




 本文聚焦语义分割,指出当前基于空洞卷积的全卷积网络计算复杂、内存消耗大,Encoder - Decoder结构性能不足。为此提出EfficientFCN,引入Holistically - guided Decoder,结合多尺度特征图优势,降低计算成本至1/3,在三个公开数据集上实现较高分割精度。
本文聚焦语义分割,指出当前基于空洞卷积的全卷积网络计算复杂、内存消耗大,Encoder - Decoder结构性能不足。为此提出EfficientFCN,引入Holistically - guided Decoder,结合多尺度特征图优势,降低计算成本至1/3,在三个公开数据集上实现较高分割精度。
Abstract
分割网络的性能和效率都对语义分割很重要。 最新的语义分割算法主要是基于空洞卷积的全卷积网络(dilatedFCN),该网络在骨干网络中使用空洞卷积来提取高分辨率特征图,以实现高性能的分割性能。由于在高分辨率特征图上进行了许多卷积操作,所以基于dilatedFCN的方法会导致较大的计算复杂性和内存消耗。
目前的Encoder-Decoder结构的性能无法与DilatedFCN网络相比,本文提出EfficientFCN,主干网络是ImageNet预训练没有(没有空洞卷积),从encoder中获得了多尺度的特征图以得到高分辨率语义丰富的信息,decoder中引入了holistically-guided decoder。Decoder任务被转换为novel codebook generation和codeword assembly task。 计算成本只有原来的1/3,获得与圆回来相当或者更好的性能。
Introduction
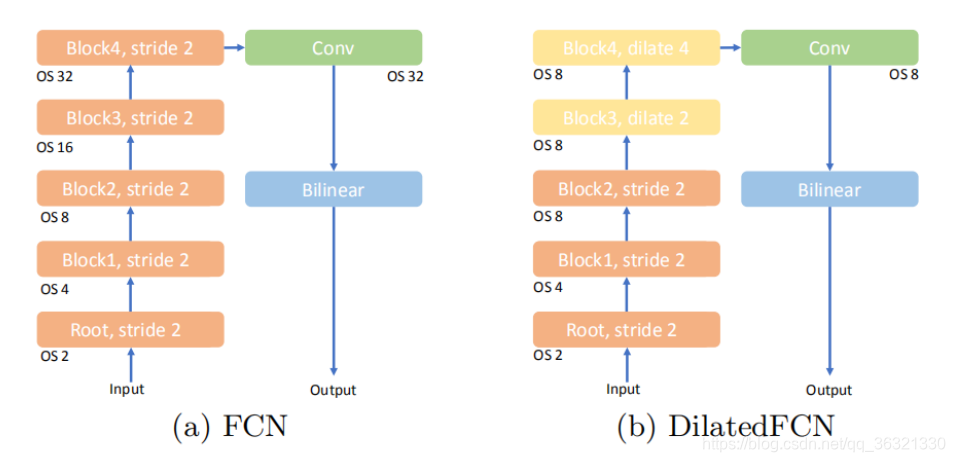
OS:output stride
(a)首次在语义分割中使用全卷积网络,使用DCNN作为特征编码器提取高级的语义信息,然后使用卷积层生成分割结果图。
高分辨率的特征图对于提高分割网络性能来说非常重要,因为他们包含详细的结构信息以及清晰的边界信息。连续的池化和strided convolution操作会降低特征图的分辨率,其中的细粒度结构(fine-grained structural)信息被丢失,此时会降低分割网络的性能。
为了解决这个问题,使用空洞卷积是一个办法,扩大感受野(receptive field)同时保持高级特征图的分辨率。但是需要很高的计算复杂度和内存消耗。
(c)中的encoder-decoder结构可以有效的获得高分辨率特征表示,但是细粒度的结构特征在OS=32的最高级的特征图中就已经丢失了。解码器主要使用双线性上采样或者反卷积操作来提高高级特征图的分辨率。这些操作以局部的方式进行,上采样特征图的每个位置的特征向量都从有限的接收域中获得。所以Encoder-Decoder结构的性能无法与dilatedFCN相提并论。
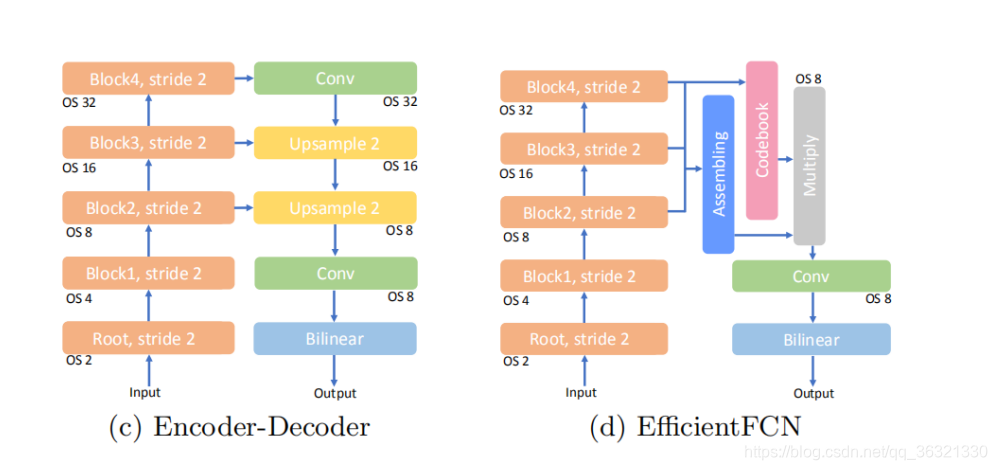
为了解决上面这两种类型的模型中的缺点,我们提出了带有Holistically-guided Decoder(HGD)的EfficienFCN(如(d)所示),以弥补基于空洞卷积FCN的方法与encoder-decoder之间的差距。 我们的网络可以采用任何没有空洞卷积的广泛使用的分类模型作为编码器(例如ResNet模型)来生成低分辨率的高级特征图(OS = 8)。 这样的编码器比DilatedFCN模型中的编码器在计算和存储效率上都高。
给定来自编码器最后三个块的多级特征图,所提出的holistically-guided同时具有高级低分辨率特征图(OS = 32)和中级高分辨率特征图的优势(OS = 8,OS = 16),以实现具有丰富语义的特征的高级特征上采样。直观地讲,高分辨率特征图包含更多细粒度(fine-grained)的结构信息,这有利于在空间上引导特征提升过程。 低分辨率特征图包含更多高级语义信息,这些信息更适合于有效地编码全局上下文。因此,我们的HGD在codebook中生成一系列holistic codewords,以总结来自低分辨率特征图(OS=32)输入图像的不同全局和高级方面。
可以将这些codewords正确地组合在高分辨率网格中,以形成具有丰富语义信息的上采样特征图。 遵循此原理,HGD从中级高分辨率特征图(OS = 8,OS = 16)生成汇编系数(assembly coefficients),指导在每个高分辨率空间位置处linear assembly的线性组合,实现特征图上采样。 我们提出的带有holistically-guided decoder的EfficientFCN在三个公开数据集上实现了较高的分割精度,这证明了我们提出的解码器的效率和有效性。
本文贡献:
(1)我们提出了一种新的holistically-guided decoder,该解码器可以考虑输入图像的整体上下文来有效地生成高分辨率特征图。
(2)EfficientFCN进行不适用空洞卷积的解码操作,但仍可以实现出色的性能。
(3)与最新的空洞FCN的方法相比,我们的EfficientFCN获得了更好的结果,而FLOPS却减少了1/3。
Related Work
近年来对于FCN的改进主要基于两种方法,dilatedFCN和encoder-decoder结构。
dilatedFCN:Deeplab V2 通过在主干网络中使用空洞卷积来学习高分辨率特征图,从而将output stride从32增加到8。但是,主干网络最后两层中的空洞卷积运算量较大并且显存占用量也巨大。
基于空洞卷积的主干网络,前人提出了很多方法来获得更丰富的上下文特征图。
许多工作继续采用不同的策略作为分割头来获取上下文增强的特征图。 PSPNet利用Spatial Pyramid Pooling(SPP)模块来增加接收场。 EncNet提出了一个编码层,用于从全局上下文中预测feature re-weighting vector,并有选择地突出相关类的特征图。 CFNet利用aggregated co-occurrent feature(ACF)模块通过特征空间中的成对相似性(pair-wise)来聚集(aggregated)co-occurrent上下文。 Gated-SCNN 提出使用一种新的gating mechanism来连接中间层和一个新的损失函数,该函数利用语义分割和语义边界预测任务之间的对偶性(duality)。 DANet提出使用带有self-attention mechanism的两个注意力模块分别聚合来自空间和通道维度的特征。ACNet 将带有空洞卷积的ResNet作为主干主干网络,并结合了encoder-decoder策略观察到:来自高级的特征的全局上下文有助于对较大的分割区域进行分类,而来自较低的局部上下文有助于生成清晰的边界信息或者细节信息。DMNet从多尺度邻域(multi-scale neighborhoods)生成了一组大小不同的动态过滤器,用于处理目标的尺度变化以进行语义分割。
尽管这些工作进一步提高了不同基准上的性能,但这些创新为已经很复杂的编码器增加了额外的计算成本。
encoder-decoder:
另一类方法专注于通过encoder-decoder结构有效地获取高分辨率语义特征图。
通过上采样操作和跳过连接,encoder_decoder结构可以逐步恢复高分辨率特征图进行分割。
DUsampling设计了一个基于数据的上采样模块,该模块基于完全连接的层,用于根据低分辨率特征图构建高分辨率特征图。 FastFCN 提出了一种通过multiple空洞卷积的Joint Pyramid Upsampling(JPU)方法来生成高分辨率特征图的方法。 这些方法的一个共同缺点是,仅通过局部特征融合来构造上采样的高分辨率特征图的每个位置处的特征。 这样的特性限制了它们在语义分割网络中的性能,而全局上下文对于最终的性能很重要。
Proposed Method
在本节中,我们首先对基于encoder-decoder的方法进行全面分析。 然后,为了解决传统encoder-decoder方法中的问题,我们提出了EfficientFCN,它基于传统的ResNet作为用于语义分割的编码器主干网络。 在我们的EfficientFCN中,Holistically-guided Decoder(HGD)从ResNet编码器主干网络的最后三个块中的三个特征图中恢复高分辨率(OS = 8)特征图。
在最新的DCNN骨干网络中,早期的高分辨率中级特征图可以更好地编码细粒度(fine-grained)的结构,而后期的低分辨率高级特征通常对类别更具区分性。 它们是实现精准语义分割的必重要信息。 为了结合这两类特征图的优势,开发了encoder-decoder结构来重建高分辨率特征图,高分辨率特征图具有来自多尺度特征图的丰富的语义信息。
为了产生用于mask预测的OS = 8的最后的特征图![]() ,传统的三级编码器-解码器首先对OS = 32的最深的编码特征图f32进行上采样生成OS = 16的特征图f16。 来自编码器的相同大小的OS = 16特征图e16直接concatenate成[f16; e16](U-Net)或加和为f16 + e16接1x1卷积生成OS=16上采样特征图
,传统的三级编码器-解码器首先对OS = 32的最深的编码特征图f32进行上采样生成OS = 16的特征图f16。 来自编码器的相同大小的OS = 16特征图e16直接concatenate成[f16; e16](U-Net)或加和为f16 + e16接1x1卷积生成OS=16上采样特征图![]() ,相同的上采样+跳过连接过程再次重复执行
,相同的上采样+跳过连接过程再次重复执行![]() 生成
生成![]() 。 上采样的特征
。 上采样的特征![]() 在某种程度上包含中级和高级信息,并且可以用于生成segmentation masks。 但是,由于传统的解码器中的双线性上采样和反卷积是具有有限接收场的局部运算。 我们认为,它们无法探索输入图像的重要全局背景,这对于实现准确的分割至关重要。
在某种程度上包含中级和高级信息,并且可以用于生成segmentation masks。 但是,由于传统的解码器中的双线性上采样和反卷积是具有有限接收场的局部运算。 我们认为,它们无法探索输入图像的重要全局背景,这对于实现准确的分割至关重要。
虽然目前已有一些尝试使用全局上下文来重新加权(re-weight)主干网络或上采样特征图中不同通道的贡献,但是这种策略仅缩放每个特征通道,但保持原始空间大小和结构。 因此,无法生成高分辨率、语义丰富的特征图来改善细粒度结构的恢复。
为了解决此缺点,我们提出了一种新的Holistically-guided Decoder(HGD),它将特征上采样任务分解为从高级特征图中生成一系列整体码字(holistic codewords)以捕获全局上下文,并在每个语义丰富的特征上采样的空间位置线性组合这些codeworks。 这样解码器可以利用全局上下文信息来有效地引导特征上采样过程,并且能够恢复细粒度的细节。 基于提出的HGD,我们提出了一种EfficientFCN(如图1(d)所示),该编码器带有一个没有空洞卷积的有效编码器,可以进行有效的语义分割。
3.2 Holistically-guided Decoder for Semantic-rich Feature Upsampling
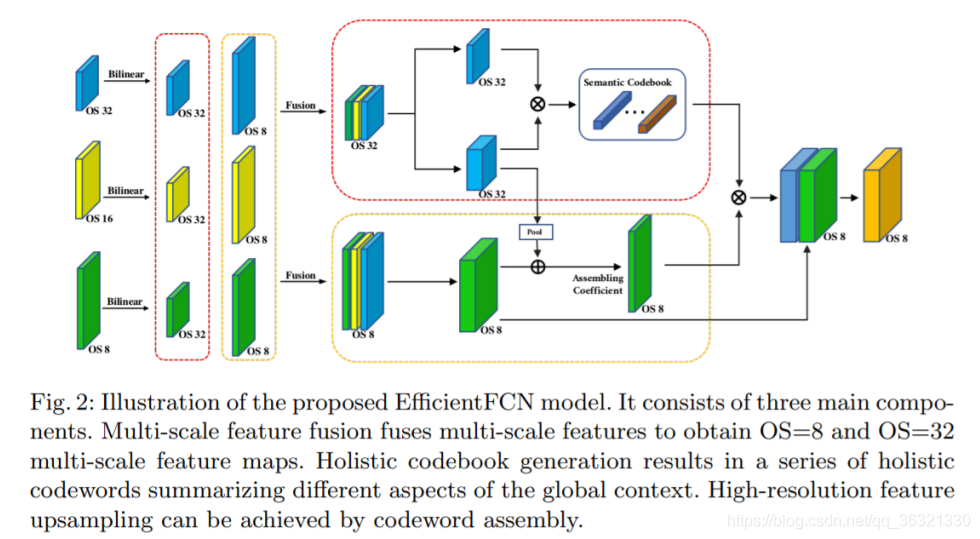
设计思路:要充分利用大小OS=32的低分辨率高级特征图和OS=8和OS=16的高分辨率中级特征图。高级特征图丢失了大部分的结构细节,但是有丰富的类别信息。
Holistically-guided decoder包含三个主要的部分:multi-scale feature fusion, holistic codebook generation, and codeword assembly for high-resolution feature upsampling
(1)多尺度特征融合
对于来自编码器的OS = 8,OS = 16,OS = 32特征图,我们首先采用单独的1×1卷积将其每个通道压缩到512,以降低后续的计算复杂度,从而分别获得e8,e16,e32。 然后,通过将e8,e16下采样到OS = 32的大小,并沿着通道维度将它们与e32 concatenate,得到多尺度融合OS = 32特征图![]()
其中↓表示双线性下采样,[]表示沿通道尺寸的concatenate,H和W分别是输入图像的高度和宽度。
同理获得多尺度融合OS=8的特征图
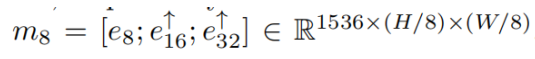
(2)Holistic codebook generation
尽管创建了多尺度融合特征图m32来同时集成(integrate)高级和中级特征,但是它们的低分辨率却使它们失去了场景的许多结构细节。 另一方面,由于e32从最深层编码器得到的,因此m32能够编码图像的丰富分类表示。 因此,我们提出从m32生成一系列无序的整体代码字(unordered holistic codewords),以隐式建模全局上下文的不同方面。 为了生成n个整体码字(holistic codewords),首先从融合的多尺度特征图m32计算一个codewords base map ![]() 和n个空间权重图
和n个空间权重图![]() 。融合的多尺度,后面分别接两个单独的1×1卷积。 对于base map B,我们将
。融合的多尺度,后面分别接两个单独的1×1卷积。 对于base map B,我们将![]() 表示为位置(x,y)的1024-d特征向量; 对于空间权重图A,我们使用
表示为位置(x,y)的1024-d特征向量; 对于空间权重图A,我们使用![]() 表示第i个加权图。
表示第i个加权图。
为了确保权重图A正确归一化,采用softmax函数将每个通道i的所有空间位置(第i个空间特征图)归一化为
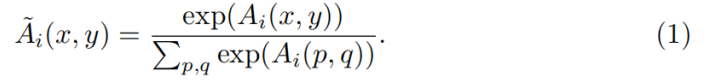
把获得的第i个codeword ![]() 作为所有codeword bases
作为所有codeword bases![]() 的加权平均值,即
的加权平均值,即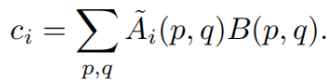
换句话说,每个空间权重图![]() 学习线性组合来自所有空间位置的所有代码字库(codeword bases)B(x,y)以形成单个codeword,其捕获全局上下文的某些方面。 n个权重图最终导致n个整体码字(holistic codewords)
学习线性组合来自所有空间位置的所有代码字库(codeword bases)B(x,y)以形成单个codeword,其捕获全局上下文的某些方面。 n个权重图最终导致n个整体码字(holistic codewords)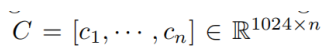 ,以对高级全局特征进行编码.
,以对高级全局特征进行编码.
(3)Codeword assembly for high-resolution feature upsampling
Holistic codewords可以捕获输入图像的各种全局上下文。 它们是从高级特征m32编码而来的,并且是重构高分辨率语义丰富的特征图的重要因素。 但是,由于在codeword编码期间大部分结构信息已被删除,因此我们转向使用OS = 8多尺度融合特征m8来预测每个空间位置上n个codewords的线性组合系数,以创建高分辨率特征图 。 更具体地说,我们首先创建原始码字汇编指导特征图( raw codeword assembly guidance feature map) 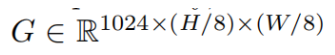 来预测每个空间位置的组合系数(assembly coefficients),这些系数是通过在多尺度融合特征图m8上使用1x1的卷积得到的。但是,OS = 8融合特征m8没有关于整体代码字(holistic codewords)的信息,因为它们都是从m32生成的。 因此,我们将一般代码字(general codeword)信息视为codeword based map
来预测每个空间位置的组合系数(assembly coefficients),这些系数是通过在多尺度融合特征图m8上使用1x1的卷积得到的。但是,OS = 8融合特征m8没有关于整体代码字(holistic codewords)的信息,因为它们都是从m32生成的。 因此,我们将一般代码字(general codeword)信息视为codeword based map ![]() 的全局平均向量,并将其按位置加到raw assembly guidance feature map中,以获得新的的指导特征图(guidance feature map)
的全局平均向量,并将其按位置加到raw assembly guidance feature map中,以获得新的的指导特征图(guidance feature map)![]() ,其中⊕表示按位置加法。 对指导特征图(guidance feature map)
,其中⊕表示按位置加法。 对指导特征图(guidance feature map)![]() 进行的另一次1×1卷积生成了所有(H / 8)×(W /8)空间位置 上 n个codewords
进行的另一次1×1卷积生成了所有(H / 8)×(W /8)空间位置 上 n个codewords ![]() 的线性组合权重。 通过将权重图W reshape 为
的线性组合权重。 通过将权重图W reshape 为![]() 矩阵,可以很容易地获得整体引导(holistically-guided)的上采样特征
矩阵,可以很容易地获得整体引导(holistically-guided)的上采样特征![]()
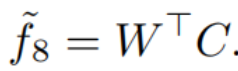
给定整体引导(holistically-guided)的上采样特征图![]() ,我们通过将特征图
,我们通过将特征图![]() 与指导特征图(guidance feature map)G进行concatenating 来重建最终的上采样特征图
与指导特征图(guidance feature map)G进行concatenating 来重建最终的上采样特征图![]() 。这样的上采样特征图
。这样的上采样特征图![]() 同时具有m8和m32的优点,并且包含语义丰富且结构信息完整的特征,可实现准确的细分。
同时具有m8和m32的优点,并且包含语义丰富且结构信息完整的特征,可实现准确的细分。

















 7654
7654

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









