







 本文详细介绍了VGG网络,探讨了其使用3x3卷积核、1x1滤波器、5个max_pool层的设计,以及在ImageNet等数据集上的应用。VGG网络通过加深网络层数,证实了增加网络深度对提升性能的有效性,但同时也带来了计算资源的消耗。此外,全连接层在测试阶段被转化为卷积层,使得网络能够处理不同尺寸的输入。
本文详细介绍了VGG网络,探讨了其使用3x3卷积核、1x1滤波器、5个max_pool层的设计,以及在ImageNet等数据集上的应用。VGG网络通过加深网络层数,证实了增加网络深度对提升性能的有效性,但同时也带来了计算资源的消耗。此外,全连接层在测试阶段被转化为卷积层,使得网络能够处理不同尺寸的输入。
VGG网络
【论文】:Very Deep Convolutional Network for Large-scale Image Recongination
介绍:在ILSVRC2014图像分类中获得第二名成绩,主要研究网络架构中深度的影响,并验证了增加更多的卷积层来稳定增加网络深度是可行的;并使用3*卷积滤波器代替之前网络(AlexNet)中较大的卷积滤波器,并证明在保持感受也大小不变的情况下,使用小滤波器组代替大滤波器,效果没有变差,对特征的表达能力还有增强,最重要的是参数成倍减少;并且使用更合理的网络权重初始化,加快了网络的收敛速度。
要点
1* 卷积组中出现连接几个卷积层堆叠,每一层都使用3×3卷积核(或1×1卷积核)
优点:保证了感受视野,减少了卷积层的参数
两个3×3 = 5×5 卷积
三个3×3 = 7×7 卷积
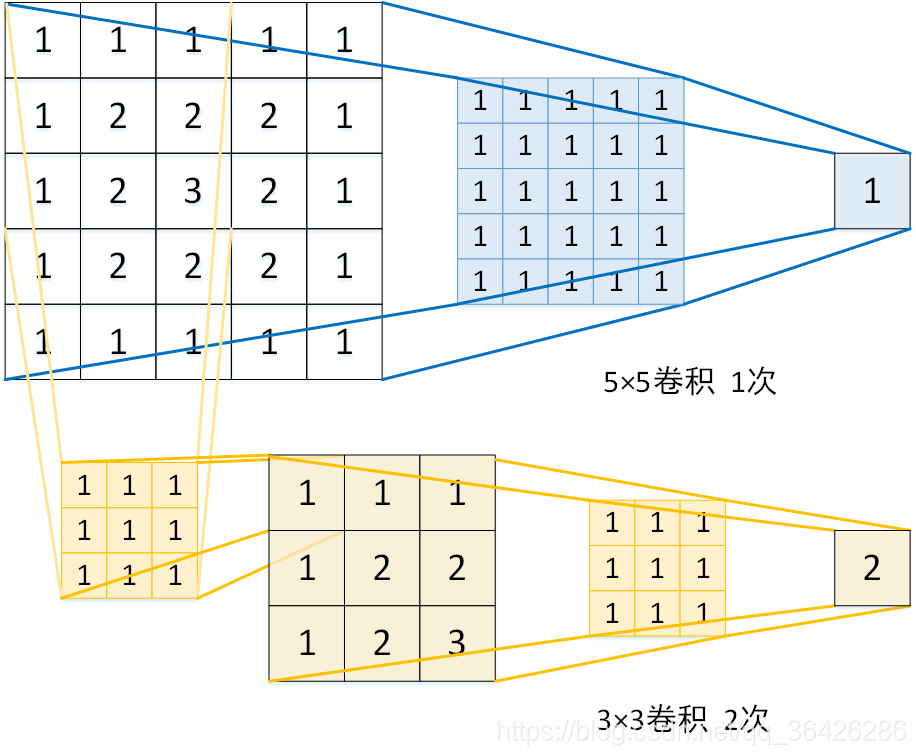
其中3个3×3 卷积与7×7 卷积参数个数,相当于大卷积参数个数的一半。
3(3²C²) = 27C²
7²C² = 49C²
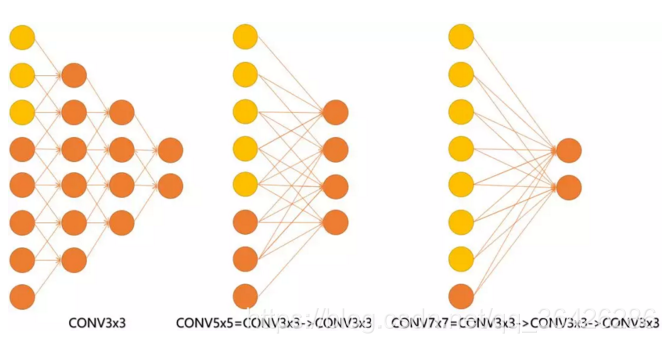
也可以说,三层的conv3x3的网络,最后两个输出中的一个神经元,可以看到的感受野相当于上一层是3,上上一层是5,上上上一层(也就是输入)是7。
结论:小滤波器
优点
1.参数少,拥有一样的感受野
2.三个卷积层叠加,经过更多次线性变换,对特征学习能力更强(采用卷积层和激活层交替结构)。
缺点
1.在进行反向传播时,中间卷积层可能会导致占用更多内存【疑问,不清楚为什么这样说】
2* 1×1滤波器
作用:在不影响输入输出维数的情况下,对输入进行线性形变,然后通过ReLU函数进行非线性处理,增加网络偶的非线性表达能力(pool::2×2,s=2);可以对feature map的channel级别降维或升维。
例:224×224×100经过20个1×1计算得到224×224×20
3* 5个max_pool层
进行5次卷积特征提取,卷积个数变化64、128、256、512、512,成2倍增长,最大512。
4* 应用数据集
ImageNet 1000类
cifar 100类 32×32(需要的网络更浅,全连接层也减少了)
5* 全连接转卷积
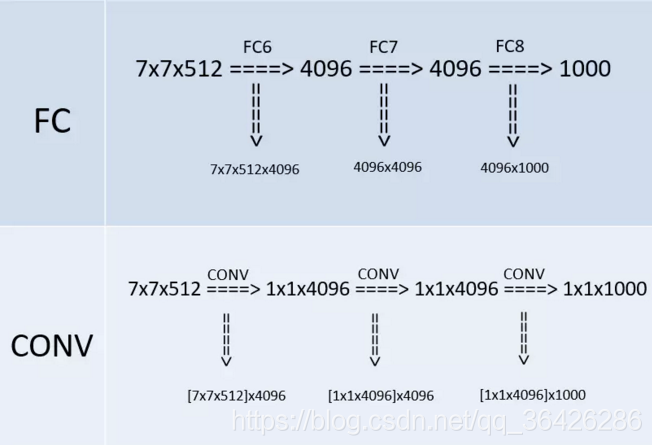
作者在测试阶段把网络中原本的三个全连接层依次变为1个conv7x7,2个conv1x1,也就是三个卷积层。改变之后,整个网络由于没有了全连接层,网络中间的feature map不会固定,所以网络对任意大小的输入都可以处理。
上图是VGG网络最后三层的替换过程,上半部分是训练阶段,此时最后三层都是全连接层(输出分别是4096、4096、1000),下半部分是测试阶段(输出分别是1x1x4096、1x1x4096、1x1x1000),最后三层都是卷积层。下面我们来看一下详细的转换过程(以下过程都没有考虑bias,略了):
先看训练阶段,有4096个输出的全连接层FC6的输入是一个7x7x512的feature map,因为全连接层的缘故,不需要考虑局部性, 可以把7x7x512看成一个整体,25508(=7x7x512)个输入的每个元素都会与输出的每个元素(或者说是神经元)产生连接,所以每个输入都会有4096个系数对应4096个输出,所以网络的参数(也就是两层之间连线的个数,也就是每个输入元素的系数个数)规模就是7x7x512x4096。对于FC7,输入是4096个,输出是4096个,因为每个输入都会和输出相连,即每个输出都有4096条连线(系数),那么4096个输入总共有4096x4096条连线(系数),最后一个FC8计算方式一样,略。
再看测试阶段,由于换成了卷积,第一个卷积后要得到4096(或者说是1x1x4096)的输出,那么就要对输入的7x7x512的feature map的宽高(即width、height维度)进行降维,同时对深度(即Channel/depth维度)进行升维。要把7x7降维到1x1,那么干脆直接一点,就用7x7的卷积核就行,另外深度层级的升维,因为7x7的卷积把宽高降到1x1,那么刚好就升高到4096就好了,最后得到了1x1x4096的feature map。这其中卷积的参数量上,把7x7x512看做一组卷积参数,因为该层的输出是4096,那么相当于要有4096组这样7x7x512的卷积参数,那么总共的卷积参数量就是:
[7x7x512]x4096,这里将7x7x512用中括号括起来,目的是把这看成是一组,就不会懵。
第二个卷积依旧得到1x1x4096的输出,因为输入也是1x1x4096,三个维度(宽、高、深)都没变化,可以很快计算出这层的卷积的卷积核大小也是1x1,而且,通道数也是4096,因为对于输入来说,1x1x4096是一组卷积参数,即一个完整的filter,那么考虑所有4096个输出的情况下,卷积参数的规模就是[1x1x4096]x4096。第三个卷积的计算一样,略。
总结
1.VGG优点
a. 结构简洁:3×3卷积,2×2池化
b. 使用小滤波器组代替大滤波器(B)
c. 验证了通过加深网络可以提升效果(A、B、C、D、E)
d.conv1×1的非线性变化有作用(C、D),更专注于通道特征融合,为全连接层做准备,使学习更加自然。
2.VGG缺点
a. 耗费更多计算资源,使用了更多参数(140M)
注:不是卷积层导致的问题,绝大多数参数来自于第一层全连接层。有实验发现全连接层对实验效果影响不大【不知道为什么,是用全卷积代替,还是直接去掉全连接层】。
b. 感受野:3个3×3的卷积层,在这个排列下,第一个卷积层中的每个神经元都对输入数据体有3×3的视野。【不理解Why】
3.总结:
a. 深层网络适合大数据集
b. 使用预训练的参数初始化可以加速网络训练
~注:前4个卷积核全连接是用A网络学习好的权重进行初始化,其他随机初始化
c. 收敛更快。VGG网络更深参数更多,但收敛更快。
~原因:
~1.更深的层,更小的核,相当于隐式进行正则化;
~2.训练的参数初始化采用更好的方法
参考:https://blog.youkuaiyun.com/qq_40027052/article/details/79015827

















 2538
2538

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









