







 这篇博客探讨了如何在数据分析中检测和处理重复数据。以一个具体的例子展示,通过使用Pandas库的duplicated()函数,找出并标记DataFrame中用户编号和统计日期组合的重复行。案例中,用户'小明'在11.12的消费记录出现不一致,被识别为异常数据。通过插入新列'is_dup'并筛选,可以有效地定位并分析这些异常。
这篇博客探讨了如何在数据分析中检测和处理重复数据。以一个具体的例子展示,通过使用Pandas库的duplicated()函数,找出并标记DataFrame中用户编号和统计日期组合的重复行。案例中,用户'小明'在11.12的消费记录出现不一致,被识别为异常数据。通过插入新列'is_dup'并筛选,可以有效地定位并分析这些异常。
示例:
df = pd.DataFrame({
'用户编号': ['小明', '小明', '小王', '小美', '小张', '小王'],
'统计日期': ['11.12', '11.12', '11.12', '11.12', '11.13', '11.13'],
'消费金额': [4, 3, 5, 10, 2, 5]
})
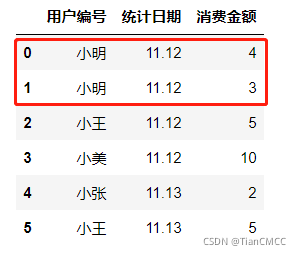
可见用户 “小明”,在11.12当日产生的消费金额不一致,因此判断为异常数据,将其找出:
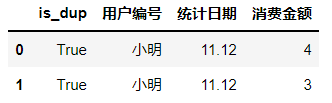
dup_row = df.duplicated(subset=['用户编号', '统计日期'], keep=False)
df.insert(0, 'is_dup', dup_row)
df[df['is_dup'] == True]

















 992
992

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









