




 现有语义分割方法用于高分辨率图像分割不准确,作者提出CascadePSP新方法,不使用高分辨率训练图像。该方法利用多个RM模块进行分割,测试阶段采用Global和Local Step,还公开BIG数据集用于高分辨率语义分割任务。
现有语义分割方法用于高分辨率图像分割不准确,作者提出CascadePSP新方法,不使用高分辨率训练图像。该方法利用多个RM模块进行分割,测试阶段采用Global和Local Step,还公开BIG数据集用于高分辨率语义分割任务。
CascadePSP: Toward Class-Agnostic and Very High-Resolution Segmentation via Global and Local Refinement
Abstract
目前的语义分割方法都是针对固定分辨率进行训练的,这些分割方式对于高分辨率的图像分割任务来说是不准确的,因为使用bicubic upsampling无法沿目标边界充分捕获高分辨率图像的细节。作者提出了一种不使用高分辨率训练图像进行训练,而是使用低分辨率图像进行训练以解决高分辨率图像分割的新方法(没有对模型进行微调)。
1.Intoduction
Code: https: //github.com/hkchengrex/CascadePSP.
本文贡献:
- 提出了CascadePSP
- 证明此模型可以生产高质量和非常高分辨率的分割‘
- 公开BIG数据集,用作高分辨率语义分割图像分割任务的公开数据集
2.Related Works
选择使用PSPNet中的空间金字塔的原因:此模块独立于输入分辨率,即使训练和测试分辨率不同也可以捕获全局的上下文信息。
Skip connection有利于捕获更精细的边界信息。
多尺度分析在很多计算机视觉任务中都利用了大尺度和小尺度特征。
3.CascadePSP
本文的cascade方法利用多个RM(refinement module)进行高分辨率得分割
3.1 Refinement Module
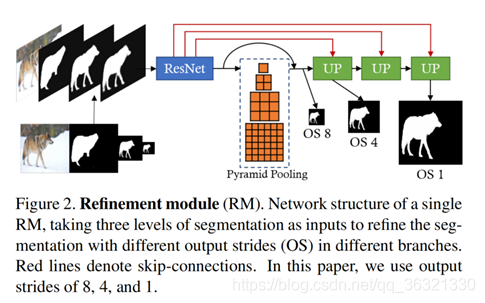
RM以拍摄图像和多个不同尺度不完善的分割mask作为输入,以生成精确的分割。
- 模型可以捕获不同级别的结构和边界信息
- 让网络自适应的去融合mask的特征
把所有低分辨率的mask上采样(双线性)到相同的大小,然后和拍摄图像进行concatenate。
使用带有ResNet50的PSPNet提取 stride=8 的特征图。传入[1,2,3,6]空间金字塔池化,捕获全局上下文。OS8与OS4特征专注于关注输入图像的整体结构。使用skip connection(concatenate)重建在提取过程中丢失的像素级的图像细节。
Loss函数:
对于stride=8的输出(较粗):使用交叉熵
对于stride=1的输出(较细):L1 + L2
对于stride=4的输出:交叉熵 + mean(L1+L2)
不同的损失函数适用于不同的步幅,因为粗略的refinement集中在全局结构上,而忽略了局部细节,而精确的refinement通过依赖局部线索来实现像素级精度。
为了进一步提高分割边界的精度,在stride=1的输出上还采用了L1 loss on segmentation gradient magnitude。分割梯度由3×3的平均滤波器+Sobel算子进行估计。 梯度损失使输出在像素级别更好地粘附(adhere)到目标边界。 由于与像素级损失相比,梯度较稀疏,因此我们将其加权为α,在我们的实验中将其设置为5。
x_kernel = np.array([[1, 0, -1], [2, 0, -2], [1, 0, -1]])/4
y_kernel = np.array([[1, 2, 1], [0, 0, 0], [-1, -2, -1]])/4
X -> avg_pool2d -> x_kernel -> grad_x
X -> avg_pool2d -> y_kernel -> grad_y
X = sqrt(grad_x ^ 2 + grad_y ^ 2)
梯度损失:
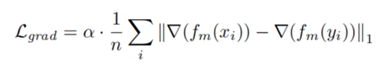
其中fm(·)表示3×3均值滤波器,∇表示由Sobel运算符近似的梯度算子,n是像素总数,xi和yi是第i个 GT和Predict 。我们的最终损失可以写成:
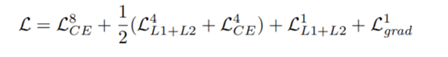
RM的消融实验:
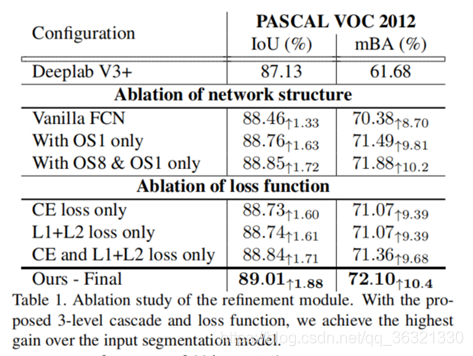
评价指标:IoU 。为了突出显示边界精度,提出了一种新的平均边界精度度量(mBA)。
为了对不同大小的图像进行鲁棒的估计,我们以均匀的间隔在[3,(w + h) /300]中对5个半径进行采样,将距离GT边界的每个半径内的分割精度进行计算,然后对这些值取平均值。
表1显示CascadePSP在IOU和mBA上的显著改善。
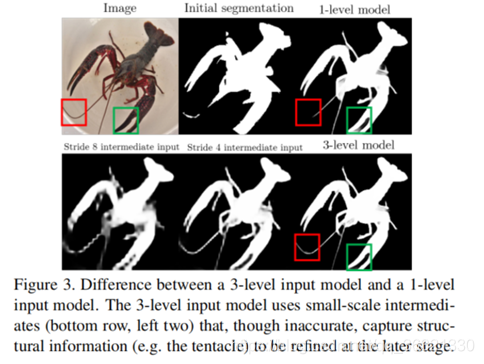
使用多级级联(multi-level cascade),RM可以将不同尺度的refinement阶段委托给不同的尺度(scale)。 如图3所示,3级模型可以更好地利用结构线索来产生更详细的边缘分割效果。
3.2Global and Local Cascade Refifinement
测试阶段使用Global Step(考虑整个图像来修复结构)和Local Step(使用图像裁剪来修复细节).注意使用的是相同的RM模块。
3.2.1 Global Step

Glocal step在整个图像上使用三级cascade来进行refine。因为在测试阶段高分辨率的图像无法直接放在GPU中进行处理,所以先对输入图像进行下采样,下采样过后的长轴长为L,长宽比保持一定。
cascade的输入使用input segmentation进行初始化,然后将其复制以保持输入通道维度恒定。 在cascade的第一级之后,一个输入通道将被双线性向上采样的粗略输出代替。 重复此操作直到最后一个级,最后一级中输入既包含初始分割又包含来自先前级别的所有输出。
这种设计使我们的网络能够逐步修复分割错误,同时在初始分割中保留详细信息。 使用多个级别,我们可以粗略地描述对象并在粗略级别中修复较大的误差。
3.2.2 local Step

图5说明了Local step的细节。 由于内存限制,即使使用现代GPU,也无法单次处理非常高分辨率的图像。 而且,训练和测试数据之间分辨率规模的急剧变化将导致分割结果变差。 我们利用级联模型首先使用降采样后的图像执行global refinement,然后使用来自高分辨率图像的图像裁剪执行local refinement。 这些裁剪的图像使“local step”无需高分辨率训练数据即可处理高分辨率图像,同时由于“global step”而将图像上下文考虑在内。
在local step中,模型使用Global Step最后一级的两个输出,分别表示为S41和S11。
这两个输出均被双线性调整为图像的原始尺寸W×H。模型采用尺寸为L×L的图像裁切,并且从裁切输出的每一侧切掉16个像素(避免 boundary artifacts)。
均匀地以L / 2- 32的步幅进行裁剪,使得图像中大部分的像素被四个Crop覆盖,并且超出图像边界的无效Crop将移动以与图像的最后一行/列对齐。
然后将图像Crop送入2级cascade,输出stride分别为4和1。 融合时,由于图像上下文不同,不同patches的输出可能会彼此不一致,我们通过对所有输出值求平均值来解决此问题。 对于分辨率更高的图像,我们可以采用从粗到细(coarse-to-fine)的方式递归地应用local step。
3.2.3 Choosing L
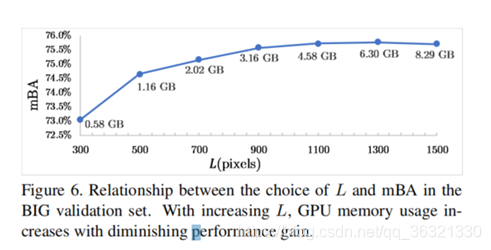
为了平衡GPU的使用量和mBA,选择L=900
3.2.4 Global和Local Step的消融实验

删除Global Step的时候,IoU的下降比较明显,说明Global Step主要固定总体的结构。
Local Step关注上下文的细节,虽然IoU略微降低,但是边界的精度会严重缺失。

图7研究了Local Step对于不同分辨率输入的重要性:通过调整BIG验证集的大小而生成的各种大小的分割图中,我们评估了有无Local step的方法。 尽管Global Step足以用于低分辨率输入,但local Step对于图像尺寸大于900的分割任务至关重要。
3.3 Training
Global Step中的每一cascade都计算损失
对GT进行随机扩张以及随机腐蚀


















 1455
1455

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









