数,所以,d输出变量 对 某个变量的导数,即d FinalOutputVar/d var,在编程中使用dvar来表示你关心的最终变量的导数(即对各个中间变量的导数)。如上图所示,dJ/dv在代码中即为dv表示。
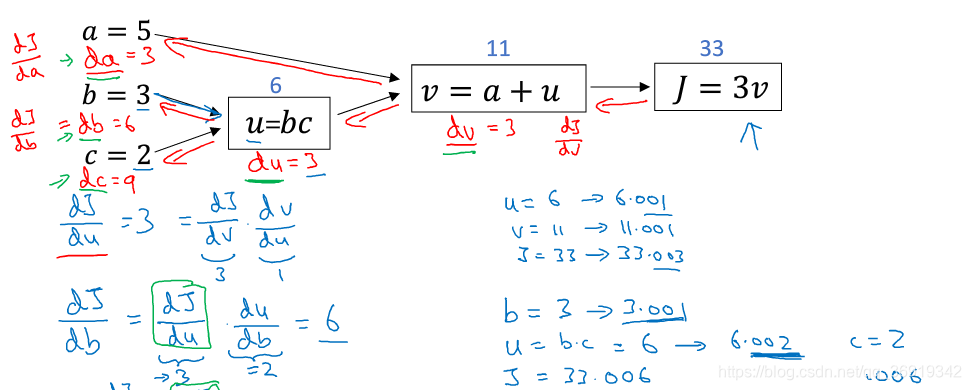
完整的反向传播图,如图所示:
2.7 logistic回归中的导数计算
logistic回归公式:
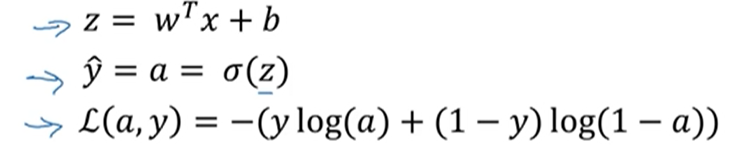
z表示该样本中有猫的概率,y帽是将概率控制再0-1之间,损失函数是指该预测值的误差。
logistic的工作是通过改变w1,w2,b来最小化损失函数:
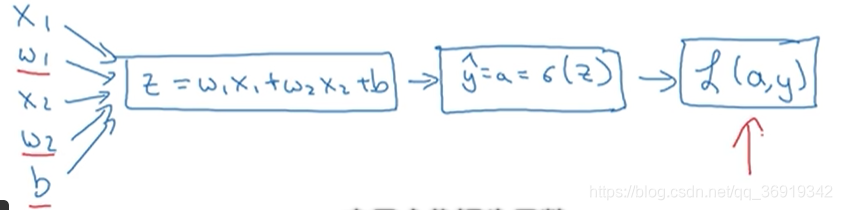
前面几节讲述了如何使用前向传播来计算损失函数,这里讲述使用后向传播计算出最佳的w与x值。
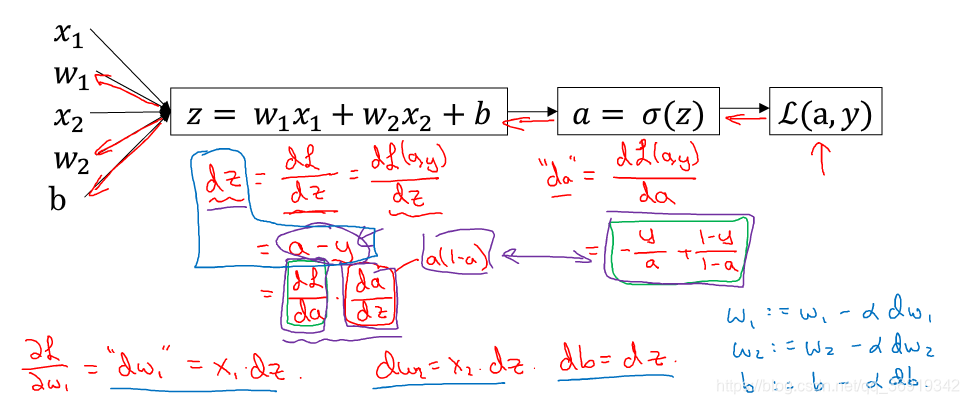
2.8 m个样本的梯度下降
明确J(w,b)的意义,表示的是损失函数求和取平均,在样本(x,y)输出a^(i),a ^(i)是输入样本的预测值也就是sigmoid(z ^(i)),z ^(i) = (w ^Tx ^(i)+b)
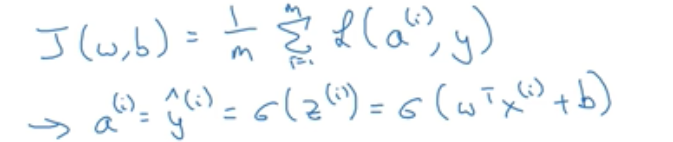
在上一个例子中提到任意单个训练样本如何计算导数,其实J函数对w1求导也就是等于损失函数L对w1求偏导之和取平均
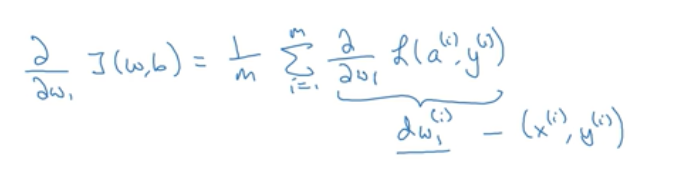
应用到梯度下降法
初始化:
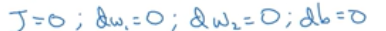
在使用一个for循环遍历训练集,计算单个样本的导数,然后再加起来,最后取平均。
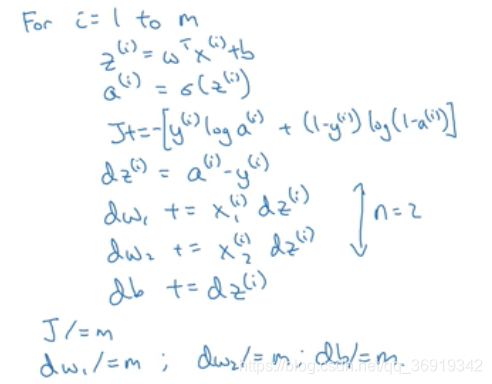
在上段代码中,dw1,dw2,db作为累加器,最后dw1等于J对w1的导数,所以没有上标。dz^(i)对应的是单个样本的dz,所以带上标。所以对在梯度下降法中对w1,w2的更新可以用如下公式:
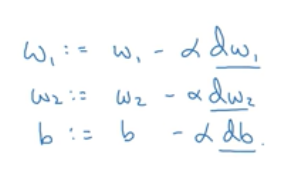
不足:在应用到梯度下降法中时需要写两个for循环,第一个for循环是计算m个样本的dw1,dw2,db。第二个for循环是遍历所有特征的for循环,上例有两个特征,n = 2,nx = 2。如果n足够大,要用一个for循环计算dw1,dw2,…,dwn。这使得算法很低效。
解决:使用向量化的方法避免显式for循环。
2.9 向量化
1、什么是向量化
当你需要计算:
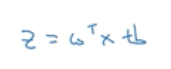
其中,w是列向量,x也是列向量。如果有许多特征值,许多样本,那么w,x会是一个很大的向量集。使用向量化和非向量化的方法如下:
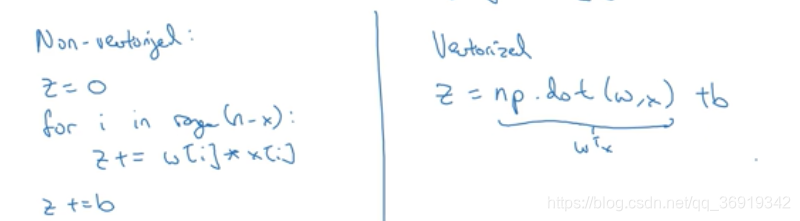
向量化的方法可以比非向量方法提高快300倍的速度
2、小知识
可扩展深度学习实现是在GPU(图像处理单元)上做的,一些小demo可以在jupyter notebook上实现,这里只要CPU,CPU和GPU都有并行化指令,有时称为SIMD指令,意思是单指令流多数据流,如上图所示的np.dot(w,x)函数或者np.function,其他能让你去掉显示for循环的函数,这样python的numpy能够充分利用并行化去更快的计算,这点对GPU和CPU上面计算都是成立的。GPU更加擅长SIMD计算。
3、向量化的更多例子
例子1
如果你想计算一个向量u作为矩阵A和另一个向量v的乘积,矩阵乘法的定义就是:
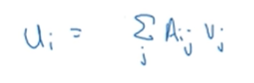
u = np.zeros(n,1).
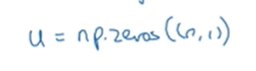
在非向量化方法中,对i循环,对j循环。u[i]+=A[i][j]v[j]。
向量化方法,u = up.dot(A,v)。消除了两个for循环,速度会快很多。

例子2
假设你的内存里有一个向量v,如果你想做指数运算,作用到向量v的每个元素,你可以令u等于如下:
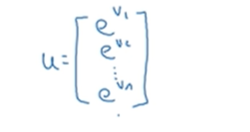
所以这是一个向量化的方法,先初始化u都为1,然后有一个for循环,一次计算一个元素

但是事实上python的numpy里面有很多内置函数,这里只需要调用单个函数:
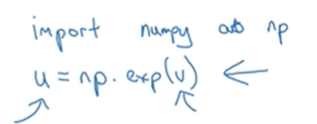
这样就省去了一个显示的for循环,速度会快许多。实际上,numpy函数库有许多向量值函数——np.log(v)会逐个计算元素log;np.Abs(v)会计算绝对值;np.maximum(v,0)计算所有元素的最大值;v**2就是v中每个元素的平方;1/v就是每个元素求倒数。所以尽量用内置函数计算而不是用for循环。
在logistic回归梯度下降算法实现的运用
logistic回归导数程序如下:
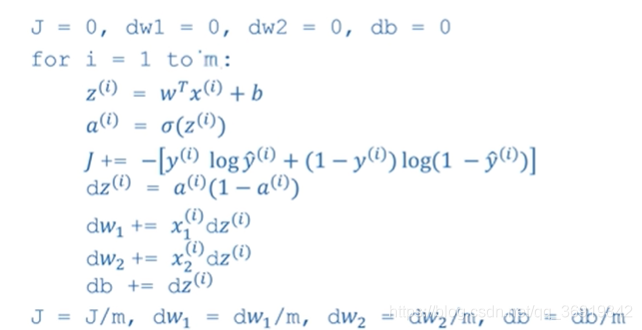
一共有两个for循环,一个是对i的循环,一个是如果特征值足够多,就要用for循环计算每一个特征值,如图所示:
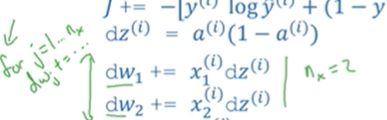
现在我们来消除第二个for循环,这里不会显示的把dw_1,dw_2等等初始化为0。这里把dw变成一个向量,如图所示:

这里把dw变成一个n_x1维的向量,元素都为0。同时把对dw的迭代改成:
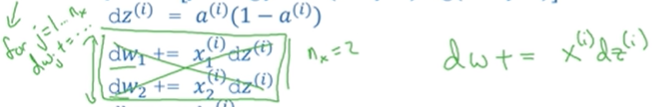
最后是改成,dw /= m。
2.10 向量化logistic回归
1、向量化实现logistic正向传播步骤:
如果你有m个样本,那么对第一个样本进行预测,需要这样计算:
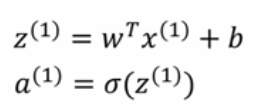
然后继续对第二个样本进行预测,需要这样计算:
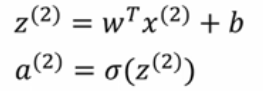
以此类推
可以看出,需要对m个训练样本都计算出结果,有个办法可以不需要任何一个显示的for循环。
首先记得我们曾定义过一个矩阵大写X,来作为输入矩阵,是一个nx* m矩阵
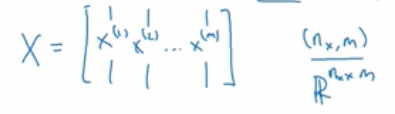
计算z(1),z(2),…,z(m)实际上只用了一行代码,首先要构建一个1* m的矩阵:
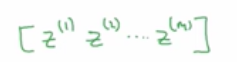
其实可以将其转化成w的转置乘以大写的矩阵X加上向量b。
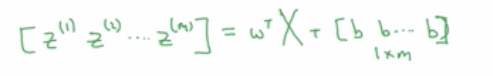
w转置是一个n维行向量,w转置乘以x(m)等于一个m维行向量:
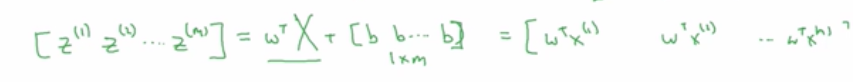
然后再加上第二项的b,则等于:
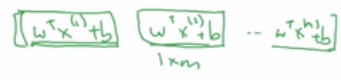
第一项即为z(1),第二项即为z(2),…,第m项即为z(3)。上述过程转换维numpy指令为:
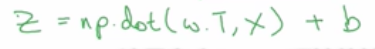
这里python的神奇之处在于,上式所加的b其实是一个实数,但当b加到上式中时,会自动转换成[b,b,b,…,b],这是一个m维的行向量。在python中叫广播。这里只用了一行向量来计算Z,Z是一个1* m维的行向量,包含所有小写z。那么把Z变成A呢,A = [a(1),a(2),a(3),…,a(m)]。使用sigma函数。
2、向量化实现logistic反向传播步骤:
向量化同时计算m个训练数据的梯度,dz的计算公式如下:

这里可以重新定义一个变量dZ:
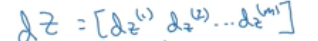
以及A,Y:

dZ = A-Y等于:
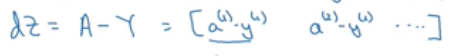
对于dw的计算之前已经解决掉了一个显示for循环,即把dw先初始化为一个nx * m维向量,并将元素全部赋值为0。按如下公式计算
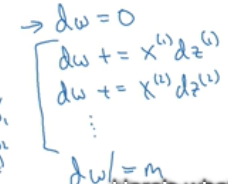
这就去掉了对于特征值dw1,dw2,…,dwm的计算,对于db的计算也是如此:
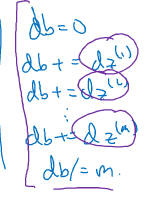
我们来消除第二个for循环,即对i的循环。对于db的计算可以总结为:

对于dw的计算我们可以总结为:
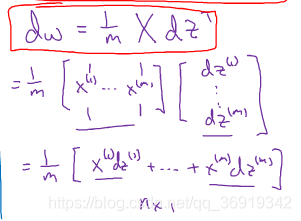
再次回顾之前没有向量化时进行logistic回归效率很低,向量化方法取消掉了之前代码中的两处for循环,全新代码如下:
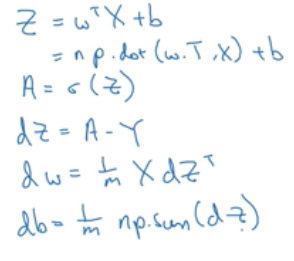
2.11 Python中的广播
1、几个例子
以下列子展示了来自100克不同食物中碳水化合物、蛋白质和脂肪的卡路里数量:
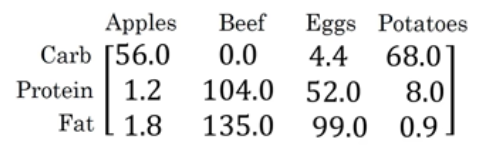
计算四种食物中卡路里有多少百分比来自碳水化合物、蛋白质和脂肪,比如100克苹果中碳水化合物有56卡路里、蛋白质有1.2卡路里、脂肪有0.9卡路里。总共加起来一共59卡路里,那么来自碳水化合物的卡路里占比为56/59大概是94.9%。
所以要做的就是对矩阵的列求和,并将每一行的数除以对应列的和,那么可以不用for循环做么?
对应python代码如下:
先将上述矩阵定义为A

再对矩阵A进行竖直相加:cal = A.sum(axis=0),aixs=0意味着竖直相加,水平轴是1.
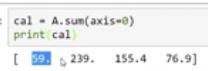
然后计算百分比:percantage = A/cal.reshape(1,4)*100,即用矩阵A除以上面那个1 * 4矩阵,其实cal已经是1 * 4矩阵,不需要reshape。
下面解释一下一个3 * 4矩阵是如何除以一个1 * 4矩阵的。
我们来看几个广播的例子,如果你取一个4 * 1向量让它和一个数字相加,python会做的是将这个数字自动展开,使其变成一个4 * 1向量:
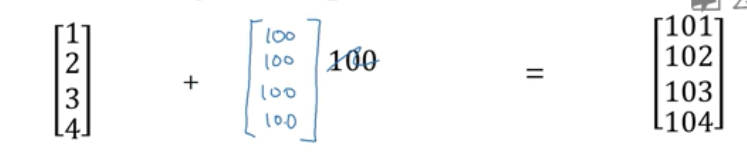
如果有一个m * n矩阵然后加上一个1 * n矩阵,python所做的是复制这个1 * n矩阵使其变成一个m * n矩阵。
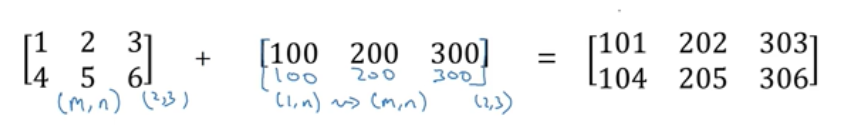
如果让一个m * n矩阵加上一个m* 1向量或者矩阵,然后水平复制n次,使其变成一个m * n矩阵:

2、Python广播中的一些通用规则
1、如果你有一个m * n矩阵然后你加上或者减去,乘以或者除以一个1 * n矩阵,那么python就会把它复制m次变成一个m * n矩阵。相反,如果你有一个m * n矩阵然后你加上或者减去,乘以或者除以一个m * 1矩阵,那么python就会把它复制n次变成一个m * n矩阵。
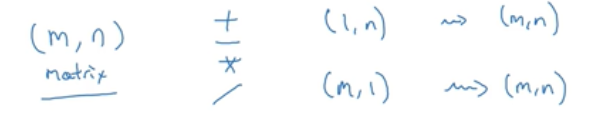
2、如果你有一个m * 1向量,加上或减去或乘以或除以一个实数,那么python会把这个实数复制m次直到你得到一个m * 1矩阵。类似的也适用于行向量
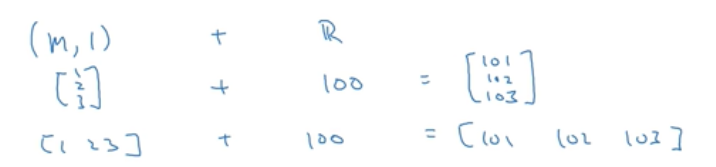
以上是实现神经网络算法主要用到的广播形式。
2.12 关于Python/numpy向量的说明
1、编写神经网络时尽量避免(n,)这种秩为1的数组,比如命令 a = np.random.randn(5),那么a.shape = (5,),这叫秩为1的数组。如果将a转置一下得到的还是一个秩为1的数组,当a乘上a的转置,得到的不是一个矩阵而是一个数。在编程过程中尽量不要用这种数据结构。每次要定义数组,最好把它定义成列向量,即:a = np.random.randn(5,1),a.shape =(5,1) ;或者一个行向量,即a = np.random.randn(1,5),a.shape = (1,5)。
2、当你不确定向量的维度就用一个assert(a.shape == (5,1))语句。
3、当你制造了一个秩为1的数组,可以用a = a.reshape转换成向量。

















 357
357

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









