






 S3FD算法,一种高效的人脸检测方法,借鉴SSD模型并进行多项创新改进,包括采用Scale-equitable框架确定多层特征图上的anchor尺度,提出Scale补偿anchor匹配策略提高小尺度人脸召回率,及Max-out背景标签策略减少误检。
S3FD算法,一种高效的人脸检测方法,借鉴SSD模型并进行多项创新改进,包括采用Scale-equitable框架确定多层特征图上的anchor尺度,提出Scale补偿anchor匹配策略提高小尺度人脸召回率,及Max-out背景标签策略减少误检。
S3FD用于人脸检测,当然其思想适用于目标检测的其他领域。该算法借鉴了SSD模型,主要做了以下几个改进:
1.Scale-equitable framework
根据特征图的感受野和equal proportion interval principle(等比例间隔策略)来确定每层特征图上anchor的尺度。实际上的做法就是确保多层feature map上anchor的尺度和anchor的采样间隔stride size的比值为4(感觉这里和SSD有所不同,比较SSD应该是在每一块区域的中心都生成大小各异的anchor),下图是anchor大小、步长以及感受野大小的数据:
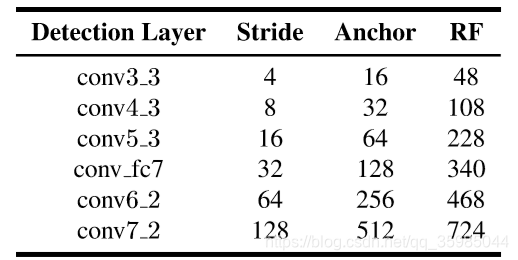
这里anchor大小明显小于感受野,是因为我们的anchora大小对标的是有效感受野。
理论感受野:TRF,theoretical receptive field,表示理论上输入图像区域对feature map上某个点值的影响;对于 feature map上某个点,TRF的计算公式可自行搜索。
有效感受野:ERF,effective receptive field:只有一部分(如高斯分布区域)对feature map上某个点的值有较大的贡献;其大小比理论感受野小。
2.Scale compensation anchor matching strategy
作者提出了尺度补偿的anchor匹配策略。
anchor scales are discrete while face scales are continuous, these faces whose scales distribute away from anchor scales can not match enough anchors, leading to their low recall rate.
1) the average number of matched anchors is about 3 which is not enough to recall faces with high scores;
2) the number of matched anchors is highly related to the anchor scales. The faces away from anchor scales tend to be ignored,leading to their low recall rate.
由上述原文可知,作者认为人脸的尺度是连续的,但anchor的尺度则是离散的,这样导致对小尺度人脸和部分离群尺度 ( 人脸ground truth大小刚好不在预先设置好的的anchor的大小附近 ) 的ground truth,没有足够的anchor与它们匹配,进而影响到召回率。作者提出了两个方法解决上述问题:
(1)将anchor和groud truth的IOU阈值thresh从0.5降低至0.35;
(2)经过上述步骤之后,再把IOU大于0.1的anchor按IOU进行排序,选出Top-N。
3.Max-out background label
conv3_3上为检出小尺度人脸,预定义了很多小尺度anchor,然而大部分anchor都是背景,会造成很多false positive rate,进而影响到了检准率,作者提出了Max-out background label 来解决上述问题;
For each of the smallest anchors, we predict Nm scores for background label and then choose the highest as its final score
之前每个框只预测1次背景值, 现在预测3次, 然后取分值最高的作为背景的分数值. 那么被分为背景的概率就大大增加了
training部分有时间的话再写。。。。

















 2万+
2万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









