







在上一节中,我们概况性地介绍了强化学习,最后我告诉大家,我们不能将RL直接用于处理某个问题,而完全不了解正确设置问题的含义。要入门,则应该了解RL工作流,以及该流程的每个部分如何有助于解决问题,以及在此过程中必须做出哪些决策。在本节,我们将在了解强化学习基本知识的基础上,进—步探索创建问题的含义。
我曾经说过,强化学习的第一步是理解你试图控制的系统,因为如果传统的控制方法更好用,你就不需要选择强化学习。不过,我认为如果你对RL工作流有很好的理解,将更容易作出选择。
现在,假设我们已确定要使用强化学习。在打好基础后,我们将在后续文章中,讨论不需要使用强化学习的场景。好的,让我们开始介绍RL的工作流。
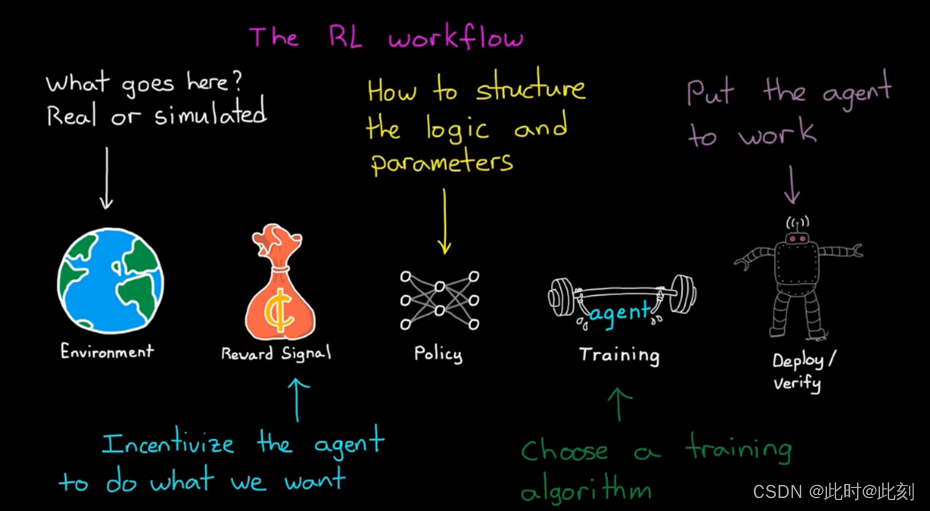
我们需要一个可以让智能体学习的环境,因此,我们需要选择环境中应该存在什么,以及是模拟仿真,还是真实的物理设备。然后我们需要思考最终想要智能体做什么,并设计奖励函数来激励智能体,按照期望执行任务。我们需要选择一种表示策略的方法,并且希望构造智能体,即决策部分包含的参数和逻辑。在确立了这种方法后,我们需要选择训练算法,并着手寻找最优策略。最后,我们需要利用策略,将其部署到现场的智能体,并验证结果。
为了正确理解这个工作流,让我们结合两个例子来考虑每一步骤:平衡倒立摆和机器人行走控制。
so,我们开始吧。
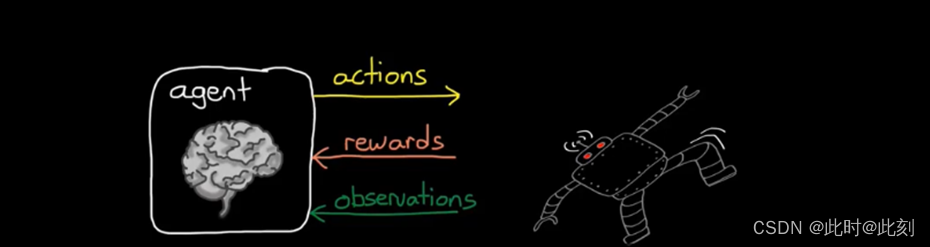
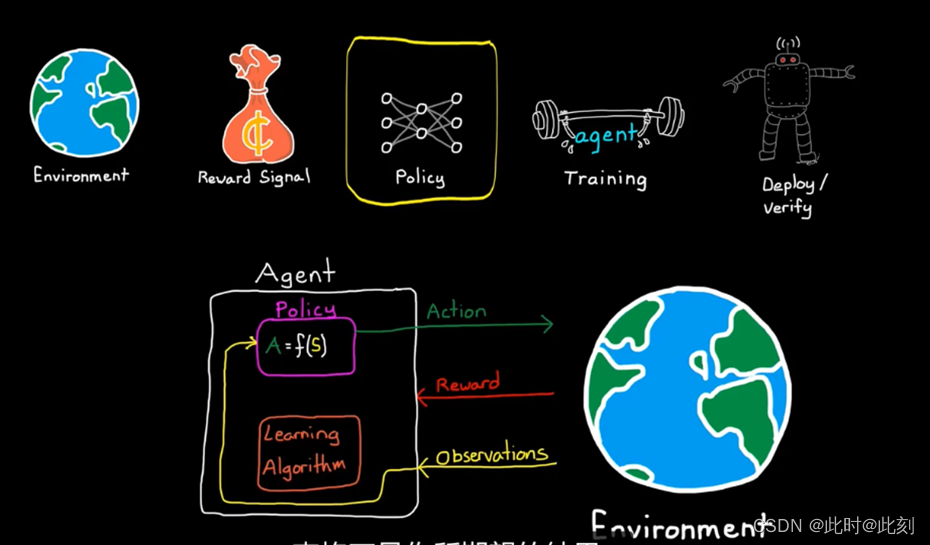
环境是存在于智能体之外的一切。实际上,环境接收智能体发送动作,并产生奖励和观察结果。我认为这个概念一开始有点混乱,特别是来自控制背景,因为我们倾向于把环境看作控制器和被控对象之外的一切; 比如道路缺陷、阵风和其他影响你试图控制的系统的干扰。
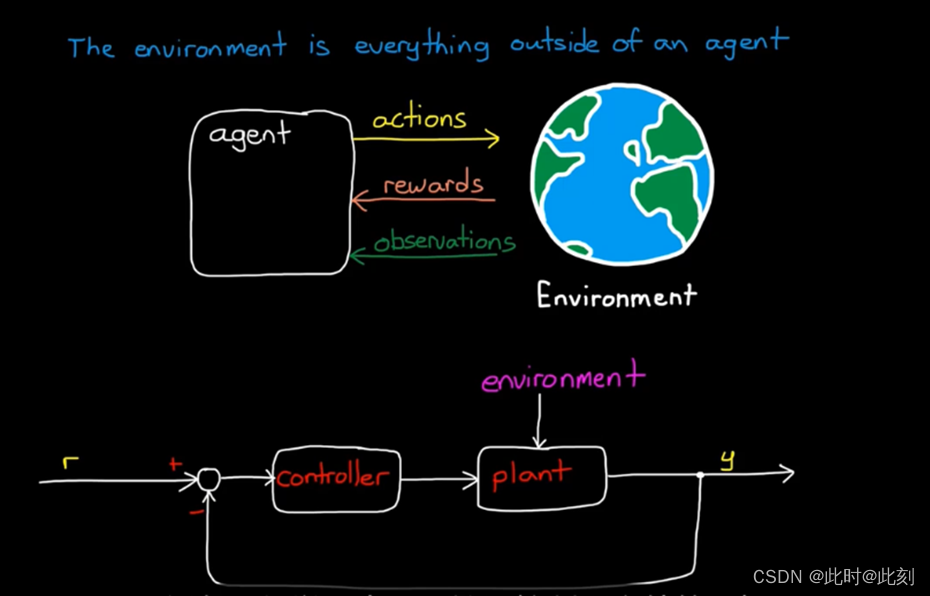
但在强化学习中,环境是控制器之外的一切。所以,这也包括被控对象的动态特性。以行走机器人为例,机器人中大部分都属于环境。智能体只是一个生成动作,并通过学习更新策略的软件部分。可以说,它是机器人的大脑。
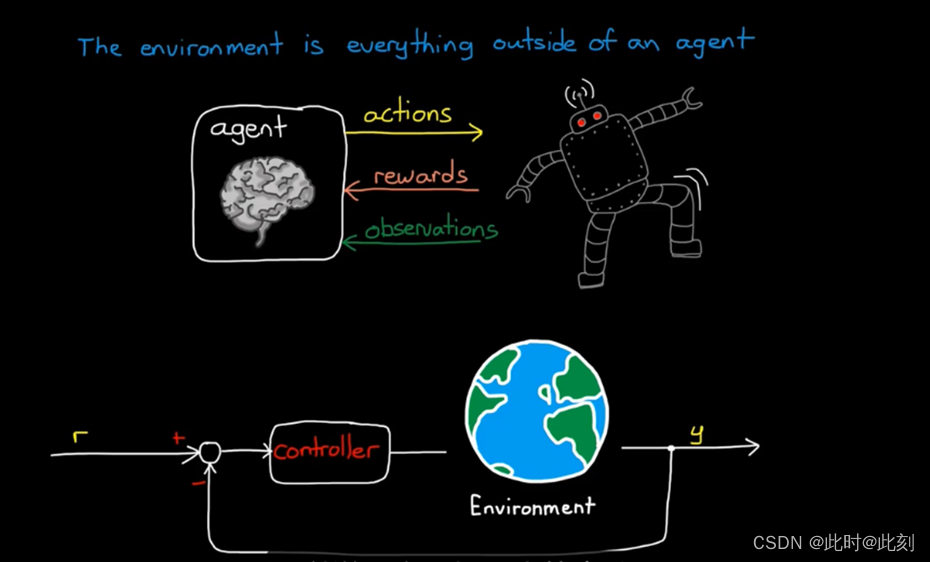
这一区别之所以重要,是因为在强化学习中,智能体根本不需要了解任何有关环境的信息。这被称为无模型RL,它很强大,因为你基本上可以把RL智能体放到任何系统中,假设你已经为策略分配了观察结果、动作和足够的内部状态的访问权限,智能体将自主学习如何获得最大的奖励。这意味着,智能体不需要事先知道关于行走机器人的任何信息。即使在不知道关节如何移动、执行机构有多有力或肢体长度的情况下,它仍然可以找到如何获得奖励的方法。
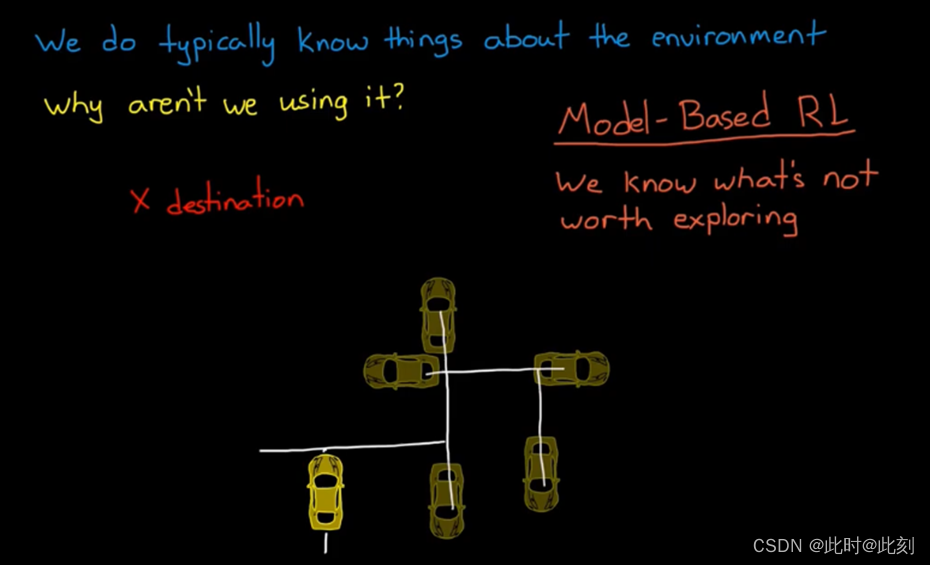
但是作为工程师,我们通常都知道一些关于环境的信息,那么为什么我们要抛弃所有的物理知识,而不去帮助智能体呢? 这看起来很疯狂,是吧? 这就是基于模型的RL的用武之地。在不了解环境的情况下,智能体需要探索状态空间的所有区域,以确定价值函数,这意味着它将在学习过程中,花费一些时间来探索低回报区域。然而,作为设计者,我们往往知道,状态空间中一些不值得探索的部分,因此,我们会提供完整或部分环境模型,为智能体提供了这些信息。
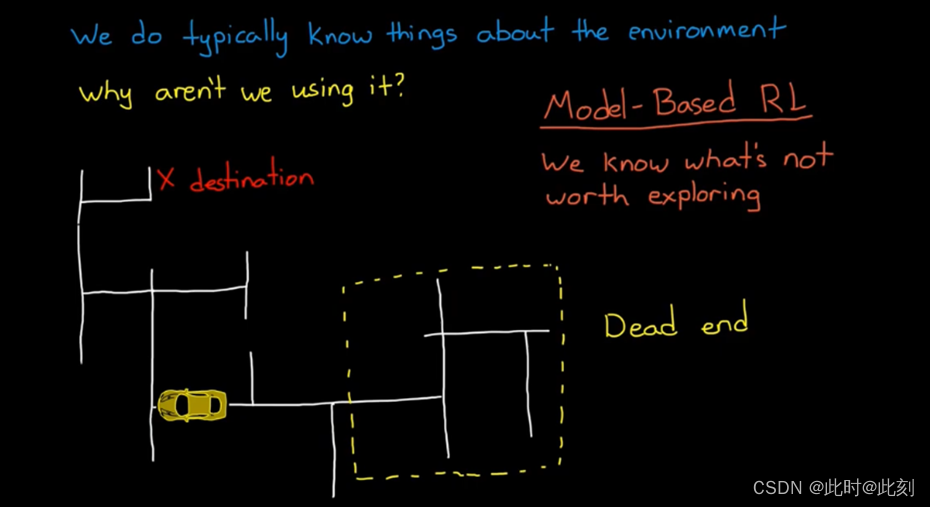
例如,某个智能体试图确定到达目的地的最快路径,这时候它应该向右还是向左走呢? 如果没有模型,智能体将不得不探索整个地图,才能了解最佳行动路线。有了模型,智能体就可以在脑海中探索正确的方向,而不必采取对应的实际行动。
它会发现向右走会进入一个死胡同,然后我们的智能体会向左走。通过这种方式,模型可以通过补偿学习过程,通过避免已知的不理想区域,并探索和学习其他区域来实现。
基于模型的RL是非常强大的,但目前无模型RL非常流行,原因是人们希望用它来解决构造模型困难的问题,比如通过像素级观测量来控制汽车或机器人。而且,由于无模型RL更为常见,我们将在本专栏文章的其余部分重点讨论它。
好的,我们知道,智能体通过与环境的交互来学习,所以我们需要采用某种办法,让智能体与环境进行实际的交互。这可能是物理环境或模拟仿真。例如,对于倒立摆,我们可以通过在真实的倒立摆中运行,让智能体学习如何保持平衡。这可能是一个很好的解决方案,因为硬件很难损坏自己或伤害他人。
然而,对于行走机器人来说,这可能不是一个好主意。你可以想象,如果智能体把机器人和外部世界当作它一无所知的黑盒子,那么不要说学会走路,在机器人学会如何移动双腿之前,它就会摔倒很多次,这不仅会损坏硬件,而且需要一次次重新扶起机器人,也会非常耗时,因此这种方法不可取。
所以,一种有吸引力的替代方法是,在环境的高保真模型中训练智能体,并仿真学习过程,这样做有很多好处。
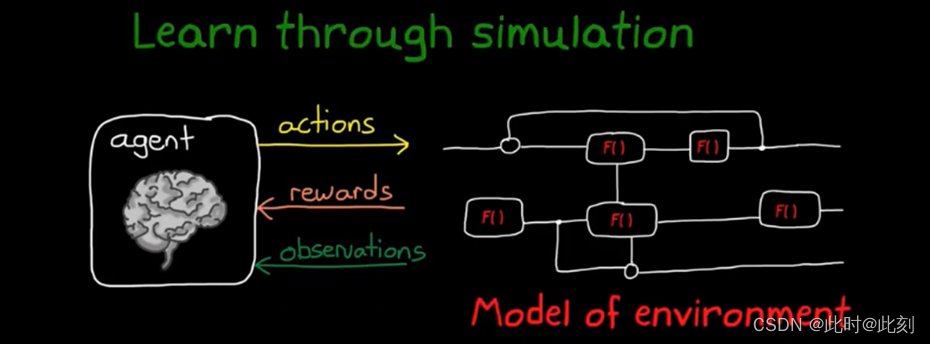
第一个优势来自样本低效的概念。学习是一个过程,需要大量的样本,即大量的试错和修正,通常以百万或千万计。因此,有了仿真,你就能以比现实更快的速度运行学习过程,你还可以启动大量仿真,并行运行。
使用环境模型的另一个优点是,模拟在真实世界中难以实现的测试条件。例如,你可以让行走机器人模拟在冰面等低摩擦的表面上行走,这将帮助机器人在所有的表面都保持直立。

仿真的好处是,对于控制问题,我们通常已经创建好了系统和环境模型,因为传统控制设计一般都需要模型。如果你已经在MATLAB或Simulink中构建了一个模型,那么你可以用RL智能体替换现有的控制器,向环境中添加一个奖励函数,然后开始学习过程。
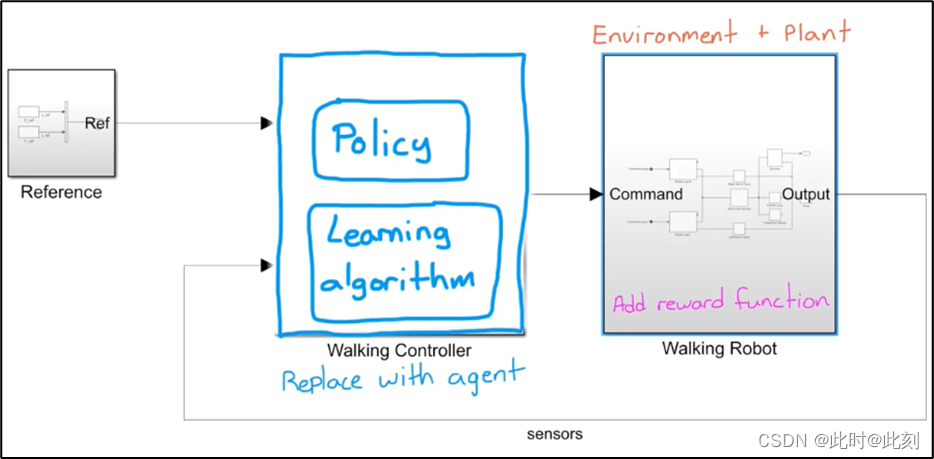
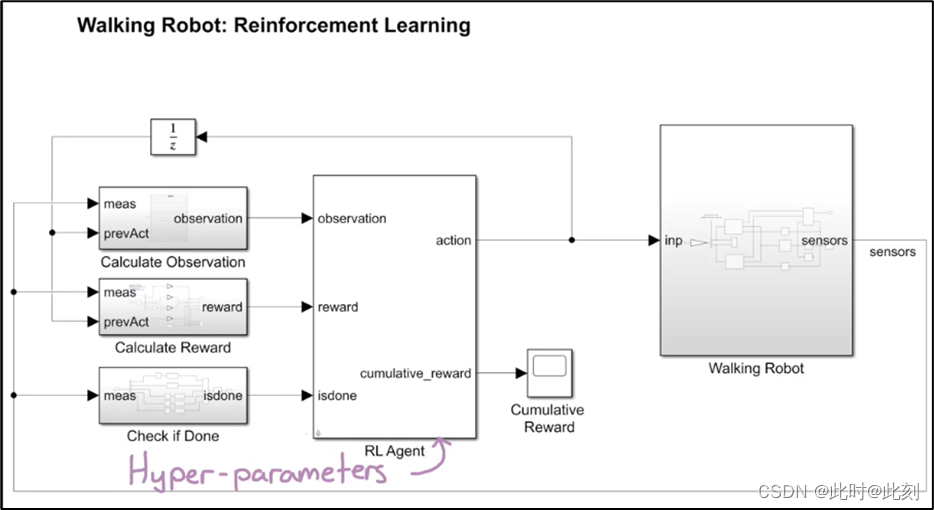
这个模型就是这样做的(如下图所示)。RL Agent是强化学习工具箱中的一个模块,左侧的三个子系统分别生成观测值和奖励,并设置一个标志位中止学习过程。这里的难点是弄清楚,环境建模的程度,包括保留什么和删除什么。不过,这个问题与通过被控对象建模设计控制器相同,因此你可以使用对系统建模的相同直觉来构建RL环境模型。一种方法是在简单的模型上开始训练,找到能让训练成功的超参数的正确组合,然后在后续步骤中,逐渐提高模型的复杂度。超参数是训练算法中可以调节的旋钮,用于设定学习速率和采样时间,我将在今后的文章中详细介绍超参数。
好了,设置好环境之后,下一步是考虑你希望智能体做什么,以及你将如何奖励它实现设定的任务。这类似于LQR中的代价函数,在这个函数中,我们考虑的是效果与努力的权衡。然而,与代价函数为二次型的LQR不同,在RL中,对创建奖励函数没有任何限制。我们可以给予稀疏的奖励,每一步都给予奖励,或者在很长一段时间后,如一段训练完成后才给予奖励。奖励可以从一个非线性函数计算得出,也可以从数千个参数计算得出。实际上,这完全取决于如何有效地训练你的智能体。
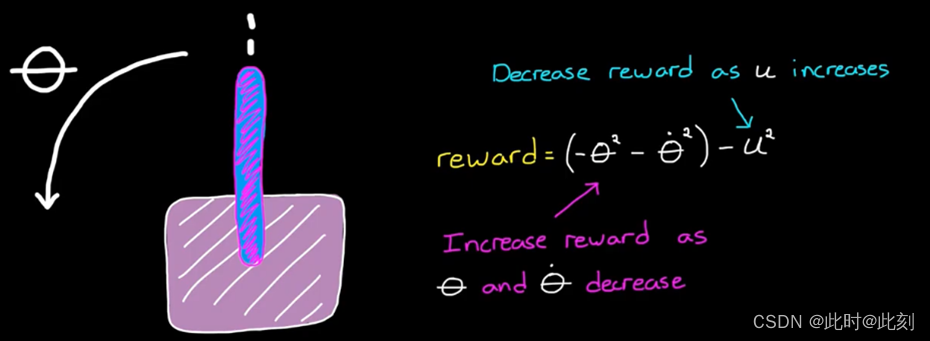
想让倒立摆直立起来吗? 那么,当垂直方向的角度变小时,给智能体更多的奖励。要考虑控制器的输出成本? 那么,随着执行机构输出量的增加,减少奖励。
想鼓励机器人在地面上穿行吗? 然后,当它到达某个遥远的状态时,再给智能体一个奖励。如此说来,创建奖励函数是很容易的。它几乎可以是你能想到的任何函数。
另一方面,创建好的奖励函数是非常非常困难的。不幸的是,并没有简单直接的方法来设计奖励,以保证你的智能体会向你期望的解决方案收敛。我认为这可以归结为两个主要原因:
第一,通常你想激励的目标是在一系列动作之后实现的,这就是稀疏奖励系统。因此,你的智能体将在很长一段时间内跌跌撞撞,而在这个过程中得不到任何奖励。在机器人成功行走10米后才给予奖励,就是这种情况。你的智能体几乎不太可能随机生成到获得稀疏奖励的动作序列。想象一下,如果能生成所有正确的马达指令,让机器人保持直立行走,而不只是在地上笨拙地移动,那该有多幸运!有这种可能,但依赖这种随机的探索,进度将极其缓慢,因此,这是不切实际的。这个稀疏奖励问题,可以通过塑造奖励来改进:提供更小的中间奖励来引导智能体,沿着正确的路径前进。
但是,奖励的塑造也有其自身的一系列问题,这是设计奖励函数很费事的第二个原因。如果你给优化算法提供一个捷径,它会采取捷径! 捷径隐藏在奖励函数中,当你开始塑造奖励时,更是如此。这将导致你的智能体向给定奖励函数的最优解决方案收敛,但这并不是理想的结果。一个简单的例子是,如果机器人从当前位置移动了1米,就给它一个中间奖励。最佳的解决方案可能不是行走1米,而是笨拙地朝奖励的方向摔过去。对于学习算法来说,行走和跌倒都提供的奖励相同,但显然,对于设计者来说,更倾向于其中的一个结果。
我不希望让奖励函数的创建听上去很容易,因为在强化学习中,正确创建奖励函数可能是一个很艰难的任务。不过,希望通过我的简要介绍,你至少能更好地理解你需要注意的一些事情,这可能会让你在创建奖励函数时少一些痛苦。
好了,现在我们有了提供奖励的环境,我们就可以开始研究智能体本身了。智能体由策略和学习算法组成,这两者是紧密交织在一起的。许多学习算法需要特定的策略结构,选择算法取决于环境的性质。我们将在下篇文章中讨论这个问题,但是在我结束这篇文章之前,我想介绍一下这个主题,并让我们思考,策略中的参数和逻辑应该如何表示。请记住,策略是一个用于接收状态观测值并输出动作的函数,因此实际上,任何具有输入和输出关系的函数都可以。
按照这种思路,我们可以使用一个简单的表格来表示策略。表格正是你所期望的结果。它是一个数值数组,你可以将输入作为查找地址,并输出相应的值。例如,Q函数是一个将状态和动作映射到价值的表格。因此,如果给定状态S,应采取的策略是,查找该状态中所有可能动作的值,然后选择价值最高的动作。
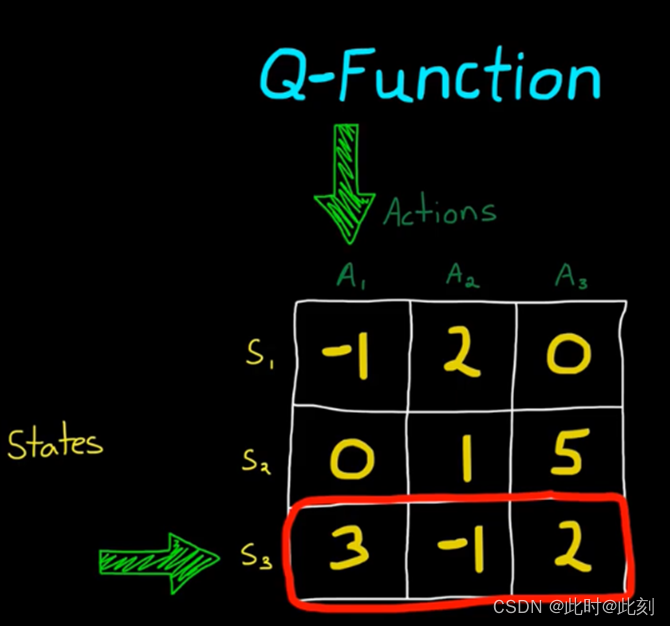
使用Q函数训练智能体,将在一段时间内,更新每个状态下所有动作及其价值。

当动作-值对的数量变得非常大或变得无限大时,这种表示方法就会崩溃。这就是所谓的维度灾难。想象一下我们的倒立摆。摆臂的状态可以是从-PI到Pl的任何角度,你可以采取的行动是,从负极限到正极限的任何电机扭矩。试图在一个表格中捕获所有这些状态是不可行的。现在,我们可以用一个连续函数来表示状态-动作空间的连续性质。但是,如果要设置这个函数供我们学习正确的参数,就需要提前知道函数的结构,这对于高自由度系统或非线性系统来说是很困难的。因此,尝试使用通用函数近似器来表示策略是有意义的。它可以处理连续的状态-动作空间,而不需要提前设置结构。我们可以用深度神经网络实现了这一点。
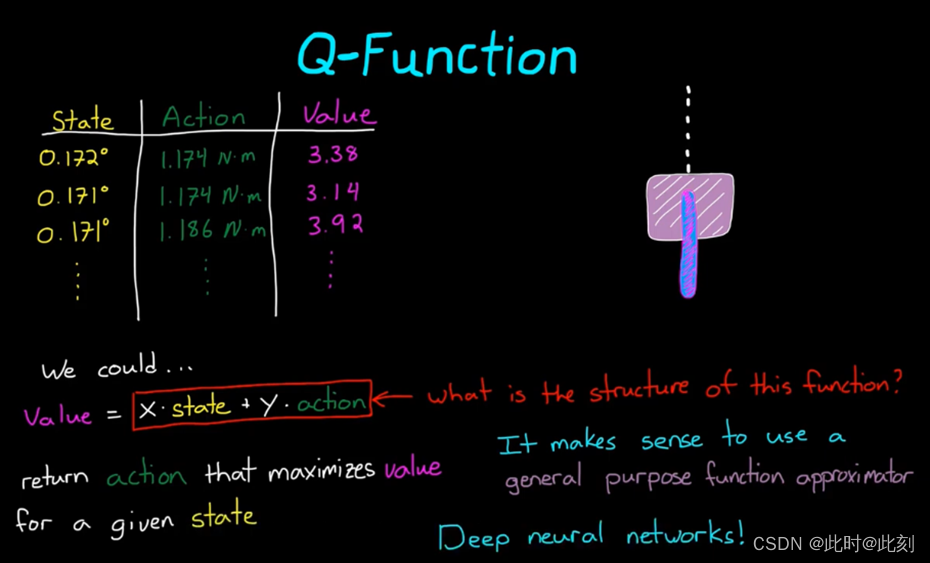
以上是本篇文章的内容,我们将在下篇文章中继续讨论。
PS:文章内容的视频链接如下:


















 2704
2704

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











