









 本文介绍了如何利用PaddleHub中的基于文本提示的语义分割模型进行快速、灵活的图像抠图,包括模型安装、命令行和代码调用方法,以及效果展示和参考资料。
本文介绍了如何利用PaddleHub中的基于文本提示的语义分割模型进行快速、灵活的图像抠图,包括模型安装、命令行和代码调用方法,以及效果展示和参考资料。
1. 介绍
传统的图像语义分割模型通常固定类别进行分割,而基于文本提示的语义分割模型则具有更高的灵活性。本文介绍的模型允许用户通过输入文本标签来手动控制分割的类别信息,从而实现快速抠图的需求。
2. 效果展示
通过控制文本标签,模型能够快速、精准地抠出特定物体,以下是部分抠图效果展示:
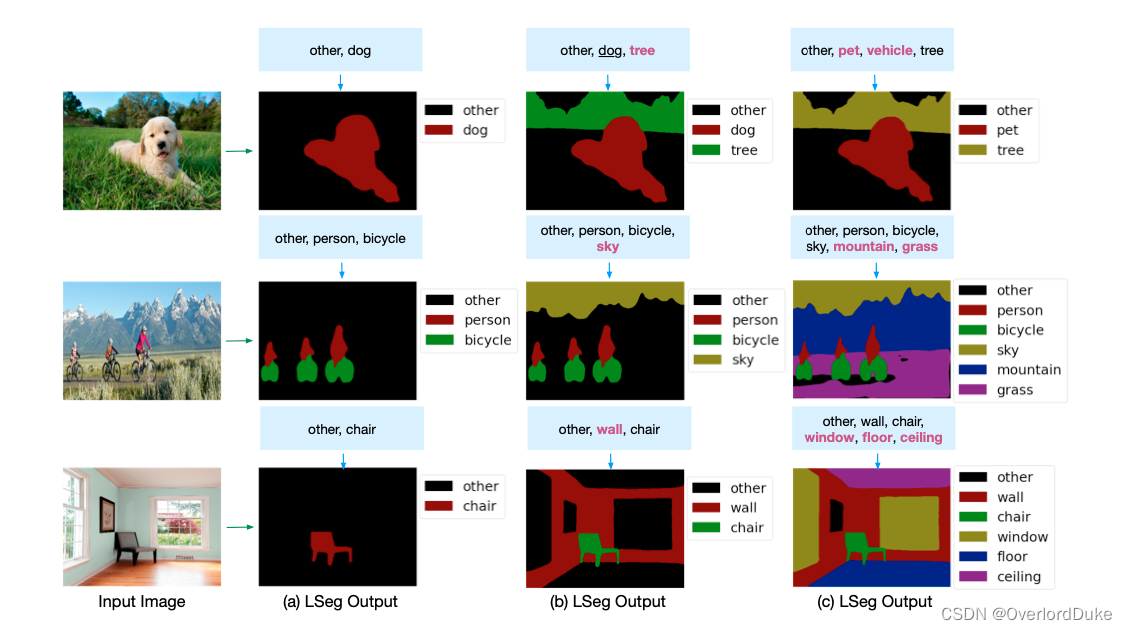
3. 安装模型
使用 PaddleHub 可以便捷地安装该语义分割模型:
!pip install --upgrade paddlenlp
!hub install lseg
4. 命令行调用
通过简单的命令行指令即可快速调用模型进行抠图:
!hub run lseg \
--input_path "images/cat.jpeg" \
--labels 'cat' 'other' \
--output_dir "lseg_output"
文本标签支持中英文,模型会自动翻译至英文输入。
5. 代码调用
5.1 模型加载
import paddlehub as hub
module = hub.Module(name="lseg")
5.2 可视化函数定义
import cv2
import numpy as np
from PIL import Image
def vis(results):
result = np.concatenate([
results['color'],
results['mix']
], 1)
return Image.fromarray(result[:, :, ::-1])
5.3 图像语义分割
# 定义图像路径 / 类别 / 保存路径
image_path = 'images/cat.jpeg'
labels = ['plant', 'grass', 'cat', 'stone', 'other']
output_dir = 'lseg_output'
# 图像分割
results = module.segment(
image=image_path,
labels=labels,
visualization=True,
output_dir=output_dir
)
# 可视化
vis(results)
或者直接使用 numpy.ndarray BGR 格式的图像:
# 定义图像路径 / 类别 / 保存路径
image_path = 'images/cat.jpeg'
labels = ['plant', 'grass', 'cat', 'stone', 'other']
output_dir = 'lseg_output'
# 图像分割
results = module.segment(
image=cv2.imread(image_path),
labels=labels,
visualization=True,
output_dir=output_dir
)
# 可视化
vis(results)
6. 参考资料
- 论文:Language-driven Semantic Segmentation
- 官方实现:isl-org/lang-seg
- AIStudio 介绍:Lang-Seg:文本驱动的图像语义分割
7. 结语
以上是基于文本提示的语义分割快速抠图模型的介绍与实践。希望本文能够对您有所帮助,若有任何疑问或建议,欢迎留言交流!
服务
🛠 博主提供一站式解决方案,让您的工作变得更加轻松、高效!以下是我们提供的服务:
-
代部署
🚀 为您提供快速、稳定的部署方案。无论是您的应用程序、网站还是其他软件项目,我们都可以帮助您将其部署到适当的平台上。
-
课程设计选题
📚 为您量身定制符合课程要求和学生需求的选题方案。无论是基础课程还是高级课程,我们都能够为您提供专业的建议和支持。
-
线上辅导
💻 提供线上辅导服务,为您提供个性化的指导和支持,帮助您解决在学习、工作或研究中遇到的各种问题和困难。
如有需求,请随时私信


















 877
877

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











